为什么有三AI从来不追热点,信息越多学的越慢

周一又到了,大家又开始紧张的工作和学习。前面有三已经说过我们的作死三原则中的“不接广告”,“不转文章只做原创”,今天来谈谈最后一个问题,“不追热点”。
文/编辑 | 言有三
1 技术人员不应该只做一个看客
曾经GitHub上面的一个996项目+马云马老师“修来的福报”论,知乎两天突破2千万阅读量,公众号火了将近半个月,几乎人人转发,可是热闹过后你收获了什么?有什么东西改变了吗?技术圈虽然没有娱乐圈玩的溜,每隔一段时间还是会有热点发生,可惜对于提升技术有用的很少。
几年前我曾经仔仔细细去翻阅了一个月的机器之心/新智元等公众号的文章,试图跟上它的节奏(技术+工业界发展),后来发现存在两个问题。
第一个,覆盖范围太广了,就算每天只是看这几个号的文章,也根本不可能跟上,就像猴子下山摘玉米那个故事,看到了新的又想去关注一下,最后都是一场空。
第二个,东西太散乱,终究还是只能当作信息媒体来阅读,如果较真反受其乱影响学习。
媒体写文章的套路就是xx机构xx大神取得了xx牛皮的效果,大部分订阅者先被xx机构吸引,再被xx大神吸引,然后去文章里看两张xx图,看一下评论,开始讨论。
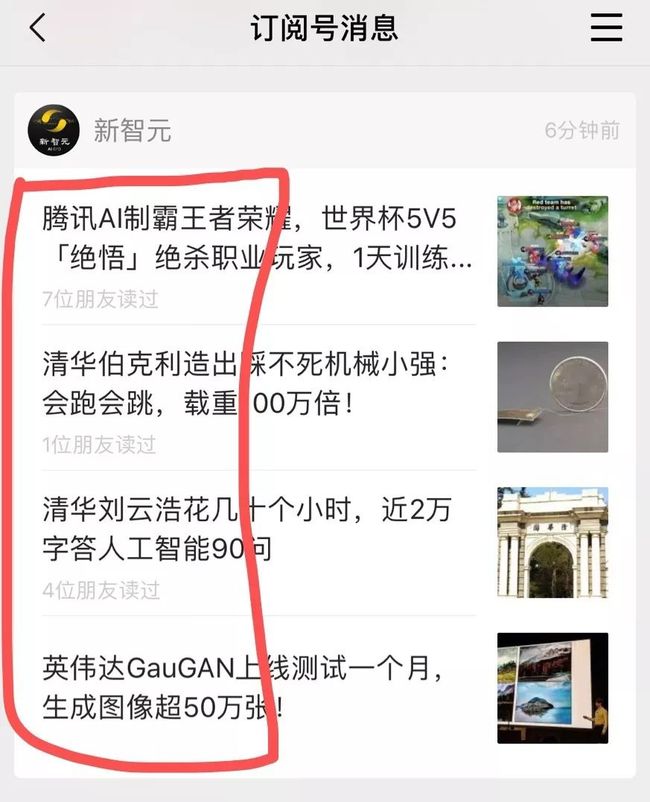
它给人一个错觉,学到了很多东西,涨了很多见识,但是可惜,往往并没有,信息不等于知识,浏览不等于学会。
一个初学者,很容易就被媒体制造的各种“重大突破”带节奏,中了“信息毒品”。建议刚开始的时候尽量少看,不然往往过了很长的一段时间后,还作为一个看客在圈外游荡,没有真正学习到系统性的知识。
2 信息越多学的越慢
程序员查一个bug,可能下意识点开很多回答,然后去匹配答案,总想最快解决问题,有时候没有认真思考bug后面的深层原因,下一次依旧会踩坑。
还有一种现象,同样的一个问题可能有多个开源项目解答,但是每一个跑起来都会有点小问题,一个跑不通就想着换下一个,最终发现一个都没搞成,还不如老老实实解决一个项目中的问题。
一方面选择太多了,人的思维惰性就容易发作,解决问题采取匹配答案式而不是思考。另一方面信息太多产生了浮躁,看到送1000G学习资料的就想去收集,然后这些就成为了“收藏但是不看”系列。
有三现在每天顶多看5个公众号的文章,大部分非技术文章都只看一下标题,只有深入技术本身,才有足够的评判能力。
3 有三AI平台定位
其实我跟大家解释过,有三AI不是媒体,也不是论坛,而是正经的教育平台,我们一年几百篇文章,全部都是原创,而且是成套的系列原创,每一篇文章都是仔细推敲过的。
可以参考文章:【杂谈】怎么使用有三AI完成系统性学习并赚钱
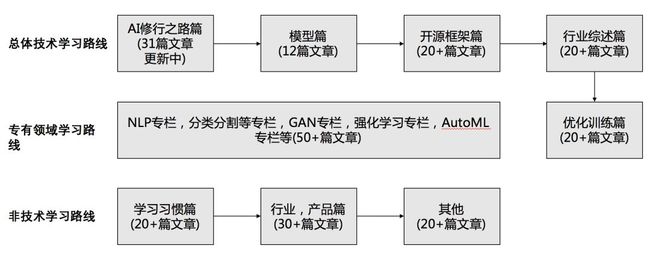
我们的目标群体就是真正要学习这一行知识的局内人,不是看客。有三离职如果只是做一个媒体,那就是以己之短搏人之长了。
为什么要做各种各样的技术专栏从简到难讲述问题,既花掉了很多的时间,阅读量又不讨喜,就是希望大家根基要稳。有些东西其实你现在看起来落后了,以后追赶起来举一反三快得很。
最近很多朋友都在忙于秋招,作为线上面试官也面试了一些同学,关注了一些消息,发现大家的思维还在面经上。这也没什么问题,面试本来也是应试,套路依旧在。
但在这个过程中许多同学忘记了去夯实自己的基础,而是发力于多跑几个项目,每一个深度都不够,华而不实。
其实不管是老师还是好的技术boss,更看重的是知识根基是否扎实,潜力如何。而不是当下了解了多少东西,能够侃侃而谈多少东西。
因为你的天花板,由代表内功的知识基础决定,静下心来学习吧。
转载文章请后台联系
侵权必究

【完结】深度学习CV算法工程师从入门到初级面试有多远,大概是25篇文章的距离
【完结】优秀的深度学习从业者都有哪些优秀的习惯
【完结】给新手的12大深度学习开源框架快速入门项目
【完结】总结12大CNN主流模型架构设计思想
【知乎直播】千奇百怪的CNN网络架构等你来
【AI不惑境】数据压榨有多狠,人工智能就有多成功
【AI不惑境】网络深度对深度学习模型性能有什么影响?
【AI不惑境】网络的宽度如何影响深度学习模型的性能?
【AI不惑境】学习率和batchsize如何影响模型的性能?
【AI不惑境】残差网络的前世今生与原理
【AI不惑境】移动端高效网络,卷积拆分和分组的精髓
【AI不惑境】深度学习中的多尺度模型设计
【AI不惑境】计算机视觉中注意力机制原理及其模型发展和应用