前言
从人们在互联网上的公开话语中, 可以提取到异常多的信息。 在Heuritech,我们使用这些信息来更好地了解人们想要什么,他们喜欢什么产品以及原因。 这篇文章从科学的角度解释了什么是知识提取和细节,它们在几个最新的方法中是如何做到的。
什么是知识提取?
高度结构化的数据库使其容易来推理,并且可以用来进行推测。 例如,在WikiData(h̀ps://www.wikidata.org/wiki/Wikidata:Main_Page) 或 YAGO(h̀p://www2007.org/papers/paper391.pdf),实体是隔离的, 之间是通过关系连接到一起的。 然而,大多数人类知识表达采取非结构化文本的形式,从中很难推理和获得智慧。 例如下面的例子:

左边的原始文本包含了以非结构化方式呈现的很多有用信息,例如生日、国籍、活动。 提取这些信息对应到了自然语言处理中的一个具有挑战性的领域,即可能需要句子剖析(将自然语言映射为机器可理解的表达),实体检测和多参考解析来聚集同一个实体的相关信息。 知识提取的导入是为了,例如,能够执行QuestionAnswering任务:在结构化知识库中,人们可以进行查询并得到所请求的信息。 另一个应用是通过在提取的知识图中找到相应路径来进行任意复杂的推理。 在知识提取中,人们可能对上下关系中实体包含于其他实体而感兴趣,也可能是对关系提取感兴趣的。
这篇博文的目的是回顾能从原始文本或现有知识图中采集和提取结构化信息的方法。 更精确地,我们旨在从语义上解析文本以便提取实体和/或关系。 我们定义句子中一个三元组为两个实体E1,E2和它们之间的关系R:(E1,R,E2)。 一个知识图 (KG)表示为一组三元组构建的图:顶点是实体和边是关系。 下面大多数文章假定实体是可识别和无歧义的。 在实践中,可以用类似来自Stanford的FACTORIE(h̀ps://people.cs.umass.edu/~kschulꀀ/publications/factorie‑nips‑2009.pdf)或NER parser
(h̀p://nlp.stanford.edu/software/CRF‑NER.shtml)这样的工具来实现。
知识图谱完成化:链接预测
尽管在Heuritech我们对从原始文本中进行知识提取更感兴趣,我们还是先快速在这回顾下只依赖于一个KG(没有额外文本语料库可用)的技术。 我们要执行的任务是填充一个不完整的KG。 在2013年之前,连接以图论的技术来完成,却忽略了图是KG的事实。
在2013年,TranslatingEmbeddings for Modelling Multi-relational Data(byBordes et al)
的论文(h̀ps://www.utc.fr/~bordesan/dokuwiki/_media/en/transe_nips13.pdf)是专注KG完成化方法的第一次尝试。 它在相同的低维向量空间中学习实体和关系的嵌入。 目标函数需要约束实体E2接近E1 + R。
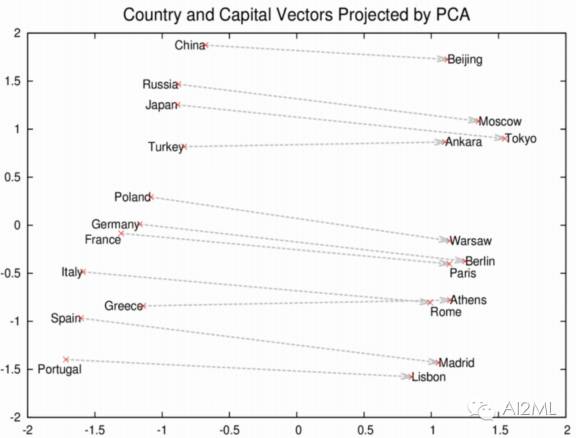
这是通过对现有三元组赋于一个高于由负抽样的随机三元组的分数来实现的(h̀p://deeplearning4j.org/word2vec)。 上述模型被称为TRANSE,这项工作与Mikolov的word2vec(h̀p://deeplearning4j.org/word2vec)有关,在图片中可看到,word2vec中概念之间的关系自然地采用嵌入空间转换的形式。
再添加一些改进就进化到TransH和TransR这些模型了。Probabilistic Reasoning via DeepLearning: Neural Association Models是目前最佳方法。
从原始文本中提取三元组
这里,我们专注于从原始文本提取三元组(E1,R ,E2)。 取决于所使用的监督类型,这个任务有多种变身。三元组的提取可以百分百的以无监督的方式进行。 通常,文本首先被不同的工具(例如TreeBank剖析器,MiniPar或OpenNLP剖析器)来解析,然后实体(以及来剖析器的标记)之间的文本被聚类并最终简化。虽然一看上去很有吸引力,因为看不需要监督,其实缺点很多。首先,根据使用的剖析器的不同,所依赖的手工定制的规则就是非常枯燥繁琐。再加上,发掘的聚类虽然包含了语义上相关的关系,但它们不能给出跟细化的释义。通常,聚类中可以包含“is-capital-of”和“is-city-of”这样语义接近的关系。 然而,仅仅依赖无监督,我们将不会发现“is-capital-of” 能推出“is-city-of”的关系,但是反过来推理就不可以。
我们还是更关注不同方面的监督: 监督学习 , 远程监督和通用Schema 。 我们先给出一些定义。 固定的Schema关系的抽取是指被发现的关系是来自固定的含有可能关系的列表。与此相反,在开放域关系抽取,关系不受此限制。在这种情况下,没有固定Schema来过多的限制知识提取,如果不是完美的适用的话。但是,这就让从一个由开放域构成的图中泛化和推测新的关系变得更加困难,因为太多的关系有各种类型。OpenIE(开放信息抽取)是一种过滤器和标准化实体之间的原始文本以获得开放域关系的工具。
基于Schema的监督学习
在这种案例中,可用数据是一个句子集,每个句子用从它提取的三元组来标注。这意味着原始文本对应到了文本的知识图谱(KG)。 最近有两篇论文(均出版于2016年)为这个问题提供了前沿的解决方案。
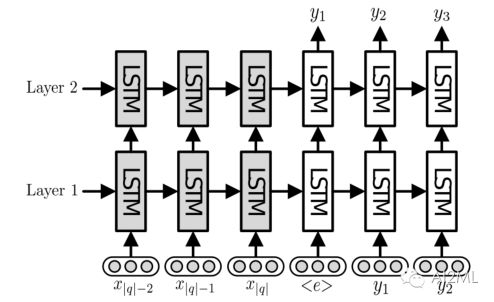
End-to-End RelationExtraction using LSTMs on Sequences and Tree Structures(by Miwa and Bansal)的论文展示了一个利用双堆栈网络的方法: 一个双向LSTM做实体检测(它创建一个实体的嵌入), 另外一个Tree-based LSTM用于检测出找到的实体之间链接关系。 下图来自原始文件,显示了所使用的架构。

他们的方法是将原始文本做了词性标注, 这和原始词一起输入到双向LSTM。 这种方法的优势在于实现了端到端,这样模型联合在一起学习检测实体和关系。 这个架构是相当复杂,作者使用了很多奇技淫巧来训练(如Schedule采样和实体的预训练 )。 这些技巧显着提高了训练模型的效果。 该方法胜过了ACE04和ACE05数据集上的关系提取任务和 SemEval-2010任务8开发集上取得的最佳结果方法。可以发现超过80%的实体和60%的关系。
Dong和Lapata合写的论文Language to Logical Form with neuralattention (htt̀p://arxiv.org/abs/1601.01280) 描述了一个sequence-to-sequence的模型。它将原始句子作为输入(不需要POS Tagging标记)并且能输出所需的信息。 在我们这种情况下,所需的信息是三元组(E1,R,E2),但原始论文给出的模型并不局限于这种特定案例。 该模型是编码器-解码器架构。 更确切地说,LSTM单元分布在堆栈两层结构里, 并且使用了注意机制( 见我们的其他博客文章,详细了解注意机制
https://blog.heuritech.com/2016/01/20/attention-mechanism/)。 注意机制使得自动学出自然语言表达和固定Schema关系之间的软对齐成为可能。 在后处理步骤中会处理生僻字和数字:在训练期间用生僻字标记或数字标记以及唯一ID来替换它。 在推理中,标记+ ID在被原始生僻字或数字替换回来。 为了避免过大的字典, 这个技巧非常好用。 实验结果达到了最先进方法的结果,有时甚至超过最先进方法。 注意,实验没有专门针对三元组提取,所以我们不能与Miwa和Bansal模型比较。
关系提取的监督学习方法与端到端方法结合的很好(根据概述的第二篇文章中的案例,他们甚至不需要POS Tagging标记)。 但是,该种学习方式受到有限的标记数据量的限制,然而网络上可用的原始文本实际上是无限的。
基于Schema的远程监督
远程监督 ,也称弱监督 ,是指当我们想从文本中抽取关系时,有个初始KG作为种子可以用来提取三元组。 一对实体是由链接他们的KG中的每一个关系弱监督的。当然,这种监督噪声很大,例如句子“巴拉克奥巴马比米歇尔奥巴马大3岁”将被(巴拉克奥巴马,米歇尔奥巴马)的KG实例(和所有其他连接奥巴马和他的妻子的实例)弱标记,但显然这两个关系不相同。 如果我们有很多文本和足够大的KG(含有文本中相同的实体),我们可以学习从原始文本到KG的固定Schema关系的映射。
Weston, Bordes et al. (2013) 写的ConnectingLanguage and Knowledge Bases with Embedding Models for Relation Extraction就是一个远程监督。 它假定实体被发现,然后消除歧义,并且实体之间的文本利用OpenIE工具在开放域关系进行转换。 实体和关系的嵌入创建在在同样的低维空间中。OpenIE文本到最相似固定Schema关系的映射是通过他们之间的嵌入的相似度计算的。这个系统是通过排序误差来训练的。给定一个OpenIE关系,这个想法给含有弱标签的配对要比KG中的随机关系(通过Negative Sampling)要更高的得分。这个文件更进一步,一旦文本中提出去三元组,这个模型就学出实体和它们之间关系的空间嵌入值。在这个嵌入空间中,我们期望关系r对应到E1到E2的转化。这个空间嵌入不仅由找到的三元组创建,也包括原始KG里面的所有三元组。
在上面提供的所有示例中,找到的关系在最初提出的固定Schema之内。 然而,如前所述,不存一个固定Schema能够完美的适合所有可能的文本能够表达的两个实体间的关系,
通用Schema
通用Schema通过嵌入文本中包含的来自种子KG(固定Schema的关系)和开放领域的关系来建立KG。 通用Schema的一个巨大优势是它不需要远程监督。通过学习嵌入来为实体和关系建立语义空间。固定Schema关系的嵌入对于开放域关系来说是相同的:关于两类关系的推断是可能的,KG完善是能够改进的。

介绍通用Schema的第一篇文章是RelationExtraction with Matrix Factorization and Universal Schemas(Riedel et al. in2013)。在本文中,使用OpenIE工具计算开放域关系。然后创建一个二进制矩阵,其中行对应于成对的实体,而列对应到到固定Schema关系和开放域关系的连接。矩阵中的1表示实体之间存在关系。我们希望预测矩阵中的缺失值,并生成一个置信度值(在0和1之间),正如原始论文中的图片所展示的。 矩阵构造所带来的思考是使得关系提取逼近另一个领域:协同过滤。因而也可以使用协同过滤的方法来推断新关系。
可以考虑应用嵌入方法的几种参数化处理:隐含特征模型,邻居模型和实体模型,或甚至它们之间的组合。 对于训练而言,BayesianPersonalized Ranking (BPR)可以被使用; 它是一种排序流程,给予观察到的事实比随机事实(通过Negative Samping获得)以更高的得分。
上述方法的问题是每个openIE文本嵌入在不同的向量中,因此不可能泛化到一个没有在训练集出现的新的openIE文本。
基于深度学习的通用Schema
Representing Text for Joint Embedding of Text and Knowledge Bases(Toutanova等,2015)提出利用卷积神经网络(ConvNet)来嵌入实体之间的文本, 实现泛化到新的开放领域关系的问题。和前面提到的使用openIE工具不同。
使用ConvNet用于参数化在两个实体之间(在字的层次上)对文本进行参数化。利用句法依赖解析作为额外输入。在这里的图片上,黄色向量是开放域关系的嵌入。注意,在嵌入上相似的开放域关系也避开在了在协同过滤中的冷启动问题。

MultilingualRelation Extraction using Compositional Universal Schema( Verga et al. 2016) 使用了相同的架构。
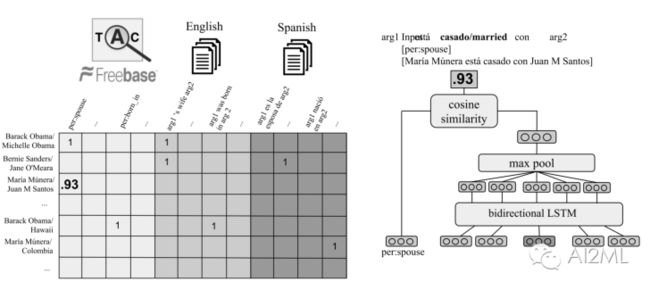
他们试验了ConvNet和LSTM循环神经网络,结果证明LSTM网络优于ConvNet。他们的模型和Toutanova的模型之间有两个其他的区别。 第一个是当我们想要泛化文本而不重新训练模型时,在推理时利用开放域关系的编码器网络。 第二,Verga 等没使用对原始文本的句法依赖性解析的信息。 Verga 等更进一步,因为他们的模型应用于多语言数据。重要的是,他们的方法使用多语言迁移学习,提供了在KG中没有实体的语言提供预测模型,通过为跨文本语料库的共享实体学习类似的表达。 下图给出了要填充的矩阵和参数化模型的概述。 请注意,不同的编码器(带有权重)用于不同的语言。 有趣的是,英语和西班牙语的联合学习仅仅提高了英语模型的得分。
文章还强调开放域关系, 这些关系从过滤和规范化实体之间的原始文本获得, 这对惯用的表达式也有优势,例如当文本片段的含义不是它包含的单词的组合时。在这种情况下,我们不想将惯用表达式送到LSTM网络,但是更好地学习它的唯一嵌入。 在实践中,文章显示整合两种嵌入参数化(基于字的LSTM和唯一嵌入)词的整体非常好,因为它充分利用了互补的方法。
结论
我们在这里回顾了各种技术来推断知识图中的新关系,以及从文档中提取关系。 我们关注最近的技术,这些技术依赖于关系和实体的嵌入,深度学习,协同过滤... 我们的进一步工作是考虑那些不总能给出绝对的或者不按时间变化的知识的文本。 例如,在社交媒体中,当人们表达自己的意见时,事实可能因人而异,导致知识库的冲突。 此外,在Heuritech,我们对多模数据感兴趣,因此我们希望能够从图像中提取相关信息,并将其和从文本中找到的信息放在相同的KG中。
原文: Eloizablocki, knowledge extraction from unstructured texts, 2016/04/15, https://blog.heuritech.com/author/eloizablocki/

