大数据 hadoop 集群搭建
hadoop集群安装部署文档
- 一、 系统环境配置
- 1、修改主机名
- 2、添加主机名映射
- 3、创建集群管理用户,设置密码
- 4、分配用户sudo权限
- 5、创建用户文件存放及安装目录
- 6、关闭防火墙
- 7、安装jdk,配置jdk环境变量
- 二、 Hadoop集群搭建
- 1、安装hadoop,配置hadoop环境变量
- 2、修改 hadoop-env.sh 文件
- 3、执行本地模式wordcount案例
- 4、克隆虚拟机
- 5、修改网络配置及主机名,开启ssh免密登录
- 6、修改hadoop配置文件
- core-site.xml
- Hdfs.site.xml
- Yarn.site.xml
- Mapred.site.xml
一、 系统环境配置
1、修改主机名
[root@localhost ~]# vim /etc/sysconfig/network
需重启后生效
2、添加主机名映射
[root@hadoop101 ~]# vim /etc/hosts
3、创建集群管理用户,设置密码
[root@hadoop101 ~]# useradd caobin
[root@hadoop101 ~]# passwd caobin
4、分配用户sudo权限
[root@hadoop101 ~]# vim /etc/sudoers
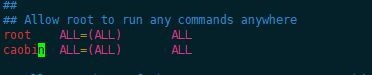
5、创建用户文件存放及安装目录
[root@hadoop101 ~]# su caobin
[caobin@hadoop101 ~]$ cd /opt/
[caobin@hadoop101 opt]$ sudo mkdir software
[caobin@hadoop101 opt]$ sudo mkdir module
[caobin@hadoop101 opt]$ sudo chown caobin:caobin module/ software/
6、关闭防火墙
[caobin@hadoop101 opt]$ sudo service iptables stop
[caobin@hadoop101 opt]$ sudo service iptables status
7、安装jdk,配置jdk环境变量
使用传输工具上传jdk的Linux压缩包到 software文件夹
[caobin@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[caobin@hadoop101 jdk1.8.0_144]$ sudo vim /etc/profile
在文件末尾追加下图代码
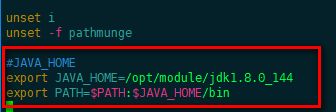
二、 Hadoop集群搭建
1、安装hadoop,配置hadoop环境变量
上传hadoop压缩包到software,解压到module文件夹
[caobin@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
[caobin@hadoop101 hadoop-2.7.2]$ sudo vim /etc/profile
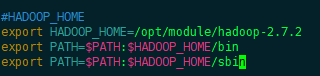
启用并验证环境变量
[caobin@hadoop101 bin]$ source /etc/profile
[caobin@hadoop101 bin]$ java -version
[caobin@hadoop101 bin]$ hadoop version
2、修改 hadoop-env.sh 文件
[caobin@hadoop101 bin]$ cd /opt/module/hadoop-2.7.2/
[caobin@hadoop101 hadoop-2.7.2]$ cd etc/hadoop/
[caobin@hadoop101 hadoop]$ vim hadoop-env.sh
指定java安装路径

3、执行本地模式wordcount案例
[caobin@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount LICENSE.txt output
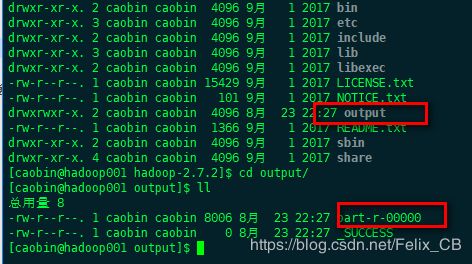
4、克隆虚拟机
用当前虚拟机,再克隆2台虚拟机
5、修改网络配置及主机名,开启ssh免密登录
修改克隆后的网络配置
[caobin@hadoop101 ~]$ ssh-keygen -t rsa
三次回车,生成密钥
[caobin@hadoop101 ~]$ ssh-copy-id hadoop002
分发公钥
分别在三台机器上执行
6、修改hadoop配置文件
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_144
yarn-env.sh
# some Java parameters
export JAVA_HOME=/opt/module/jdk1.8.0_144
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop101:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
Hdfs.site.xml
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop103:50090value>
property>
Yarn.site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop102value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
Mapred.site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop101:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop101:19888value>
property>
7、 分发配置文件
分发脚本,根据实际主机名更改脚本内容
使用scp 或者 rsync
此粗提供分发脚本参考
###########################
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=101; host<104; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
###########################
[caobin@hadoop101 hadoop-2.7.2]$ ~/bin/xsync.sh etc/hadoop/
8、 格式化namenode , 启动集群
[caobin@hadoop001 hadoop-2.7.2]$ hadoop namenode -format
启动集群, 根据实际主机ip更改 脚本内容!
一键启动hadoop集群脚本参考
#!/bin/bash
Usage="Usage : $0 (start|stop|status)"
if [ $# -lt 1 ];then
echo $Usage
exit 1
fi
behave=$1
if [ $behave == "start" ];then
vstate="开始启动"
fi
if [ $behave == "stop" ];then
vstate="开始关闭"
fi
if [ $behave == "status" ];then
echo "===========查看hadoop102状态=========="
ssh caobin@hadoop101 "jps"
echo "===========查看hadoop103状态=========="
ssh caobin@hadoop102 "jps"
echo "===========查看hadoop104状态=========="
ssh caobin@hadoop103 "jps"
else
echo "=========$vstate hdfs服务========"
ssh caobin@hadoop101 "/opt/module/hadoop-2.7.2/sbin/$behave-dfs.sh"
echo "=========$vstate yarn服务========"
ssh caobin@hadoop102 "/opt/module/hadoop-2.7.2/sbin/$behave-yarn.sh"
fi
exit 0
启动后执行wordcount案例测试
50070 namenode web服务端口
8088 yarn及mapreduce 任务查看端口
19888 job日志查看端口