探秘AlphaStar:星际争霸人工智能
(声明:此文已发表于《爱上机器人》2019年2月刊,转载请联系作者)
前言
近十年来,人工智能的研究人员们一直在尝试将游戏用作测试和评估人工智能系统的方法。得益于算法的发展和计算能力的增长, 研究人员们开始寻求攻克越来越复杂的游戏,这些游戏拥有可以用来解决科学和现实问题所需的诸多要素。从最初的Atari游戏(乒乓球、打砖块),到后来的围棋和象棋,再到即时战略游戏星际争霸系列,人类正在一步一步地向通用人工智能迈进。
AlphaStar的诞生
2017年5月28日,一场围棋世纪大战落下帷幕,Deepmind公司开发的人工智能围棋系统AlphaGo以3:0的比分完胜世界排名第一的人类棋手柯洁。至此,人工智能终于攻破了千百年来人类智慧的最后防线——被称为“千古无重局”的围棋。随后,Deepmind开始将重心放在即时战略游戏星际争霸2上,试图攻克这一更大的难题。

柯洁 vs AlphaGo
早在2011年3月,Deepmind的创始人Demis Hassabis就提出了AI挑战星际争霸的目标,Deepmind的研究团队也开始了相关研究。无奈受限于当时的技术,这一目标一直没有实现。
2017年8月,Deepmind与星际争霸系列的制作者暴雪娱乐公司合作,联合发布了他们一直在使用的星际争霸2人工智能研究环境SC2LE,帮助广大研究人员和爱好者进行研究。除此之外,暴雪还宣布挑选出十万份匿名玩家的比赛录像进行数据支撑。
2018年6月,Deepmind公布了研究的最新进展,它们用关系性深度强化学习,在星际争霸2的六个模拟小游戏(移动、采矿、建造等)中达到当前最优水平。
终于,到了2019年1月25日,AlphaStar首次公开亮相。这个名字的由来与AlphaGo相同:Alpha是希腊语中的第一个字母,有起源、开端的意思;Star则是星际争霸的英文名StarCraft的第一个字母。据Deepmind介绍,AlphaStar使用的种族为神族(Protoss),在此前以5:0的战绩击败了Team Liquid战队的职业星际争霸2选手TLO。在训练了两周后,AlphaStar再次挑战WCS世界锦标赛亚军——同样来自Team Liquid战队的Mana。不同与TLO,Mana可以称的上是当今最强的欧洲神族之一,并且不久前在WCS世界锦标赛上获得亚军。面对如此强大的对手,最新的AlphaStar的表现依旧让人眼前一亮。又是5:0,AlphaStar的表现超过了Deepmind的研究团队的预期。在回顾了全部10场比赛的录像后,Mana与AlphaStar在现场进行了一场比赛。不过这次的AlphaStar与之前有很大不同,它在视野感知上更接近与人类。也就是说,需要自己控制视角而无法直接读取地图上所有可见内容。最终,Mana击败AlphaStar,捍卫了人类的荣誉。
AlphaStar比赛分析

对战信息
这10场比赛全部是星际争霸2虚空之遗版本,双方的种族都是星灵(Protoss,又称神族),地图是汇龙岛-天梯版(Catalyst LE)。星际争霸中一共3个种族:人类(Terran)、星灵(Protoss)、异虫(Zerg)。目前,AlphaStar仅学习了星灵vs星灵这一种对抗,因为这一种对抗的战术博弈非常多变,可以更好的训练AI的决策能力。
在与TLO的揭幕战之中,AlphaStar使用了人类比赛中最常规的开局,双方前期的发展基本完全相同,但是AlphaStar的建筑建造位置略有瑕疵。但是这些都无伤大雅。紧接着,AlphaStar建造了4个兵营组织快速进攻,在展现了非常精彩的操作后战胜了对手,仅用时7分钟。后续的四场比赛中,AlphaStar连续展现了多种战术,比如:自爆球、闪烁追猎等。而TLO显然已经被AlphaStar打乱了阵脚,四场比赛也是一败涂地。在战术博弈和操作上,AlphaStar都是完全碾压了对手。
可以说AlphaStar的首次亮相的表现远超在场的所有人的预期,5场比赛赢得干脆利落,丝毫不给对手任何机会。这场对局使我们第一次正面了解了AlphaStar,虽然它轻松战胜了对手,但是由于训练时间太短,所以仍然会做出一些让人无法理解的奇怪操作,在专业玩家眼里看来还是破绽百出。AlphaStar学习了上万场人类比赛的录像,却还没有掌握建筑的建造位置,经常会出现被自己的建筑卡住的情况。在第四场比赛中生产了过多的反隐形单位却没有分散使用造成资源浪费、单矿运营农民数量达到上限时建造了额外的农民等细节暴露它目前的实力并不是很强。
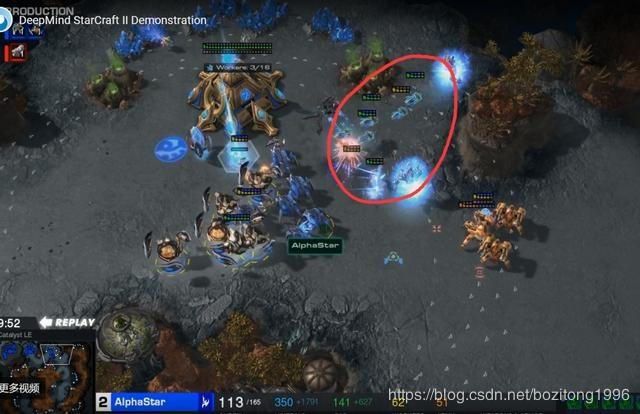
5个“观察者“在一片战场上
TLO虽然是一名职业选手,但是他并不是职业神族选手,他的主族是异虫。所以,在又训练了两周后,AlphaStar与职业神族选手Mana展开了较量。
AlphaStar在闭关修炼之后已然脱胎换骨,弥补了之前很多细节上的不足。一盘野外造兵营的极限进攻战术,把开矿运营的Mana打得措手不及,5分钟兵不血刃拿下第一局。第二盘AlphaStar使用了人类比赛中非常少见的凤凰+追猎者组合,依靠犀利的操作在两三波交换上占据优势,从而获得胜利。后续的三盘中,AlphaStar使用的战术都不是人类比赛的常规战术,它使用追猎者作为核心兵种,配合其他兵种辅助,都取得不错的成效,打得世界亚军Mana苦笑连连。这就是AlphaStar学习出的自己对游戏的独特理解。
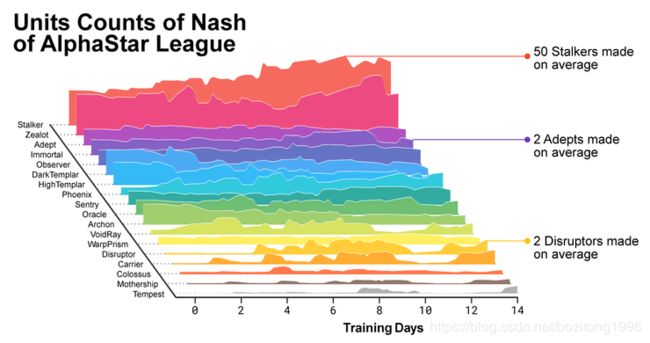
平均每场比赛建造50个追猎者
最后的现场对决中,在AlphaStar的强势期,Mana采用了运输机带不朽者空投骚扰战术,本在进攻途中AlphaStar竟然撤回了所有部队进行回防。Mana见状立刻打起了游击战,敌退我进,敌进我退。几次反复下来,由于不懂得分兵防守,AlphaStar的部队被困在基地无法出门,经济也受到打击。最终Mana在一个有利地形包夹了AlphaStar的主力部队,获得了胜利。
由此我们不难看出,尽管AlphaStar的策略已经趋于长期优化,但似乎仍然会在一定程度上陷入局部最优,被人类发现其固定模式,落入圈套。
星际争霸AI背景
总比分10:1,这一胜利的重要程度不亚于当年的AlphaGo。同围棋一样,星际争霸也属于零和博弈问题。但是星际争霸的非完全信息博弈以及更庞大的状态空间和动作空间等特点,才使它真正成为了人工智能的又一大挑战。
众所周知,围棋的棋盘上可能出现的情况数非常之多,所以被称为“千古无重局”,其状态空间复杂度多达1048![]() 。每一步可以选择的落点(即动作空间)有大约300个。这一数字看上去已经十分巨大,但是还远不及即时战略游戏,尤其是星际争霸。它的状态空间已经不能用数字描述,可以说是”无穷大“,动作空间更是达到了指数级别。而所谓非完全信息博弈,就是指不能完全获取所有的游戏信息。这一点在即时战略游戏中以“战争迷雾”的形式普遍存在。游戏里,你只能感知获取你周围环境的信息,在你感知范围之外的一切都被黑雾所笼罩。在围棋中,整个棋盘的信息和对手的每一次落子都会被我方感知,智能体就能通过这些信息计算出最佳策略。在星际争霸2中,我们能获取的信息十分有限,唯一的办法是通过侦察手段获得对手的情报,即便如此智能体也无法第一时间获知对手的每一步动作,这会极大地影响智能体的判断和决策。Deepmind的研究团队曾公开表示,对于星际争霸2的AI来说,非完全信息博弈是最大的挑战。其实,这一点与我们的现实生活十分相似:我们可以把现实生活看成是一场即时战略游戏,从读书、找工作,到参加各种比赛,我们所能获取到的信息永远只是我们需要知道的决策信息的一小部分。这场游戏中我们的对手,也就是其他人,永远在迷雾中行动。因此,我们要面对的最大挑着就是这永恒的不确定性。不论我们拥有多么强大的能力,我们依然生活在充满不确定性的迷雾里,这就要求我们不能过度渴望精确的预测,要学会根据现有的信息进行决策。
。每一步可以选择的落点(即动作空间)有大约300个。这一数字看上去已经十分巨大,但是还远不及即时战略游戏,尤其是星际争霸。它的状态空间已经不能用数字描述,可以说是”无穷大“,动作空间更是达到了指数级别。而所谓非完全信息博弈,就是指不能完全获取所有的游戏信息。这一点在即时战略游戏中以“战争迷雾”的形式普遍存在。游戏里,你只能感知获取你周围环境的信息,在你感知范围之外的一切都被黑雾所笼罩。在围棋中,整个棋盘的信息和对手的每一次落子都会被我方感知,智能体就能通过这些信息计算出最佳策略。在星际争霸2中,我们能获取的信息十分有限,唯一的办法是通过侦察手段获得对手的情报,即便如此智能体也无法第一时间获知对手的每一步动作,这会极大地影响智能体的判断和决策。Deepmind的研究团队曾公开表示,对于星际争霸2的AI来说,非完全信息博弈是最大的挑战。其实,这一点与我们的现实生活十分相似:我们可以把现实生活看成是一场即时战略游戏,从读书、找工作,到参加各种比赛,我们所能获取到的信息永远只是我们需要知道的决策信息的一小部分。这场游戏中我们的对手,也就是其他人,永远在迷雾中行动。因此,我们要面对的最大挑着就是这永恒的不确定性。不论我们拥有多么强大的能力,我们依然生活在充满不确定性的迷雾里,这就要求我们不能过度渴望精确的预测,要学会根据现有的信息进行决策。
在AlphaStar面世之前,就已经有一些科研团队发布过一些成熟的AI,其中包括笔者所在的中科院自动化所、FaceBook、腾讯AI Lab、加州大学伯克利分校、南京大学等。在不久前,纪念大学的ai团队举办了世界上最大的星际争霸AI大赛AIIDE,采用的版本是星际争霸母巢之战,冠军由三星开发的SAIDA获得。SAIDA是一个基于规则的AI,没有使用任何机器学习技术。换句话说,它的一切决策都是人类根据经验写好的程序执行的,而FaceBook开发的基于机器学习的CherryPi成绩并不理想。究其原因,大概是因为机器学习对理论、工程、计算能力的要求都相当高,想要在星际争霸上超越人类长时间积累的经验绝非易事。但是,星际争霸是个博弈游戏,己方的决策应该建立在对手的决策上,这种基于规则的AI系统一旦被人熟知它的套路,就会变得不堪一击。与之相比,AlphaStar就相当于一个会思考的机器人,它已经有了真正的通用人工智能的影子,即:自主学习、举一反三的能力。这其中究竟包含了哪些技术呢?下面为大家一一解读。
技术解读
Deepmind研究团队在他们发表的论文中将训练AlphaStar的算法称为关系性深度强化学习,其本质就是融合了监督学习和强化学习以及多体博弈的方法。
监督学习是在训练过程中,我们使用带有标记的数据来告诉AI哪些是正确的、哪些是错误的。以人像检测为例,我们在输入一张照片的同时也要输入这张照片是否有人像。这样训练完成后的AI可以自行检测任何照片中的人像。在这种情况下,我们进行的通常是一个结果为yes or no的训练,但事实是,监督学习也可以用于输出一组值,而不仅仅是0或1。例如,我们可以训练一个模型,用它来输出一个人偿还信用卡贷款的概率,那么在这种情况下,输出值就是0到100之间的任意值。当前最火的深度学习也属于监督学习的范畴,它使用深度神经网络去近似这个判定过程。神经网络中包含多个神经元,每一个神经元通过激活函数决定是否允许通过。所有被激活的神经元会将它计算后的数据传递给下一层直到输出层,然后将这个输出与我们给出的标记对比,通过误差函数计算出误差反馈给网络,利用这个误差从后往前逐层修改神经元的权重。这个过程我们通常称之为反向传播。通过这个训练过程,神经网络模型就学到了判断能力,从而帮助我们进行决策。目前为止,监督学习已经广泛应用在语音识别,车辆检测等诸多领域。

比赛中AlphaStar如何做出下一步决策
从这张图上我们可以清晰地看到,AlphaStar的各种操作是从神经网络的原始观察接口输入系统(左下1),然后神经网络开始激活处理输入(左下2),最终输出当前决策以及决策目标位置。与此同时计算自己的胜率。
监督学习虽然已经拥有很多成熟的理论和算法,但是它必须使用有标记的数据才可以训练。得到一个标注好的数据集可能会很难亦或是很昂贵,所以你需要确保预测的价值能够证明获得标记数据的成本是值得的。强化学习不需要带标签的数据,而是拥有一个目标和评价是否接近目标的回报函数。强化学习的思想更倾向于训练AI使他学会如何在一场游戏中得到最大回报(通常是取得胜利)。也就是说,强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。这个反馈通常是具有延迟的,就像在围棋和星际争霸中,我们当前的一步动作并不能马上带来回报,而是在一段时间后才发挥作用,我们称之为长期回报。为了获得准确的长期回报,AI必须经过很多次尝试,所以强化学习对算法和算力有着很大的要求,通常需要很长时间来训练。
在创造AlphaStar时,Deepmind团队首先从人类比赛的录像中提取数据,利用监督学习训练了一个神经网络,再基于强化学习让AlphaStar进行对战并自我提升。这就是AlphaStar的整体框架。

MMR分布图
上图中的每一个点代表AlphaStar的一个训练完成的版本,MMR是评价玩家实力的标准。通常业余选手的MMR值在0到5500范围内呈正态分布。5500以上就是业余顶尖选手和职业选手水准。TLO和Mana的MMR值分别在5600和7000左右。图中左边的灰色部分是监督学习与训练出的版本,可以看到最高的也不到5000MMR。右边是强化学习的自我博弈提升阶段,训练出的最强版本的AlphaStar的MMR有7500左右,并且我们可以看到强化学习训练的时间长达2周。之前的AlphaGo中,自我对弈阶段的对手都是由所有之前的训练过程中出现的表现最好的版本生成的,也就是说每一时刻都存在一个最好的版本,并不断寻找比他更好的版本进行替换。但对于星际争霸,Deepmind的研究团队认为不同的优秀策略之间是相互克制的,事实也是如此,没有哪一种策略是可以完胜其他所有策略的。所以这次他们的做法是建立了一个“AlphaStar”联赛,分别更新和记录多个不同版本的AI。在这个过程里,可以做到不会把某些个体学会的成果轻易遗忘,而是在多体博弈中有效运用所有已经学会的策略并选择他写胜率较高的保留。最终的训练结果是一个达到纳什均衡状态的最强AI组合。

AlphaStar联赛
如上图所示,AlphaStar每轮都会在数个比较强的版本中进行分支,分支前的版本会被固定参数保留下来,一直参与后续的多轮自我对战。这样在不断提升AI水平的前提下又保留了足够的多样性。
未来展望
星际争霸是个足够复杂且具有代表性的任务,用来解决这个任务的技术也可以用在其他的复杂问题上。AlphaStar让我们看到了AI在非完全信息博弈这个与真实世界的情况非常接近的背景里所取得的巨大进步。也许在不久的将来,AI就能学会指挥一场现实世界的战争。但我们也无需恐慌,AlphaStar真正的贡献是为我们带来的是一场AI革命,那些新的AI技术会很快应用在各行各业,提高我们的生活质量。
薄紫彤 于中科院软件所