从零开始学caffe(三):在win64下利用caffe快速实现MNIST手写数字识别
本文主要是在win64位系统下,编译环境为Visual Studio 2013 Ultimate版本,利用caffe框架来实现mnist手写数字识别,本文所用的相关资源见github
step1:数据集下载
首先需要下载MNIST手写数字集,下载地址:http://yann.lecun.com/exdb/mnist/
将下面这四个压缩包下载到电脑中并进行解压(数据集分为训练数据集和测试数据集两种,图片的像素强度介于0~255之间)

step2:数据集转换
这里需要注意的是,虽然上一个步骤外面已经对数据集进行下载,但是下载得到的数据集是二进制文件,我们需要对其进行转化为LEVELDB或LMDB格式,本文选择的格式为LMDB。
LMDB有如下两个好处,
(1)可以对数据类型进行统一,将各种数据都转化为LMDB。
(2)LMDB中文名字为闪电般的内存映射型数据库管理器,将其他格式数据转化为LMDB可以加快数据读取速度。
在这一部分,我们使用之前环境配置时生成的convert_mnist_data_exe(在生成的build文件夹中)来实现数据转化。我们在mnist文件夹下新建文件夹bat,新建一个批处理文件convert_train_lmdb.bat,并新建文件夹lmdb,用于对转化后数据的储存。对其进行编辑如下:
%批处理文件的格式是应用文件+空格+参数,这里^用来做参数间的分隔,该代码共三个参数
%执行数据转换程序%
%传入测试图片%
%传入测试图片的标签%
%转换后的数据存放在此目录%
E:\caffe-windows\Build\x64\Debug\convert_mnist_data.exe ^
E:\caffe-windows\examples\mnist\MNIST_data\train-images.idx3-ubyte ^
E:\caffe-windows\examples\mnist\MNIST_data\train-labels.idx1-ubyte ^
E:\caffe-windows\examples\mnist\lmdb\train_lmbd
pause
这里需要注意的是,这里的地址是我电脑中的相关路径,运行的时候要根据实际情况进行修改。
同理,我们新建convert_test_lmdb.bat,并对其进行编辑,实现对测试数据集的转化:
%执行数据转换程序%
%传入测试图片%
%传入测试图片的标签%
%转换后的数据存放在此目录%
E:\caffe-windows\Build\x64\Debug\convert_mnist_data.exe ^
E:\caffe-windows\examples\mnist\MNIST_data\t10k-images.idx3-ubyte ^
E:\caffe-windows\examples\mnist\MNIST_data\t10k-labels.idx1-ubyte ^
E:\caffe-windows\examples\mnist\lmdb\test_lmbd
pause
打开lmdb文件夹,我们发现转化后的两个数据集已经存放在其中,说明这一部分操作顺利完成。
step3:修改网络模型描述文件
网络模型描述文件是项目的关键组成部分,利用caffe框架对模型的结构进行定义。我们可以在路径caffe-windows\examples\mnist\lenet_train_test.prototxt中找到相关的网络模型描述文件,并根据实际情况对模型中的路径进行修改。并将数据输入层和数据测试层中的导入地址改为上一个步骤生成文件的地址,具体操作如下:
数据输入层
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "E:/caffe-windows/examples/mnist/lmdb/train_lmbd"
batch_size: 64
backend: LMDB
}
}
数据测试层
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "E:/caffe-windows/examples/mnist/lmdb/train_lmbd"
batch_size: 64
backend: LMDB
}
}
step4:修改超参数文件
超参数文件对模型结构中的一些超参数给出定义,可以在路径caffe-windows\examples\mnist\lenet_solver.prototxt中找个该文件,有三处需要修改的地方。
首先是第二行对传入网络模型描述文件地址的更改,将代码中的地址改为前一个步骤lenet_train_test.prototxt文件的地址。修改后代码为:
net: "E:/caffe-windows/examples/mnist/lenet_train_test.prototxt"
在mnist文件夹下新建models文件夹,用于存放训练得到的模型,并对地址修改如下:
snapshot_prefix: "E:/caffe-windows/examples/mnist/models/"
因为本文是在CPU版本下完成MNIST手写数字识别,所以最后将GPU改完CPU。
step5:模型训练
在bat文件夹中新建train.bat文件,并对其进行编辑如下:
%train训练数据%
%超参数文件%
E:\caffe-windows\Build\x64\Debug\caffe.exe train ^
-solver=E:/caffe-windows/examples/mnist/lenet_solver.prototxt
pause
运行该程序,对模型进行训练。
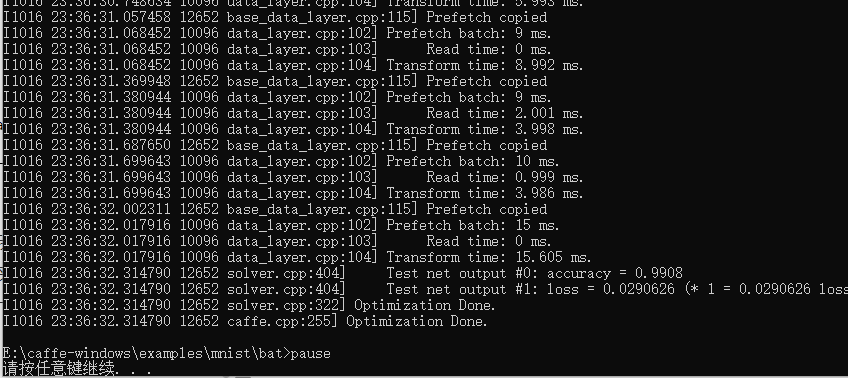
因为在超参数文件中我们设置了每5000次迭代输出一次模型,训练结束后,我们可以在models文件夹中看到的模型(为了让训练效果更明显,我将超参数改为每500次迭代输出一次模型)
打开models文件夹,我们可以看到得到的模型如下:
(如果按照每5000次迭代输出一个模型,这个文件夹中应该只有5000和10000两个,模型,因为我将超参数改为了500,所以产生的模型数目非常多)。
step6:准备测试图片
我们在模型训练部分使用的数据集是二进制文件,我们没法从中看出数字大小,在测试部分,我们选择了黑白手写数字0~9进行测试,并将其放入MNIST_data文件夹中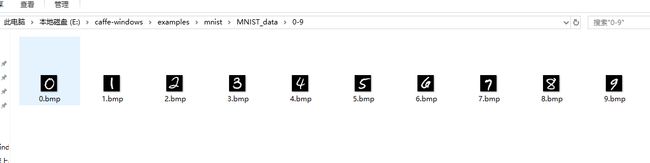
step7:生成均值文件
图片减去均值后,再进行训练和测试,会提高速度和精度。因此,一般在各种图像识别的模型中都会有这个操作。实际上就是计算所有训练样本的平均值,计算出来后,保存为一个均值文件,在以后的测试中,就可以直接使用这个均值来相减,而不需要对测试图片重新计算。
在bat文件夹下新建mnist_mean.bat文件,并对其进行编辑如下:
%train训练数据%
%导入超参数文件%
E:\caffe-windows\Build\x64\Debug\caffe.exe train ^
-solver=E:/caffe-windows/examples/mnist/lenet_solver.prototxt
pause
在mnist文件夹下新建mean_file文件夹,用于存放生成的均值文件,运行mnist_mean.bat。打开mean_file文件夹我们可以发现里面已经有一个mean.binaryproto的文件。
step8:准备标准标签
因为我们在种类是对0-9的数字进行识别,因此我们在这里需要准备0-9标准标签。具体操作如下:在mnist文件夹中新建一个label文件,然后在其中新建一个label_text文件,在该文件里面输入数字0~9作为标准标签。
step9:测试结果
在bat中新建文件mnist_classification.bat,并对其进行编辑如下:
%分类可执行程序%
%网络结构%
%训练好的模型%
%均值文件%
%标签%
%要分类的图片%
E:\caffe-windows\Build\x64\Debug\classification.exe ^
E:\caffe-windows\examples\mnist\lenet.prototxt ^
E:\caffe-windows\examples\mnist\models\_iter_500.caffemodel ^
E:\caffe-windows\examples\mnist\mean_file\mean.binaryproto ^
E:\caffe-windows\examples\mnist\label\label.txt ^
E:\caffe-windows\examples\mnist\MNIST_data\0-9\1.bmp
pause
运行改程序,即可得到最终的识别结果:
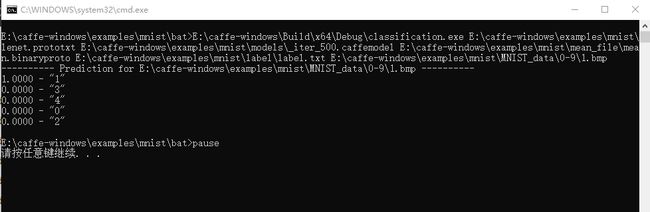
在运行mnist_classification.bat时,我们选择的路径是数字1(1.bmp)的路径,在给出的五个识别结果中,数字1的可能性最大,经过对其他9个数字的检验发现全部正确,识别正确率较高。