Mask Scoring R-CNN论文阅读
为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便,本文仅将自己感兴趣部分简单翻译。排版对手机端不友好。感谢评论好心人给的指正,希望可以一块学习。
为提高实例分割的性能,该论文寻找了一个新的方向——对生成的掩模进行评分。该论文基于Mask R-CNN,增加了一个Mask IoU head,它将mask head的输出和分类分数进行相乘最为最终的分数。
附上一位指路人对于Mask score的认识:
Mask R-CNN中对于mask head输出的K(类别)个mask,选择哪个mask作为最终的输出是取决于分类支路置信度最高的类别,但是因为分类置信度与mask分割是相关性很低的,这样选择出来的mask并不是最好的mask,所以会导致mask支路的AP值因此而下降,所以maskscoring_rcnn才想让分类置信度与mask质量之间能有高的相关性,这样一来分类置信度高的那类mask确实质量也会高,所以AP值也会增加。分类置信度并不是mask的评分,只是选择哪一个mask的依据,偷换一下概念,就说之前使用 分类置信度当做mask的质量评分了。
原文地址:Mask Scoring R-CNN
代码地址:Python-MS R-CNN
论文摘要
让深度网络自己评测自己的性能是一个比较重要的工作。在实例分割任务中,大多数的工作采用了使用实例分类的置信度作为Mask质量分数。然而,用于评价掩模重合度的IoU和分类分数并不能很好的契合。本文提出的Mask Scoring R-CNN为了解决这个不匹配的问题,提出了一个结合实例特征和预测掩模产生掩模IoU的网络块。
掩模评分机制对掩模质量和掩模分数的不匹配进行了校正,该机制通过在COCO平均准确度(AP)评估期间确定更准确的掩模预测优先级,以获得更高的掩模预测准确度。
论文内容
1、Introduction
深度网络的使用极大推动了计算机视觉的发展,现在已经应用到了分类、检测和语义分割任务上。从计算机视觉的发展历程可以看到,从最开始的图像级别[1]的分类到物体框级别[2]的分类,然后再到像素级别[3]的分类,进而到实例级别[4]的预测。更细粒度的预测不仅需要更准确的标签和更好的设计网络。
实例分割作为物体检测的后续研究方向,将粗糙的物体框细化到了像素级别。同样的,对实例分割的性能进行评价也是同样重要的,大部分的评价标准都是根据假设分数进行定义的,更好的性能来源于更精确的分数。例如,常用的评价标准有精准度召回曲线和平均精准度(AP)。
然而,在当前的大多数实例分割方法中,例如Mask R-CNN和MaskLab,实例掩模的 分数分享了分类的分数。但是这么做是非常不恰当的,因为这个分数仅仅是关注了语义级别的问题,并没有关注实例本身。两者的不匹配情况如图1所示:

图1 用于描述不匹配问题的实例
从图中可以看到,如果使用物体框位置准确度和分类的精确度来表示掩模精确度,将会降低掩模的精度。
之前的实例分割专注于获得精确的实例位置和掩模,但是该论文目标是对掩模进行打分,即对每一个掩模产生了一个分数,简称掩模分数。
受实例分割中的交并比(IoU)的影响,该论文提出了一种将该交并比与分类分数相乘,这样得到的分数对语义类别和实例掩模均很敏感。在该论文中, IoU称为MaskIoU。
该论文的主要贡献是在Mask R-CNN网络中加入了一个MaskIoU head,这个head将Mask Head的输出和感兴趣区域的特征作为输入,并运用一个简单的回归损失进行训练。
综上所述,这篇文章的主要贡献可以总结为以下两点:
- 是第一个解决实例分割评分的框架,为提高实例分割性能提供了一个新的方向。通过考虑实例掩模的完整性,可以在分类分数很高的情况下对实例掩模进行惩罚。
- 提出的MaskIoU head非常简单且有效。
2、Related Work
A、Instance Segmentation
当前主流的实例分割方法可以简单的分为两种:基于检测的和基于分割的。基于检测的方法使用当前顶尖的检测器得到感兴趣区域内的所有实例,然后对每一个区域进行分割。然而这种基于检测的方法有一个缺点,那就是掩模质量仅仅由分类分数所定。(之前的论文中说的是物体框重叠问题,应该是一个问题:在已经分类好的物体框中可能存在多个物体,对于每个实例无法得到准确的掩模)。
基于分割的方法首先对每个像素进行预测标记,然后对它们再进行分组。于是这类方法的聚类方法将是十分重要的,还有一些利用边缘信息和利用水域分割的方法。近来,也有一些工作利用学习机制进行学习嵌入,这些方法对每一个像素学习一个嵌入,以保证每个实例中的所有像素具有相同的嵌入,不过聚类算法的性能直接决定了结果的好坏。同样的,这些方法都没有对掩模的质量进行直接评分,而是利用了像素级别的分类分数。
总的来说,以上两种方法都没有考虑掩模分数和掩模质量之间的不匹配问题。但是实例分割的最终目的是得到较高质量的掩模,通过分类的分数评价掩模是一个治标不治本的方法。
B、Detection Score Correction
已经有较多的方法关注于纠正检测框的分类分数,本文基于之前的基础,将mask IoU作为一个回归的任务。因为之前的工作仅仅关注于物体框级别的检测,不适用于实例分割。该论文提出的Mask IoU head面向的是整个实例的掩模,所以最终的掩模分数可以直接反应掩模的质量。
3、Method
3.1、Motivation
在Mask R-CNN结构中,实例分割的分数主要由分类分数所决定。但是由于背景聚类以及重叠等问题的存在,会导致分类分数很高,但是掩模结果并不好。具体效果如图1所示,图中为了量化对比,将从Mask R-CNN得到的掩模分数与该论文得到MaskIoU进行了对比。本文对软非极大值抑制之后,选择了检测假设,考虑Mask IoU和分类分数大于0.5时的实例分关系。如图2所示,可以看到两个不同的方法中掩模分数和Mask IoU之间的关系:

图2 Mask R-CNN和Mask Scoring R-CNN中Mask score和Mask IoU的关系
从图中可以看到,Mask R-CNN中两者之间的关系并不明显,而Mask Scoring R-CNN的两者之间的关系较为明显。(说明Mask Scoring R-CNN计算分数时考虑了Mask IoU)。
让论文产生对MaskIoU进行矫正的思想是:让在大多数的实例分割的评价标准里,例如COCO,将mask分数较高但是掩模交并比较低视为一种病态。那么,自然就需要评价这个检测的结果是否可信[5]。
该文的Mask Scoring R-CNN是在Mask R-CNN的基础上增加了一个额外的MaskIoU Head的模块,这个模块用于矫正MaskIoU和Mask分数。
3.2、Details
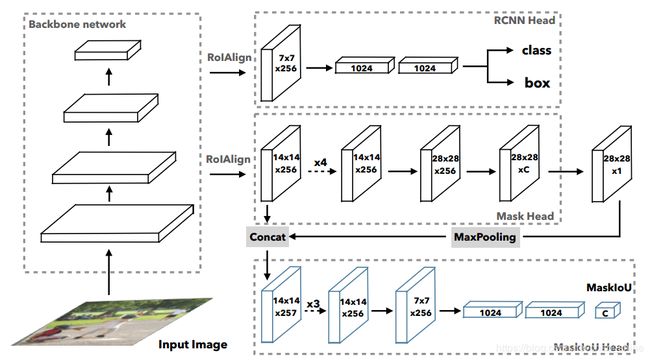
图3 Mask Scoring R-CNN的实现框架
图3为整个Mask Scoring R-CNN的结构图,从图中可以看到只是在Mask R-CNN的框架上增加了一个MaskIoU Head,将生成的掩模和得到的特征作为输入,然后对得到的掩模和实际的掩模进行对比。
⑴ Mask R-CNN:这里对Mask R-CNN进行一个简单的介绍。在Faster R-CNN之后,又增加了两步。第一个就是区域推荐,用于对每个物体产生物体框。第二个就是R-CNN块,用于提取特征并进行分类、检测和生成掩模。
⑵ Mask Scoring:假设是预测掩模的分数,理想的![]() 应该和像素级别的IoU相等,这个IoU是预测的掩模和实际的掩模之间产生的,称为MaskIoU。并且理想的
应该和像素级别的IoU相等,这个IoU是预测的掩模和实际的掩模之间产生的,称为MaskIoU。并且理想的![]() 对真实的实例是正值,对于其他的实例为0。于是产生了两个任务:正确实例的掩模生成和背景物体MaskIoU的生成。
对真实的实例是正值,对于其他的实例为0。于是产生了两个任务:正确实例的掩模生成和背景物体MaskIoU的生成。
然而上述的两个任务很难用一个目标函数限定,同时为了简便起见,将掩模评分任务分成了两个小部分:掩模分类和IoU的回归,定义有。其中,和分别代表了分类分数和IoU的分数。的产生是由R-CNN这一步产生的,目标是将物体进行分类。是该论文的研究重点,详细阐述如下。
⑶ MaskIoU Head:这个Head主要关注的是上面的,将从RoIAlign层提取到的特征和预测到的掩模作为输入。从图3中可以看到,因为掩模的尺寸为![]() 的,与特征层的的大小不一致,文中中使用了一个步长为2,核的大小为2的最大池化层使得尺寸相同。在实验过程中,仅对真实类做了MaskIoU的回归,而没有对所有的类进行回归,在测试阶段,是对预测的类进行的回归。
的,与特征层的的大小不一致,文中中使用了一个步长为2,核的大小为2的最大池化层使得尺寸相同。在实验过程中,仅对真实类做了MaskIoU的回归,而没有对所有的类进行回归,在测试阶段,是对预测的类进行的回归。
细节上,这个MaskIoU Head包括了4个卷积层核3个全连接层。这四个卷积层紧接在Mask Head后,将核大小设置为3,个数为256。对这三个全连接层,紧跟在了R-CNN区域,前两个全连接层的输出个数为1024,最后一个为类别的个数。
⑷ Training:为了训练MaskIoU head,论文使用RPN产生的推荐作为训练的样本。这个训练的样例需要推荐区域和实际物体的IoU大于0.5,和Mask R-CNN的Mask head要求是相同的。为了得到训练样本的回归目标,首先得到了目标类的预测掩模,并对这个掩模设置一个0.5的阈值实现二值化。然后利用二值掩模的和对应真实实例的的MaskIoU作为MaskIoU的目标,损失函数利用,损失的权重设置为1。最后将这个MaskIoU与Mask R-CNN进行整合,得到现在的Mask Scoring R-CNN,实现端到端的训练。
⑸ Inference:在推理阶段,仅使用MaskIoU Head来矫正由R-CNN得到的分类分数。假设通过R-CNN得到N个物体框,通过soft-NMS选出评分的前k个物体框。然后将这k个物体框导入Mask Head,然后得到多类的掩模,并通过这些掩模进行预测MaskIoU。最终得到矫正的分数,是将上述的掩模分数与分类分数相乘,得到最终的掩模分数。
4、实验
4.1、实验细节
在对比试验中,使用了基于了FPN网络的ResNet-18。在使用其他评价标准时,使用了基于Faster R-CNN/FPN/DCN+FPN的ResNet-18/50/101。对于ResNet-18,输入的图像重采样为像素。与标准的FPN不同,该论文在ResNet-18中,对特征提取和RPN推荐仅使用了C4和C5。对于ResNet-50/101,输入的图片重采样为![]() 像素。
像素。
实验中对网络进行了18轮的训练,在14轮和17轮之后学习率乘上0.1。随机梯度下降的动量设置为0.9,实验中使用了软非极大值抑制,并获取每个图的前100个分数检测。
4.2、定量结果
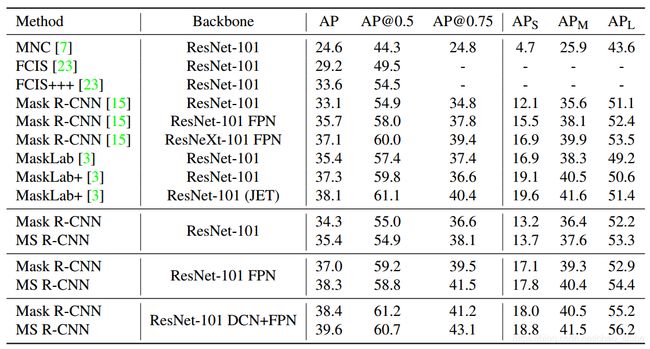
表1 COCO 2017验证集上的结果

上表是与Mask R-CNN进行对比的结果,其中代表实例分割的结果,代表检测的分数。其中没有对号的是Mask R-CNN,有对号的是本文的Mask Scoring R-CNN,可以看到实例分割的在一定基础上得到了提升。并且同样表示MS R-CNN对于框架的选择并 不敏感,都可以较稳定的对Mask R-CNN进行提升。
表2 COCO 2017验证集上的对比实验

可以看到,不仅没有降低检测的分数,同时还提升了实例分割的结果。
同样的,为了对比不同方法实现实例分割的效果,在COCO测试集上得到了如下的实验结果。从表中可以清楚的看到,MS R-CNN在不同的网络架构上都要优于Mask R-CNN的性能。
表3 不同方法在测试集上的效果
4.3、对比实验
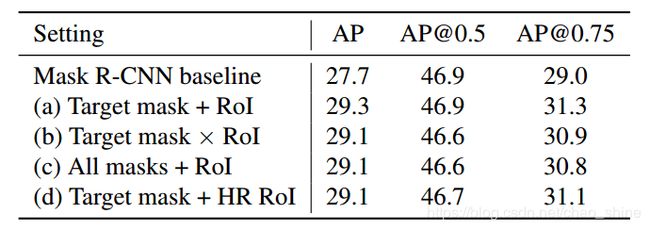
A、MaskIoU head输入的选择
这部分主体是Mask Head产生的掩模和感兴趣的特征。对于如何将这两种进行结合,给出了四种不同的选择,如图4所示:

图4 不同的结合风格
⑴ 目标掩模与感兴趣特征相加:从所有掩模中经过选择后送入最大池化层,然后将输出的结果与感兴趣区域特征相加。
⑵ 目标掩模与感兴趣特征相乘:除了结合为乘法,其他与上述一样。
⑶ 所有掩模与感兴趣特征相加:将所有的掩模经过最大池化,然后与感兴趣区域特征相加。
⑷ 所有掩模与原始高像素感兴趣特征相加:将所有的掩模经过最大池化,然后与原始感兴趣区域特征相加。
经过实验,如表4所示,可以看到MaskIoU Head对不同的聚合方法具有较高的鲁棒性,但是相对来说第一种选择的情况比较的好,文中采用了该方法。
表4 四种结合方法的结果
B、目标函数的选择
⑴ 学习目标类别的MaskIoU,忽略中的其他类别,这也是本文中的默认训练目标。
⑵ 学习所有类别的MaskIoU。如果类别未出现在RoI中,则其目标MaskIoU设置为0。此设置表示仅使用回归来预测MaskIoU,但要求不存在不相关的类别。
⑶ 学习所有正类别的MaskIoU,其中正类别表示该类别出现在RoI区域,并忽略推荐的其余类别。
表5 三种目标函数的结果

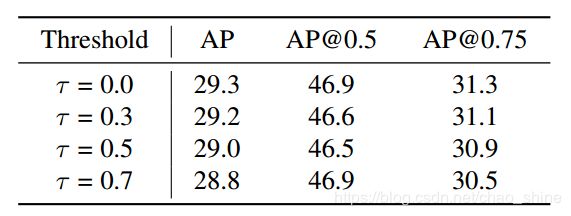
C、训练样例的选择
假设一个阈值![]() ,Mask R-CNN得到的物体框级别分数超过
,Mask R-CNN得到的物体框级别分数超过![]() 时才作为输入。表6
时才作为输入。表6
表6 不同阈值的结果
4.4、相关讨论
A、MaskIoU的质量评价
论文使用真实Mask和预测的MaskIoU之间的相关系数来衡量预测质量,在验证集中对500张图片产生了50000个预测,图5是预测结果和真值间的MaskIoU的可视化。

图5 ResNet-18 FPN(a)和ResNet-101 DCN+FPN(b)
可以看到与真实的MaskIoU相关性很好,尤其是MaskIoU本身就高的。
B、MS R-CNN的上限性能
表7 上限性能的研究

论文的贡献点
⑴ 解决了Mask R-CNN存在的高分类分数与低性能的实例分割的不对称性,实现高质量的实例分割。
参考文献
- Krizhevsky A, Sutskever I, Hinton G E, et al. ImageNet Classification with Deep Convolutional Neural Networks[C]. neural information processing systems, 2012: 1097-1105.
- Girshick R B, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. computer vision and pattern recognition, 2014: 580-587.
- Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation[J]. computer vision and pattern recognition, 2015: 3431-3440.
- He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. international conference on computer vision, 2017: 2980-2988.
- Neumann L, Zisserman A, Vedaldi A. Relaxed Softmax: Efficient Confidence Auto-Calibration for Safe Pedestrian Detection[J]. 2018.
- Huang Z, Huang L, Gong Y, et al. Mask Scoring R-CNN[J]. arXiv preprint arXiv:1903.00241, 2019.