pytorch实现LeNet5
本文需要对卷积神经网络有一定的了解,可以参考本博文。
(一)LeNet简介
LeNet网络结构如下图所示:
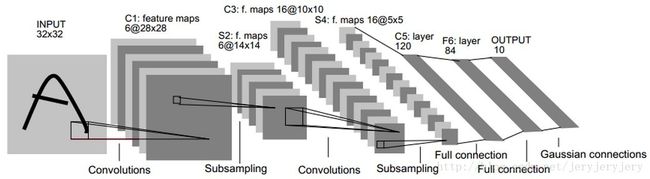
1.第一层C1是一个卷积层
输入图片: 32*32
卷积核大小: 5*5
卷积核种类: 6
输出feature map大小:28*28(32-5+1)
神经元数量:28*28*6
可训练参数数量:(5*5+1)*6,(每个卷积核25个权重值w,一个截距值bias;总共6个卷积核)
连接数量:(5*5+1)*6*28*28
2.第二层S2是一个下采样层(池化层):
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置,结果通过sigmoid。(论文原文是这样描述,但是实际中,我看到一般都是用最大池化)
种类数量:6
输出的feature map大小时:14*14(28/2)
神经元数量:14*14*6
可训练参数:2*6(和的权重w和偏置bias,然后乘以6)
连接数:(2*2+1)*6*14*14
3.第三层C3也是一个卷积层
输入:S2中所有6个或者几个特征的map组合,这个组合并无太大实际意义,受限于当时的硬件水平,才这样组合
卷积核大小:5*5
卷积核种类:16
输出feature map大小:10*10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的
特征map的不同组合,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来
6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个
将S2中所有特征图为输入。此时可训练参数:6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+(25*6+1)=1516
连接数:10*10*1516=151600
4.第四层S4是一个下采样层(池化层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置,结果通过sigmoid
采样种类:16
输出feature map大小:5*5(10/2)
神经元数量:5*5*16=400
可训练参数:2*16=32(和的权重2+偏置bias,乘以16)
连接数:16*(2*2+1)*5*5=2000
5.第五层C5是一个卷积层(论文原文的描述)
输入:S4层的全部16个单元特征map(与S4全连接)
卷积核大小:5*5
卷积核种类:120
输出feature map大小:1*1
可训练参数/连接数:120*(16*5*5+1)=48120
6.第六层F6层全连接层
输入:C5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数
可训练参数:84*(120+1)=10164
(二)pytorch实现
#author = liuwei
import gzip, struct
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
from torch.utils.data import TensorDataset, DataLoader
from torchvision import transforms
import math
#读取数据的函数,先读取标签,再读取图片
def _read(image, label):
minist_dir = 'data/'
with gzip.open(minist_dir + label) as flbl:
magic, num = struct.unpack(">II", flbl.read(8))
label = np.fromstring(flbl.read(), dtype=np.int8)
with gzip.open(minist_dir + image, 'rb') as fimg:
magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16))
image = np.fromstring(fimg.read(), dtype=np.uint8).reshape(len(label), rows, cols)
return image, label
#读取数据
def get_data():
train_img, train_label = _read(
'train-images-idx3-ubyte.gz',
'train-labels-idx1-ubyte.gz')
test_img, test_label = _read(
't10k-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz')
return [train_img, train_label, test_img, test_label]
#定义lenet5
class LeNet5(nn.Module):
def __init__(self):
'''构造函数,定义网络的结构'''
super().__init__()
#定义卷积层,1个输入通道,6个输出通道,5*5的卷积filter,外层补上了两圈0,因为输入的是32*32
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
#第二个卷积层,6个输入,16个输出,5*5的卷积filter
self.conv2 = nn.Conv2d(6, 16, 5)
#最后是三个全连接层
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
'''前向传播函数'''
#先卷积,然后调用relu激活函数,再最大值池化操作
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
#第二次卷积+池化操作
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
#重新塑形,将多维数据重新塑造为二维数据,256*400
x = x.view(-1, self.num_flat_features(x))
print('size', x.size())
#第一个全连接
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
#x.size()返回值为(256, 16, 5, 5),size的值为(16, 5, 5),256是batch_size
size = x.size()[1:] #x.size返回的是一个元组,size表示截取元组中第二个开始的数字
num_features = 1
for s in size:
num_features *= s
return num_features
#定义一些超参数
use_gpu = torch.cuda.is_available()
batch_size = 256
kwargs = {'num_workers': 2, 'pin_memory': True} #DataLoader的参数
#参数值初始化
def weight_init(m):
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weigth.data.fill_(1)
m.bias.data.zero_()
#训练函数
def train(epoch):
#调用前向传播
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if use_gpu:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target) #定义为Variable类型,能够调用autograd
#初始化时,要清空梯度
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step() #相当于更新权重值
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data[0]))
#定义测试函数
def test():
model.eval() #让模型变为测试模式,主要是保证dropout和BN和训练过程一致。BN是指batch normalization
test_loss = 0
correct = 0
for data, target in test_loader:
if use_gpu:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
#计算总的损失
test_loss += criterion(output, target).data[0]
pred = output.data.max(1, keepdim=True)[1] #获得得分最高的类别
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
#获取数据,
X, y, Xt, yt = get_data()
train_x, train_y = torch.from_numpy(X.reshape(-1, 1, 28, 28)).float(), torch.from_numpy(y.astype(int))
test_x, test_y = [torch.from_numpy(Xt.reshape(-1, 1, 28, 28)).float(), torch.from_numpy(yt.astype(int))]
#封装好数据和标签
train_dataset = TensorDataset(data_tensor=train_x, target_tensor=train_y)
test_dataset = TensorDataset(data_tensor=test_x, target_tensor=test_y)
#定义数据加载器
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, **kwargs)
test_loader = DataLoader(dataset=test_dataset, shuffle=True, batch_size=batch_size, **kwargs)
#实例化网络
model = LeNet5()
if use_gpu:
model = model.cuda()
print('USE GPU')
else:
print('USE CPU')
#定义代价函数,使用交叉熵验证
criterion = nn.CrossEntropyLoss(size_average=False)
#直接定义优化器,而不是调用backward
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.99))
#调用参数初始化方法初始化网络参数
model.apply(weight_init)
#调用函数执行训练和测试
for epoch in range(1, 501):
print('----------------start train-----------------')
train(epoch)
print('----------------end train-----------------')
print('----------------start test-----------------')
test()
print('----------------end test-----------------')
LeNet论文下载
完整代码github地址:https://github.com/liuwei1206/deep-learning