中文评价对象提取以及NLP基础
前言
在CNCC开会的时候,收到一个问询:中文评价对象抽取的方法和开源工具。一番谷歌度娘论文阅读,撰文如下,欢迎指正。
任务界定
情感分析主要是针对主观性文本单元自动获取有价值的意见信息,是一个新颖且非常有应用价值的研究课题[1]。评价对象抽取和倾向性分析属于情感分析的两个子任务。
一句商品评论如:为发烧而生的手机,非常的亲民,速度非常的快,手感很轻柔,很舒服。摄像效果惊人,夜景效果非常的好,小米係统的很多功能我正在探索中,很好玩。是一款低调奢华有内涵的好手机,为雷军大赞。为京东的快递小哥也点个满意的赞。

抽取结果:
目标对象:小米手机(银3GB 64GB)
评价对象:(速度)快,(手感)轻柔,(摄像效果)好……
倾向性:五星好评
解决方案
基线方案
以2010年刘鸿宇等的工作[1](研究情感句中的评价对象抽取及其情感倾向性判断任务; 作为基础入门,哈工大的综述文本情感分析值得[2]强烈推荐)作为传统解决方案的例子。刘将任务分为两个主要阶段:
1. 自动识别情感句中的评价对象
2. 判别情感句中评价对象的情感倾向性
刘鸿宇等认为于评价对象的获取,已有的方法主要可以归为两类:人工构建[3]和关联规则挖掘[4-5]
判断情感极性主要是:有监督方法(Kim和Hovy使用词、位置以及情感词三类特征来对情感句进行分类[6]、赵军等人使用CRF和冗余标签对句子序列进行情感倾向性标注[7])、无监督方法(基于句法规则的方法[3,5])
刘等采用的是无监督的方法,在第一届中文倾向性分析评测取得优秀结果。系统框架图如下所示
刘的大体思路是:
1使用句法分析,找出名词和名词短语作为候选的评价对象
2使用三种过滤技术(词频过滤、PMI过滤、名词裁剪)削减候选集合,主要思路还是设置不同的阈值依靠出现频率和共现频率删除候选集(不停的试错)
3句子划分成四类,基于规则,比如情感词的的级性、数量(否定词)、上下文级性。
句子带有明显的倾向性,即句子中带有一种倾向性的上下文无关情感词明显多于另一种
句子不带有明显的倾向性,但句子中含有情感词,且褒义和贬义情感词的个数相同
句子不带有明显的倾向性,且句子中没有情感词,但其上下文的句子带有明显倾向性
句子不带有明显的倾向性,句子中没有情感词,且其上下文的句子也不带有明显倾向性
结果分析
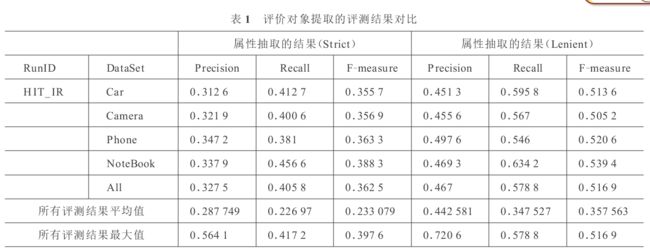
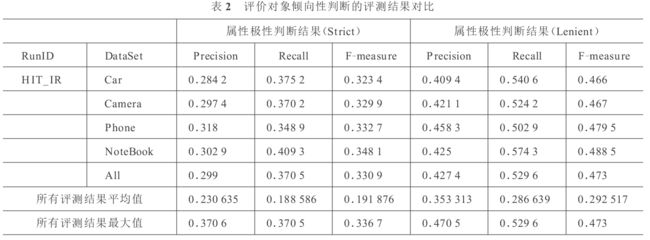

其中的Strict表示评价对象完全重合,Lenient表示评价对象部分重合,例如摄影效果和摄影。
评价:总的来说,作为基线模型,本模型使用的是大量的人工阈值,容易复现,没有使用机器学习算法,比如SVM分类。不过本文的数据集一共只有473个篇章,3,000个句子,却有10,000个评价对象,有监督学习不一定足够充分。
提升方案
提升思路:大规模语料库、强力句法分析器、词向量、特征工程、有监督分类算法。后续的nlp&cc 2012的测评任务基本上用的都是有监督学习的思路。


一个使用CRFS的评价对象提取方案例子如下
郑敏洁,雷志城,廖祥文,陈国龙. 基于层叠CRFs的中文句子评价对象抽取[J]. 中文信息学报,2013,03:69-76.
COAE中文倾向性分析评测
一共举行了七届,目前第八届COAE报名已经截止
第六届COAE2014评测在前五届中文倾向性分析评测的基础上,重点对情感关键句、跨语言情感分析、微博情感新词、微博倾向性、微博观点要素识别进行评测。与往年评测的一个不同点是,COAE2014的评测技术论文需按照CCIR2014的要求与格式来撰写,并向CCIR2014投稿,数据集下载。COAE2015的相关测评参考:HITSCIR_Run:COAE2015微博观点句识别任务分析系统
开源工具
HanLP
是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
中文分词:最短路分词 N-最短路分词 CRF分词 索引分词 极速词典分词 用户自定义词典
词性标注
命名实体识别:中国人名识别 音译人名识别 日本人名识别 地名识别 实体机构名识别
关键词提取:TextRank关键词提取 自动摘要 TextRank自动摘要 短语提取 基于互信息和左右信息熵的短语提取
拼音转换 多音字 声母 韵母 声调
简繁转换 繁体中文分词 简繁分歧词(简体、繁体、臺灣正體、香港繁體)
文本推荐 语义推荐 拼音推荐 字词推荐
依存句法分析:基于神经网络的高性能依存句法分析器 MaxEnt依存句法分析 CRF依存句法分析
语料库工具:分词语料预处理 词频词性词典制作 BiGram统计 词共现统计 CoNLL语料预处理 CoNLL UA/LA/DA评测工具
主页地址:https://github.com/hankcs/HanLP
TweetNLP
http://www.cs.cmu.edu/~ark/TweetNLP/
针对英文的词性标注工具,里面的句子特征提取部分非常具有借鉴意义,代码撰写规范,学习CRFs的童鞋可以边看代码边读作者的论文。
Jieba分词
官网:http://www.oschina.net/p/jieba
代码:https://github.com/fxsjy/jieba
中文分词、关键词提取和词性标注的工具
NLTK
目前具有霸主地位的一个NLP大全工具,斯坦福大学自然语言处理组是世界知名的NLP研究小组,他们提供了一系列开源的Java文本分析工具,包括分词器(Word Segmenter),词性标注工具(Part-Of-Speech Tagger),命名实体识别工具(Named Entity Recognizer),句法分析器(Parser)等,可喜的事,他们还为这些工具训练了相应的中文模型,支持中文文本处理。
http://www.nltk.org/
语料库
强烈推荐:http://www.36dsj.com/archives/21118
国内外著名大学研究所提供的免费语料库 用于标注翻译以及其他自然语言任务
以下语料库链接转载自http://blog.csdn.net/u010708470/article/details/52749535?locationNum=7
Penn Treebank http://www.cis.upenn.edu/~treebank/home.html
WSJ Corpus https://catalog.ldc.upenn.edu/LDC2000T43
NEGRA German corpus http://www.coli.uni-saarland.de/projects/sfb378/negra-corpus/
Tiger corpus http://www.ims.uni-stuttgart.de/projekte/TIGER/TIGERCorpus/
alpino Treebank http://odur.let.rug.nl/~vannoord/trees/
Bultreebank http://www.bultreebank.org/
Turin University Treebank http://www.di.unito.it/~tutreeb/
prague dependency Treebank http://ufal.mff.cuni.cz/pdt2.0/
大而全的NLTK所有语料
NLTK Corpora http://www.nltk.org/nltk_data/
另外COAE每次测评任务的语料库,天池大赛、DataCastle比赛、今日头条比赛、搜狗比赛都有提供大量的文本资料(带标签)
未完待续
有时间再看看当下最新的测评(nlpcc等测评任务)用的有监督实现,把这篇文章补充完整。
推荐补充阅读:如何挖掘网民意见?评价对象抽取综述
翻译自 Liu B. Sentiment analysis and opinion mining[J]. Synthesis Lectures on Human Language Technologies, 2012, 5(1): 1-167.
总结
中文评价对象的抽取是情感分析的一个子任务,但不是像POS、分词和分块那样基础课题,一定要用CRFs、HMM之类序列标注算法,也不一定要用SVM、NN这样的分类算法。它需要大量的特征工程再加以合适的分类或标注算法,例如上文13年的那篇CRFs的文章[8]。一般的流程包括文本预处理、特征抽取(词性特征、分块特征、ngram特征、上下文特征、词聚类特征、词向量)然后使用分类或标注算法(我猜测应该也有LSTM之类序列生成的算法直接生成评价对象)。
[1]刘鸿宇,赵妍妍,秦兵,刘挺. 评价对象抽取及其倾向性分析[J]. 中文信息学报,2010,01:84-88+122.
[2]赵妍妍,秦兵,刘挺. 文本情感分析[J]. 软件学报,2010,08:1834-1848.
[3]姚天昉,等.一个用于汉语汽车评论的意见挖掘系统[C]//中文信息处理前沿进展—中国中文信息学会二十五周年学术会议论文集.北京:清华大学出版社,
2006: 260-280.[4]Minqing Hu,Bing Liu. Mining opinion features in customer reviews[ C]//Proceedings of AAAI-2004, 2004: 755-760.
[5]倪茂树,林鸿飞.基于关联规则和极性分析的商品评论挖掘[C]//第三届全国信息检索与内容安全学术会议,2007: 635-642.
[6]Soo-Min Kim,Eduard Hovy. Automatic detection of opinion bearing words and sentences[C]//Proceedings of IJCNLP-2005,2005: 61-66.
[7]Jun Zhao,Kang Liu,GenWang. Adding redundant features for crfs-based sentence sentiment classification [C]//Proceedings of the 2008 Conference on EmpiricalMethods in Natural Language Processing, 2008:117-126.
[8]郑敏洁,雷志城,廖祥文,陈国龙. 基于层叠CRFs的中文句子评价对象抽取[J]. 中文信息学报,2013,03:69-76.