莫烦Tensorflow教程(1~14)
一、Tensorflow结构
import tensorflow as tf
import numpy as np
#create data
x_data=np.random.rand(100).astype(np.float32)
y_data=x_data*0.1+0.3
#create tensorflow structure
Weights=tf.Variable(tf.random_uniform([1],-1.0,1.0)) #一维,范围[-1,1]
biases=tf.Variable(tf.zeros([1]))
y=Weights*x_data+biases
loss=tf.reduce_mean(tf.square(y-y_data))
#建立优化器,减小误差,提高参数准确度,每次迭代都会优化
optimizer=tf.train.GradientDescentOptimizer(0.5) #学习效率<1
train=optimizer.minimize(loss)
#初始化变量
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#train
for step in range(201):
sess.run(train)
if step%20==0:
print(step,sess.run(Weights),sess.run(biases))二、Session
import tensorflow as tf
matrix1 = tf.constant([[3, 3]])
matrix2 = tf.constant([[2], [2]])
# matrix multiply
# np.dot(m1,m2)
product = tf.matmul(matrix1, matrix2)
# # method 1
# sess = tf.Session() # Session是一个object,首字母要大写
# # 只有sess.run()之后,tensorflow才会执行一次
# result = sess.run(product)
# print(result)
# # close 不影响,会显得更整洁
# sess.close()
# method 2
# with 可以自己关闭会话
with tf.Session() as sess:
result2 = sess.run(product)
print(result2)
三、Variable
import tensorflow as tf
state=tf.Variable(0,name='counter')
# print(state.name)
# 变量+常量=变量
one=tf.constant(1)
new_value=tf.add(state,one)
#将state用new_value代替
updata=tf.assign(state,new_value)
#变量必须要激活
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(updata)
print(sess.run(state))
四、placeholder
运行到sess.run()的时候再给输入
利用feed_dict绑定
import tensorflow as tf
# 给定type,tf大部分只能处理float32数据
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# Tensorflow 1.0 修改版
# tf.mul---tf.multiply
# tf.sub---tf.subtract
# tf.neg---tf.negative
output = tf.multiply(input1, input2)
with tf.Session() as sess:
# placeholder在sess.run()的时候传入值
print(sess.run(output, feed_dict={input1: [7.], input2: [2.]}))
五、激励函数
解决非线性问题
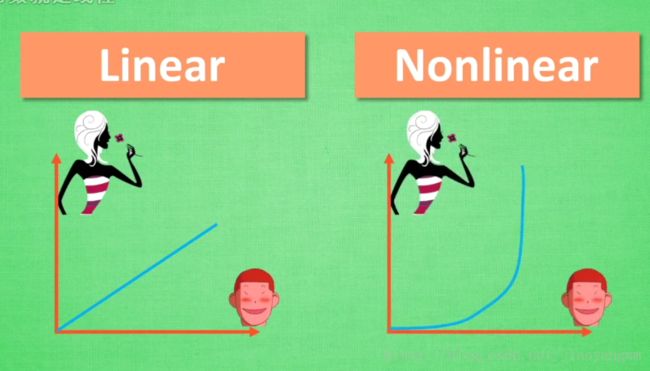
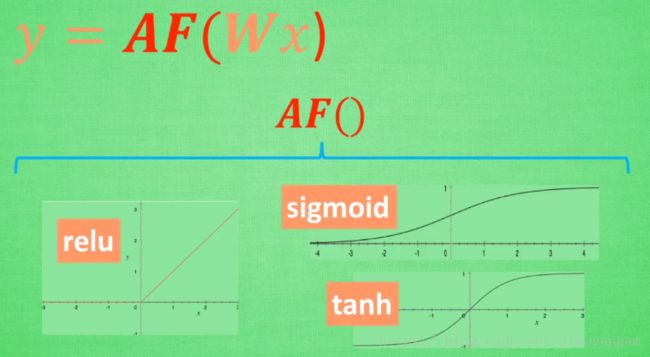
要求:必须可微分
简单的神经网络一般可以使用任何激励函数;
复杂的神经网络不能随意选择,会造成梯度爆炸和梯度消失的问题;
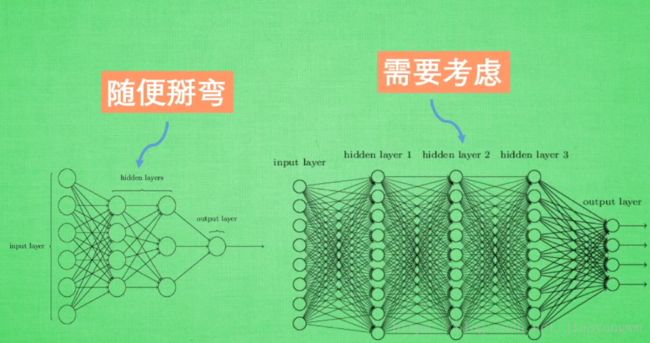
如何选择
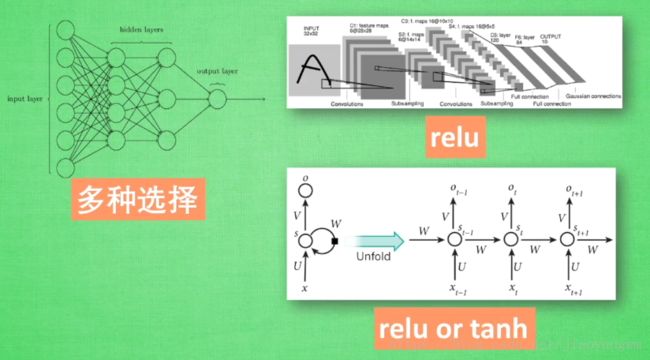
简述激励函数:
让某一部分的神经元先激活,传到后面的神经元,不同的神经元对不同的特征敏感。
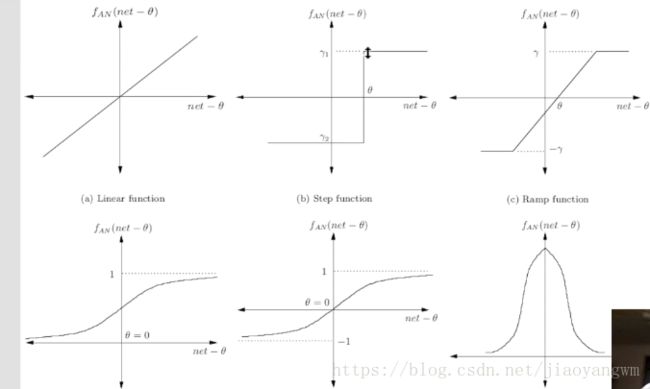
激活函数的输出:
激活 / 抑制
一般的神经网络:
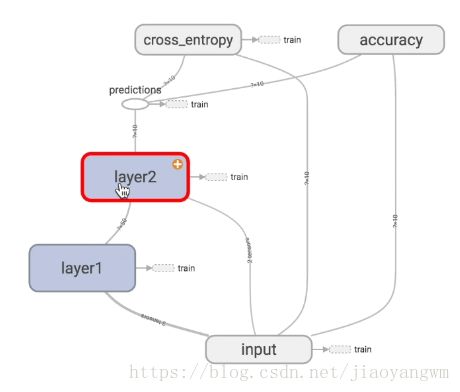
激活函数就在layer2中
六、添加层
import tensorflow as tf
import numpy as np
def add_layer(inputs,in_size,out_size,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
七、构建一个神经网络
import tensorflow as tf
import numpy as np
def add_layer(inputs,in_size,out_size,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
# (-1,1)之间,有300个单位,后面的是维度,x_data是有300行(300个例子)
x_data=np.linspace(-1,1,300)[:,np.newaxis]
# 加噪声,均值为0,方差为0.05,大小和x_data一样
noise=np.random.normal(0,0.05,x_data.shape)
y_data=np.square(x_data)-0.5+noise
xs=tf.placeholder(tf.float32,[None,1])
ys=tf.placeholder(tf.float32,[None,1])
"""建立网络"""
#定义隐藏层,输入1个节点,输出10个节点
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)
#定义输出层
prediction=add_layer(l1,10,1,activation_function=None)
"""预测"""
#损失函数,算出的是每个例子的平方,要求和(reduction_indices=[1],按行求和),再求均值
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#优化算法,minimize(loss)以0.1的学习率对loss进行减小
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50==0:
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
八、可视化
import tensorflow as tf
import numpy as np
import matplotlib.pylab as plt
def add_layer(inputs,in_size,out_size,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
# (-1,1)之间,有300个单位,后面的是维度,x_data是有300行(300个例子)
x_data=np.linspace(-1,1,300)[:,np.newaxis]
# 加噪声,均值为0,方差为0.05,大小和x_data一样
noise=np.random.normal(0,0.05,x_data.shape)
y_data=np.square(x_data)-0.5+noise
xs=tf.placeholder(tf.float32,[None,1])
ys=tf.placeholder(tf.float32,[None,1])
"""建立网络"""
#定义隐藏层,输入1个节点,输出10个节点
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)
#定义输出层
prediction=add_layer(l1,10,1,activation_function=None)
"""预测"""
#损失函数,算出的是每个例子的平方,要求和(reduction_indices=[1],按行求和),再求均值
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#优化算法,minimize(loss)以0.1的学习率对loss进行减小
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
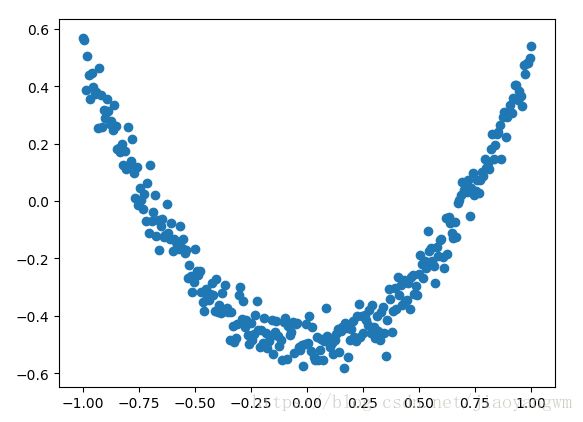
fig=plt.figure()
#连续性的画图
ax=fig.add_subplot(1,1,1)
ax.scatter(x_data,y_data)
# 不暂停
plt.ion()
# plt.show()绘制一次就会暂停
# plt.show() #也可以用plt.show(block=False)来取消暂停,但是python3.5以后提供了ion的功能,更方便
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50==0:
# print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
#尝试先抹除,后绘制第二条线
#第一次没有线,会报错,try就会忽略错误,然后紧接着执行下面的步骤
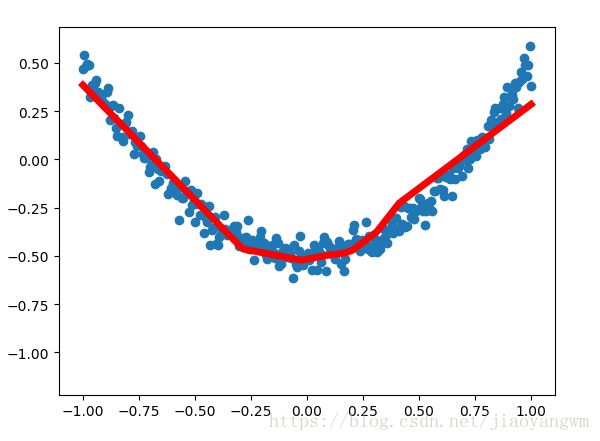
try:
# 画出一条后抹除掉,去除第一个线段,但是只有一个,也就是抹除当前的线段
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value=sess.run(prediction,feed_dict={xs:x_data})
lines=ax.plot(x_data,prediction_value,'r-',lw=5) #lw线宽
# 暂停0.1s
plt.pause(0.1)
九、加速神经网络训练
网络越复杂,数据越多,参数越多,训练时间越长,但是往往为了解决复杂的问题,网络复杂度高不可避免,所以要使用某些方法使得网络运行更快。
1. 随机梯度下降
2. 在参数更新上优化
3. 学习率
十、优化器
是对学习率的改变
从初始的cost慢慢走到最小cost的过程
十一、可视化 Tensorboard
1. Tensorboard安装:
pip install tensorboard2. 编程获得logs文件夹下的可视化文件
![]()
3. 进入cmd,到保存文件的路径下
cd E:\python\mofan Tensorflow\logs4. 启动Tensorboard
Tensorboard --logdir=logs天呐,不知道哪天手残把系统变量的Path给删除了,整了一晚上安装Tensorboard都出错,终于发现了是Path的问题,以后还是乖乖的,啥也不敢删除了。
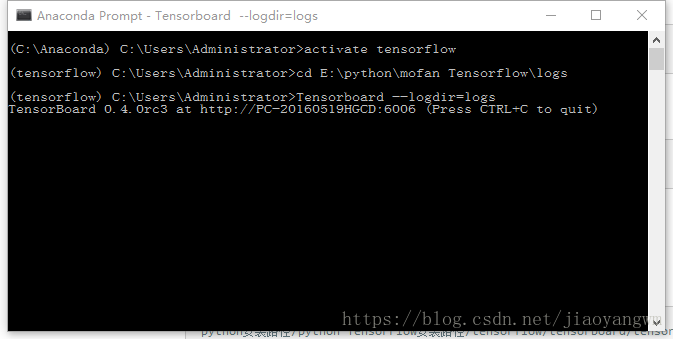
如何复制其中的内容?
1)右键上面的空白边,出现下面界面:
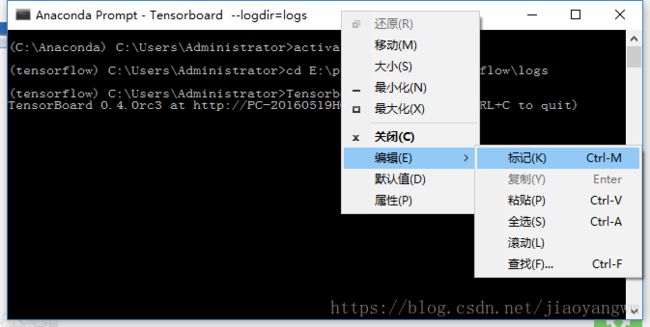
2)点击“标记”
3)选中,点击“Enter”,就复制了
http://PC-20160519HGCD:6006最好使用google chrome打开网址,即可看到graphs。
十二、分类学习
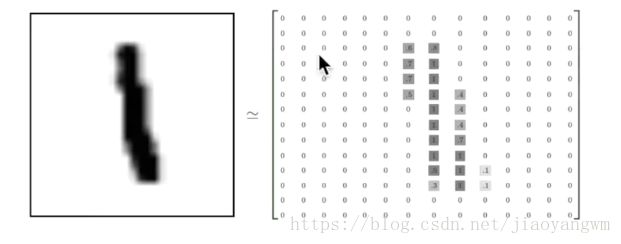
28*28=784个数据点,也就是x输入的大小
总共0~9,也就是y输出的大小
代表3:![]()
黑色格子表示为分类结果:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
def add_layer(inputs,in_size,out_size,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
def compute_accuracy(v_xs,v_ys):
#全局变量
global prediction
#生成预测值,也就是概率,即每个数字的概率
y_pre=sess.run(prediction,feed_dict={xs:v_xs})
#对比预测的数据是否和真实值相等,对比位置是否相等,相等就对了
correct_prediction=tf.equal(tf.arg_max(y_pre,1),tf.arg_max(v_ys,1))
#计算多少个对,多少个错
#tf.cast(x,dtype),将x数据转换为dtype类型
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})
return result
# define placeholder for inputs to networks
# 不规定有多少个sample,但是每个sample大小为784(28*28)
xs=tf.placeholder(tf.float32,[None,784])
ys=tf.placeholder(tf.float32,[None,10])
#add output layer
prediction=add_layer(xs,784,10,activation_function=tf.nn.softmax)
#the error between prediction and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
train_strp=tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(2000):
batch_xs,batch_ys=mnist.train.next_batch(100)
sess.run(train_strp,feed_dict={xs:batch_xs,ys:batch_ys})
if i%50==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
结果:
0.1415
0.6516
0.751
0.7875
0.8115
0.8247
0.837
0.8403
0.8448
0.8532
0.8585
0.8594
0.8618
0.8631
0.8644
0.098
0.098
0.098
十三、过拟合
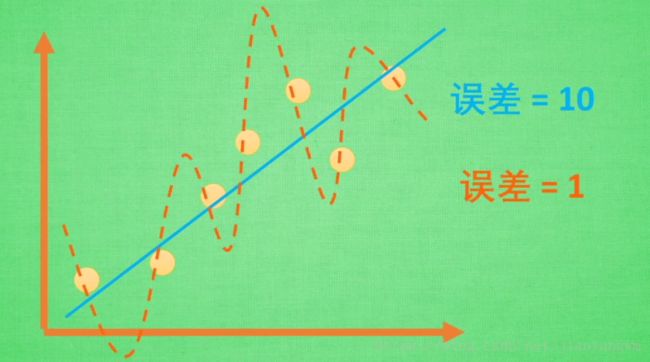
分类中的过拟合:
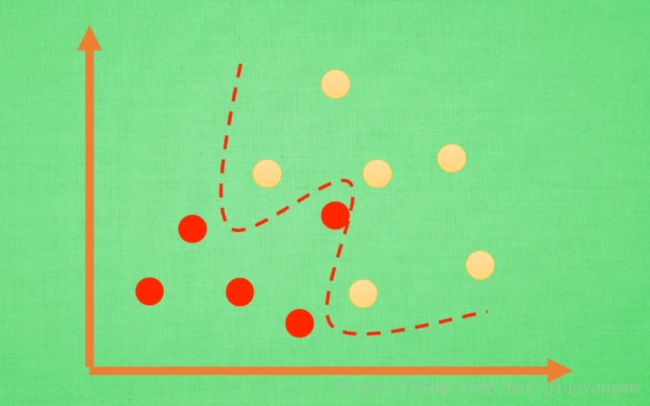
实际:

对十字形的新数据分类错误
解决方法:
1)增加数据量
过拟合的原因是模型复杂度和数据量不匹配,也就是数据量太小

当数据量增大时,红线被拉直,没有那么扭曲

2)正则化
W W 表示要学习的参数,过拟合中 W W 往往变化比较大,为了不让 W W 变化太大,在原始误差集上做些改变,即如果 W W 变化太大,则让cost的变化也变大。

3)专门用于神经网络的训练方法:Dropout regularization
第一次训练:随机去掉神经网络节点和网络连接:
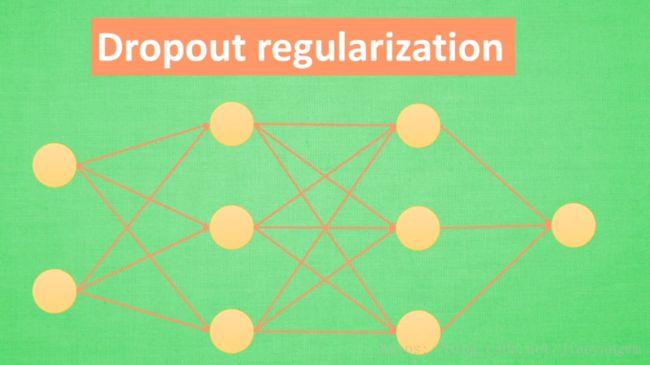
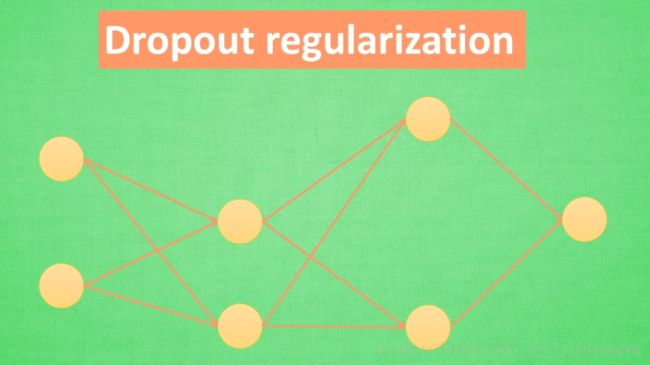
第二次训练:再次随机去掉一些参数
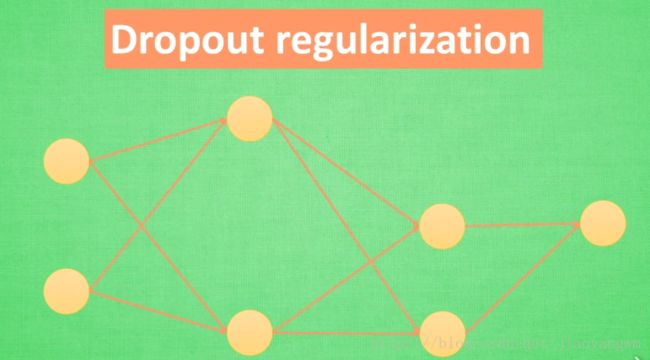
意义:每一次预测的结果都不会依赖于某部分特定的神经元,例如Regularization,当过度依赖某些 W W ,这些 W W 的数值会很大,L1/L2会惩罚大的参数,而Dropout是从根本上不让其过度依赖某些神经元。
十四、Dropout解决over-fitting
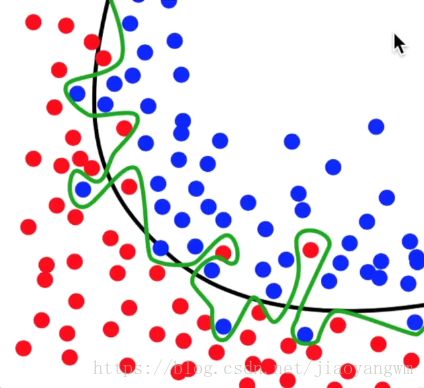
黑色的线是理想的分割线,绿色的曲线就是过拟合的曲线,所以要避免让机器学习学到绿色的线
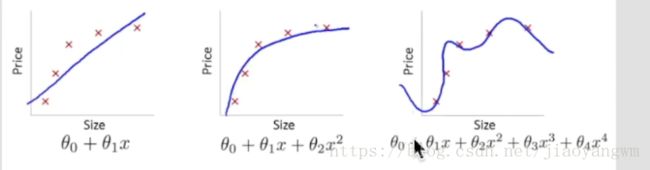
- 第一条是直线拟合,没有很好的拟合效果,underfit
- 第二条效果较好,just right
- 第三条是过拟合,over-fitting
Tensorflow解决overfitting——dropout
Summary:所有需要在TensorBoard上展示的统计结果。
tf.name_scope():为Graph中的Tensor添加层级,TensorBoard会按照代码指定的层级进行展示,初始状态下只绘制最高层级的效果,点击后可展开层级看到下一层的细节。
tf.summary.scalar():添加标量统计结果。
tf.summary.histogram():添加任意shape的Tensor,统计这个Tensor的取值分布。
tf.summary.merge_all():添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op。
tf.summary.FileWrite:用于将Summary写入磁盘,需要制定存储路径logdir,如果传递了Graph对象,则在Graph Visualization会显示Tensor Shape Information。执行summary op后,将返回结果传递给add_summary()方法即可。
未使用dropout:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#load data
digits=load_digits()
#0~9的图像
X=digits.data
#y是binary的,表示数字1,就在第二个位置放上1,其余都为0
y=digits.target
y=LabelBinarizer().fit_transform(y)
#切分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=3)
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
# 下面的表示outputs的值
tf.summary.histogram(layer_name+'/outputs',outputs)
return outputs
#define placeholder for inputs to network
xs=tf.placeholder(tf.float32,[None,64])
ys=tf.placeholder(tf.float32,[None,10])
#add output layer
# l1为隐藏层,为了更加看出overfitting,所以输出给了100
l1=add_layer(xs,64,100,'l1',activation_function=tf.nn.tanh)
prediction=add_layer(l1,100,10,'l2',activation_function=tf.nn.softmax)
#the error between prediction and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
#添加标量统计结果
tf.summary.scalar('loss',cross_entropy)
train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op
merged=tf.summary.merge_all()
#summary writer goes in here
train_writer=tf.summary.FileWriter("logs/train",sess.graph)#train为log的子文件夹
test_writer=tf.summary.FileWriter("logs/test",sess.graph)
for i in range(500):
sess.run(train_step,feed_dict={xs:X_train,ys:y_train})
if i%50==0:
#record loss
train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test})
train_writer.add_summary(train_result,i)
test_writer.add_summary(test_result,i)
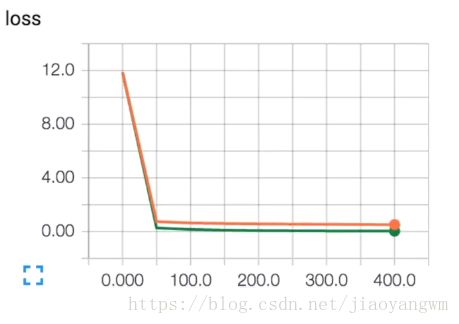
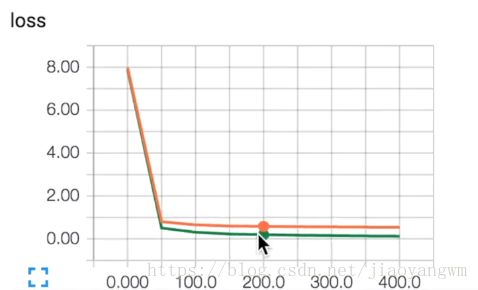
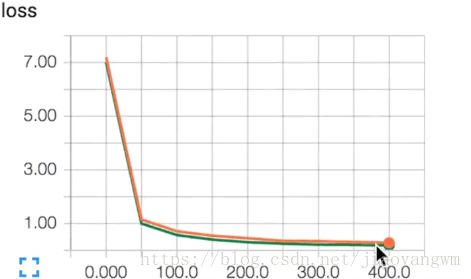
红色:testdata
绿色:trainingdata
使用dropout:
当train_result=sess.run(merged,feed_dict{xs:X_train,ys:y_train,keep_prob:1})时,也就是训练数据未使用dropout时,仍然有过拟合
当train_result=sess.run(merged,feed_dict{xs:X_train,ys:y_train,keep_prob:0.5})时,两者拟合的很好
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#load data
digits=load_digits()
#0~9的图像
X=digits.data
#y是binary的,表示数字1,就在第二个位置放上1,其余都为0
y=digits.target
y=LabelBinarizer().fit_transform(y)
#切分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=3)
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None):
#Weights是一个矩阵,[行,列]为[in_size,out_size]
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布
#初始值推荐不为0,所以加上0.1,一行,out_size列
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
#Weights*x+b的初始化的值,也就是未激活的值
Wx_plus_b=tf.matmul(inputs,Weights)+biases
#dropout 主功能,drop掉50%的结果,输出更新后的结果
Wx_plus_b=tf.nn.dropout(Wx_plus_b,keep_prob)
#激活
if activation_function is None:
#激活函数为None,也就是线性函数
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
# 下面的表示outputs的值
tf.summary.histogram(layer_name+'/outputs',outputs)
return outputs
#define placeholder for inputs to network
"""dropout"""
# 确定保留多少结果不被舍弃掉
keep_prob=tf.placeholder(tf.float32)
xs=tf.placeholder(tf.float32,[None,64])
ys=tf.placeholder(tf.float32,[None,10])
#add output layer
# l1为隐藏层,为了更加看出overfitting,所以输出给了100
l1=add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh)
prediction=add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax)
#the error between prediction and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
#添加标量统计结果
tf.summary.scalar('loss',cross_entropy)
train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op
merged=tf.summary.merge_all()
#summary writer goes in here
train_writer=tf.summary.FileWriter("logs/train",sess.graph)#train为log的子文件夹
test_writer=tf.summary.FileWriter("logs/test",sess.graph)
for i in range(500):
# drop掉60%,保持40%不被drop掉
sess.run(train_step,feed_dict={xs:X_train,ys:y_train,keep_prob:0.4})
if i%50==0:
#record loss(不要drop掉任何东西,所以为1)
train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train,keep_prob:0.5})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test,keep_prob:1})
train_writer.add_summary(train_result,i)
test_writer.add_summary(test_result,i)