Python爬虫实战:百度贴吧—妈妈吧
上次,我们用requests 和 xpath爬取了极客学院的课程,感觉还是不过瘾,今天我们再来爬一下百度贴吧妈妈吧里面的话题,看看妈妈们都喜欢讨论什么吧!
爬取前我们先看一下我们的目标:
1.抓取百度贴吧妈妈吧的话题
2.抓取每一个话题的发布人、发布时间、发布标题、发布内容和回贴数目
1.确定URL
如何找URL,前面都说过的,我想大家都知道了,直接上URLhttp://tieba.baidu.com/f?kw=%E5%A6%88%E5%A6%88&ie=utf-8&pn=0,这次后面的数字稍微有些不同,第二页是50,第三页是100,以此类推。
2.Requests下载网页
这里就不啰嗦了,直接上代码了,不同的可以向前翻看别的文章:
import requests
url = 'http://tieba.baidu.com/f?kw=%E5%A6%88%E5%A6%88&ie=utf-8&pn=0'
html = requests.get(url)
print html.text3.Xpath解析网页
我们还是先来看一下妈妈吧的结构,F12审查元素,还是很漂亮的结构,我们还是先大后小的原则,每一个话题都在一个..... 里面:
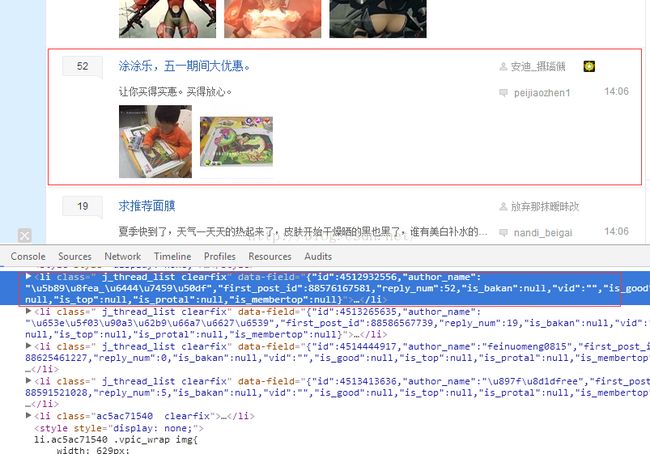
我们展开代码,依次找到我们想要的内容,发布人,创建时间,内容,回复数等,如下图:

好啦,结构和想要的信息都找到了,我们用xpath一一解析出来:
import requests
from lxml import etree
url = 'http://tieba.baidu.com/f?kw=%E5%A6%88%E5%A6%88&ie=utf-8&pn=0'
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//li[@class=" j_thread_list clearfix"]')
item = {}
for each in content_field:
reply_num = each.xpath('div/div[@class="col2_left j_threadlist_li_left"]/span/text()')[0]
list_title = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_title pull_left j_th_tit "]/a/text()')[0]
author = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="tb_icon_author "]/a/text()')[0]
create_time = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="pull-right is_show_create_time"]/text()')[0]
content = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_detail clearfix"]/div[@class="threadlist_text pull_left"]/div/text()')[0]
print reply_num
print list_title
print author
print author
print create_time
print content运行一下,咦!!这是什么情况:
list_title = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_title pull_left j_th_tit "]/a/text()')[0]
IndexError: list index out of rangeimport requests
from lxml import etree
url = 'http://tieba.baidu.com/f?kw=%E5%A6%88%E5%A6%88&ie=utf-8&pn=0'
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//li[@class=" j_thread_list clearfix"]')
item = {}
for each in content_field:
try:
reply_num = each.xpath('div/div[@class="col2_left j_threadlist_li_left"]/span/text()')[0]
list_title = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_title pull_left j_th_tit "]/a/text()')[0]
author = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="tb_icon_author "]/a/text()')[0]
create_time = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="pull-right is_show_create_time"]/text()')[0]
content = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_detail clearfix"]/div[@class="threadlist_text pull_left"]/div/text()')[0]
print reply_num
print list_title
print author
print author
print create_time
print content
except Exception, e:
continue好啦,一页的内容就这么爬出来了,就这么简简单单的几行代码!
4.面向对象完整代码
跟上次一下,我们美观一下,做一个面向对象的代码,这次还是爬取10页吧!
# _*_ coding:utf-8 _*_
from lxml import etree
import requests
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#内容输出
def towrite(contentdict):
f.writelines(u'回帖数目:' + unicode(contentdict['reply_num']) + '\n')
f.writelines(u'发布标题:' + unicode(contentdict['topic_title']) + '\n')
f.writelines(u'发布内容:' + unicode(contentdict['topic_content']) + '\n')
f.writelines(u'发布人:' + unicode(contentdict['user_name']) + '\n')
f.writelines(u'发布时间:' + str(contentdict['topic_time']) + '\n\n')
#爬虫主体
def spider(url):
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//li[@class=" j_thread_list clearfix"]')
item = {}
for each in content_field:
try:
item['reply_num'] = each.xpath('div/div[@class="col2_left j_threadlist_li_left"]/span/text()')[0]
item['topic_title'] = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_title pull_left j_th_tit "]/a/text()')[0]
item['user_name'] = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="tb_icon_author "]/a/text()')[0]
item['topic_time'] = each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_lz clearfix"]/div[@class="threadlist_author pull_right"]/span[@class="pull-right is_show_create_time"]/text()')[0]
content = (each.xpath('div/div[@class="col2_right j_threadlist_li_right "]/div[@class="threadlist_detail clearfix"]/div[@class="threadlist_text pull_left"]/div/text()')[0]).split()
item['topic_content'] = ''.join(content)
towrite(item)
except Exception,e:
continue
if __name__ == '__main__':
f = open('content.txt','a')
page = []
#循环用来生产不同页数的链接
for x in range(10):
i = x*50
newpage = 'http://tieba.baidu.com/f?kw=%E5%A6%88%E5%A6%88&ie=utf-8&pn=' + str(i)
print u"第%d页"%(x+1)
print newpage
BDTBspier = spider(newpage)