目标检测算法(二)——具体原理以及实现
一、光流法
1.1光流法原理
光流的概念是Gibson在1950年首先提出来的。它是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。一般而言,光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。其计算方法可以分为三类:
(1)基于区域或者基于特征的匹配方法;
(2)基于频域的方法;
(3)基于梯度的方法;
简单来说,光流是空间运动物体在观测成像平面上的像素运动的“瞬时速度”。光流的研究是利用图像序列中的像素强度数据的时域变化和相关性来确定各自像素位置的“运动”。研究光流场的目的就是为了从图片序列中近似得到不能直接得到的运动场。
光流法的前提假设:
(1)相邻帧之间的亮度恒定;
(2)相邻视频帧的取帧时间连续,或者,相邻帧之间物体的运动比较“微小”;
(3)保持空间一致性;即,同一子图像的像素点具有相同的运动
这里有两个概念需要解释:
运动场,其实就是物体在三维真实世界中的运动;
光流场,是运动场在二维图像平面上的投影。

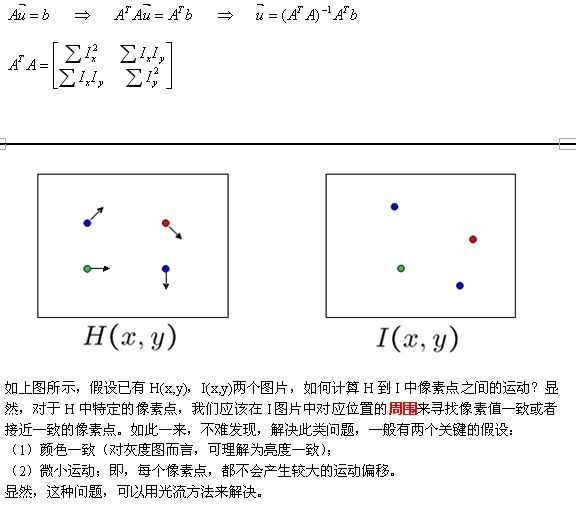

如上图所示,H中的像素点(x,y)在I中的移动到了(x+u,y+v)的位置,偏移量为(u,v)。
光流法用于目标检测的原理:给图像中的每个像素点赋予一个速度矢量,这样就形成了一个运动矢量场。在某一特定时刻,图像上的点与三维物体上的点一一对应,这种对应关系可以通过投影来计算得到。根据各个像素点的速度矢量特征,可以对图像进行动态分析。如果图像中没有运动目标,则光流矢量在整个图像区域是连续变化的。当图像中有运动物体时,目标和背景存在着相对运动。运动物体所形成的速度矢量必然和背景的速度矢量有所不同,如此便可以计算出运动物体的位置。需要提醒的是,利用光流法进行运动物体检测时,计算量较大,无法保证实时性和实用性。
光流法用于目标跟踪的原理:
(1)对一个连续的视频帧序列进行处理;
(2)针对每一个视频序列,利用一定的目标检测方法,检测可能出现的前景目标;
(3)如果某一帧出现了前景目标,找到其具有代表性的关键特征点(可以随机产生,也可以利用角点来做特征点);
(4)对之后的任意两个相邻视频帧而言,寻找上一帧中出现的关键特征点在当前帧中的最佳位置,从而得到前景目标在当前帧中的位置坐标;
(5)如此迭代进行,便可实现目标的跟踪;
1.2 光流法实现
1.2.1、opencv下的光流L-K算法
opencv的光流实现由好几个方法可以(也就是说有好几个函数可以用),每个函数当然也对应着不同的原理,那么它的效果以及算法的速度等等就会有一些差别。主要包括以下几种:
calcOpticalFlowPyrLK
calcOpticalFlowFarneback
calcOpticalFlowBM
calcOpticalFlowHS
calcOpticalFlowSF
参见opencv文档介绍
这里先简单介绍下calcOpticalFlowPyrLK函数
calcOpticalFlowPyrLK函数使用形式:
calcOpticalFlowPyrLK(prevImg,nextImg,prevPts,nextPts,status,err)
这个函数还有一些可选参数,一大堆,详细的说明可以看opencv介绍:
这里只是贴出了主要的几个输入输出:
prevImg:就是你需要输入计算光流的前一帧图像
nextImg就是下一帧图像(可以看到一次光流就是在两针图像之间找不同)。
prevPts是前一帧图像中的特征点,这个特征点必须自己去找,所以在使用calcOpticalFlowPyrLK函数的时候,前面需要有一个找特征点的操作,那么一般就是找图像的角点,就是一个像素点与周围像素点都不同的那个点,这个角点特征点的寻找,opencv也提供夜歌函数:goodFeatureToTrack()(后面再介绍这个函数)。那么关于特征点有没有其他的方式呢?肯定是有的而且还很多吧。
nextPts参数就是计算特征点在第二幅图像中的新的位置,然后输出。特征点的新位置可能变化了,也可能没有变化,那么这种状态就存放在后一个参数status中。err就是新旧两个特征点位置的误差了,也是一个输出矩阵。
其他参数默认吧。
关于特征角点检测函数goodFeatureToTrack()
goodFeaturesToTrack(image,corners,maxCorners,qualityLevel,minDistance)
函数的参数:
image输入图像;
corners输出的特征点系列,每一个元素就是一个特征点的位置。
maxCorners规定的特征点最大数目,比如一副图像你可以找到很多特征点,但是只是取前maxCorners个具有最大特征的那些点作为最后的特征点,至于怎么判断哪些点的特征更好了,opencv自有一个机制,随便一个方法,比如计算一下这个点与周围一定领域的点的灰度相差求和,认为这个和越大的那些点是不是越属于特征点。
qualityLevel是一个特征点的取到水平,其实也是控制特征点的选取的,看结果适当选取吧。
minDistance是特征点与点之间的最小距离,一般我们如果想特征点尽量分散一些,太密集了肯定不好,那么我们可以通过这个参数。
比如说一个例子如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
修改下 int maxCout = 100;//定义最大个数
double minDis = 10;//定义最小距离

下面通过这种特征点来以及L-K光流法来检测两幅相邻帧图像之间的移动点。首先自己准备两幅图吧,图中要有运动的目标才好,然后我们就这两幅图简单的看下里面的运动目标的特征点的运动吧,一个简单程序如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50

我的这两幅树叶图是存在这一些变化的,尤其树存在的地方,由于需要动态的来回切换着看才能看出变化,所以这里不太好显示这两幅图的变化,这里吧他们相差的图做出来如下:

可以看到的是越白的地方就是存在着不一致,也就是存在着明显运动的地方。和上面角点检测的还是有点符合的。
当然,我这可能只是连续两帧运动情况下的跟踪的特征点,如果是一个视频(连续的很多帧),那么把每两帧之间的运动点连接起来,就可以发现运动的物体的整个轨迹了。像网上博客有人做过的贴几个: Opencv学习笔记(九)光流法
1.2.2、opencv下光流Farneback法
上节说到过的calcOpticalFlowPyrLK光流算法,可以看到它实际上是一种稀疏特征点的光流算法,也就是说我们先找到那些(特征)点需要进行处理,然后再处理,该节介绍下一个全局性的密集光流算法,也就是对每一个点都进行光流计算,函数为calcOpticalFlowFarneback。
首先介绍参数,详细的介绍 参见OpenCV手册
参数一大推,得看一会。有些参数可能带来的影响不是很大,那么使用它推荐的参数即可。完整的参数达10个。按顺序:
prevImg:输入第一个图
nextImg:输入第二个图
Flow:输出的光流矩阵。矩阵大小同输入的图像一样大,但是矩阵中的每一个元素可不是一个值,而是两个值,分别表示这个点在x方向与y方向的运动量(偏移量)。所以要把这个光流场矩阵显示出来还真的需要费点力。那么上面说的两幅图像与这个光流场是什么关系呢?如下:
![]()
pyrScale:一个构造图像金字塔的参数,一般就认为是0.5最好了,也就是将图像缩小一半。那么为什么要构造金字塔呢?这应该是与算法本身的设计有关,其实很多地方在检测特征的时候都会涉及到图像的金字塔,设想下如果有个特征点在原始尺寸与其缩小的尺寸下都是特征点的话,那么这个特征点就很有效了吧。
Levels:依然是与金字塔有关参数,常设值1.
Winsize:相当于一个均值滤波的作用,窗口大小决定了其噪声的抑制能力什么的。
Iterations:在每层金字塔上的迭代次数。
polyN:点与附近领域点之间的联系作用,一般为5,7等等即可。
polySigma :像素点的一个平滑水平,一般1-1.5即可。
Flags:一个标记,决定计算方法。
具体怎么影响结果的,可以自己去尝试。
下面对上节使用到的两幅图,通过这个方法来计算这两帧图像中存在的光流场,也就是把上述的Flow找出来,那些参数也决定了Flow找出来的不一样。简单的程序如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
可以看到程序的大部分是在如何把计算的光流flow可视化出来,虽然我们已经知道它是一个矩阵,而且矩阵中每个元素都包括2个值。但是显示出来也比较费劲,显示的函数是参考博客:
光流Optical Flow介绍与OpenCV实现
该博客里面的内容也是值得一看的。
那么我们这里的一个结果如下(原始图见上篇):
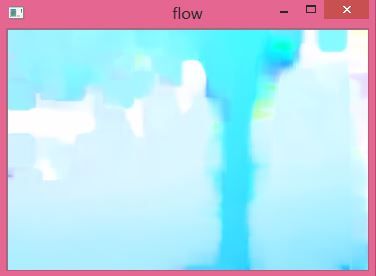
颜色越深表示该部分存在的运动变化越大。
早点版本(3.0之前)的OpenCV中还有好几个光流计算函数,什么块匹配BM法,HS法,LK法等等,每一种方法几乎都对应一篇相关文章而来。后几种方法的结果无非也都是计算出光流场(在x方向的光流与在y方向的光流)。3.0的opencv似乎把块匹配、HS等方法舍弃了?没有找到,想使用那些方法的恐怕还要使用以前的opencv版本才行
二、背景减法
1、原理
对于一个稳定的监控场景而言,在没有运动目标,光照没有变化的情况下,视频图像中各个像素点的灰度值是符合随机概率分布的。由于摄像机在采集图像的过程中,会不可避免地引入噪声,这些灰度值以某一个均值为基准线,在附近做一定范围内的随机振荡,这种场景就是所谓的“背景”。
背景减法(Background subtraction)是当前运动目标检测技术中应用较为广泛的一类方法,它的基本思想和帧间差分法相类似,都是利用不同图像的差分运算提取目标区域。不过与帧间差分法不同的是,背景减法不是将当前帧图像与相邻帧图像相减,而是将当前帧图像与一个不断更新的背景模型相减,在差分图像中提取运动目标。

背景减法的运算过程如图2-6所示。首先利用数学建模的方法建立一幅背景图像帧B,记当前图像帧为fn,背景帧和当前帧对应像素点的灰度值分别记为B(x,y )和fn(x , y ) ,按照式2.17将两帧图像对应像素点的灰度值进行相减,并取其绝对值,得到差分图像D n:
![]()
设定阈值 T ,按照式2.18逐个对像素点进行二值化处理,得到二值化图像 Rn' 。其中,灰度值为255的点即为前景(运动目标)点,灰度值为0的点即为背景点;对图像 Rn'进行连通性分析,最终可得到含有完整运动目标的图像Rn 。
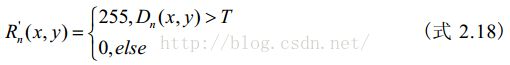
背景减法计算较为简单,由于背景图像中没有运动目标,当前图像中有运动目标,将两幅图像相减,显然可以提取出完整的运动目标,解决了帧间差分法提取的目标内部含有“空洞”的问题。
利用背景减法实现目标检测主要包括四个环节:背景建模,背景更新,目标检测,后期处理。其中,背景建模和背景更新是背景减法中的核心问题。背景模型建立的好坏直接影响到目标检测的效果。所谓背景建模,就是通过数学方法,构建出一种可以表征“背景”的模型。获取背景的最理想方法是在没有运动目标的情况下获取一帧“纯净”的图像作为背景,但是,在实际情况中,由于光照变化、雨雪天气、目标运动等诸多因素的影响,这种情况是很难实现。
2、背景建模
2.1 多阵平均法
当实际的监控场景不是太复杂时,可以采用多帧平均法建立背景模型。多帧平均法实质上是一种统计滤波的思想。在一段时间内,将采集到的多帧图像相加,求其平均值,这个平均值就作为参考的背景模型。具体计算式如下:
![]()
上式中,Bn为采集到第n帧图像时系统建立的背景模型,N为进行平均的帧数,(fn,fn− 1 ...fn− N +1 ) 为包含当前帧在内的系统所保存的连续N帧图像。由于受到场景中光照变化等因素的影响,得到的背景模型Bn 每隔一段时间需要更新一次,更新计算式为:
![]()
式2.20说明新的一帧背景模型可以由上一次计算得到的背景模型Bn−1、当前帧fn以及fn -N帧递推得到,这样就实现了背景模型的更新。显然,N值越大,得到的背景模型Bn就越接近于真实背景。

图 2-7 是采用多帧平均法对标准序列 hall 序列进行目标检测的实验结果。观察图(b)可以发现,使用多帧平均法提取背景图像,当场景中存在运动目标时,提取的背景中会存在“鬼影”(ghosts),这是由目标在连续多帧图像中的运动造成的。当N值增大时,“鬼影”效应会有所减弱,但是很难消除。
多帧平均法计算方法简单,对场景中背景变化的适应性较好,但是该方法需要保存前N帧图像信息,增加了系统的开销,特别是在实时监控系统中,这样大的内存开销是很浪费的。因此,多帧平均法在实际的监控系统中应用较少。
使用统计的方法实现背景建模及运动目标检测是当前目标检测方法中效果较好的一类方法。该类方法利用统计值表征背景,建立背景模型。
不同的监控场景有着不同的特性,背景模型因此分为单模态和多模态两种。单模态的场景中,每个背景像素点的颜色值分布比较集中,可以用单一分布的概率模型来描述背景;而在多模态的场景中,每个背景像素点的颜色值分布非常分散,需要用多个分布的概率模型相拟合描述背景。在实际的场景中,由于光照变化、背景中轻微扰动(如户外场景中树枝的轻微摇摆)等因素的影响,背景模型往往是多模态的。

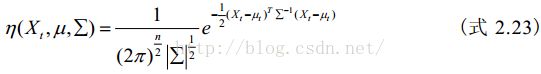
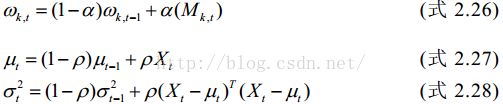

1、原理
摄像机采集的视频序列具有连续性的特点。如果场景内没有运动目标,则连续帧的变化很微弱,如果存在运动目标,则连续的帧和帧之间会有明显地变化。
帧间差分法(Temporal Difference)就是借鉴了上述思想。由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧或三帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。

两帧差分法的运算过程如图2-2所示。记视频序列中第n帧和第n−1帧图像为fn和fn−1,两帧对应像素点的灰度值记为fn(x,y)和fn−1(x , y),按照式2.13将两帧图像对应像素点的灰度值进行相减,并取其绝对值,得到差分图像Dn:
![]()
设定阈值T,按照式2.14逐个对像素点进行二值化处理,得到二值化图像Rn'。其中,灰度值为255的点即为前景(运动目标)点,灰度值为0的点即为背景点;对图像Rn'进行连通性分析,最终可得到含有完整运动目标的图像Rn。

2、三帧差分法
两帧差分法适用于目标运动较为缓慢的场景,当运动较快时,由于目标在相邻帧图像上的位置相差较大,两帧图像相减后并不能得到完整的运动目标,因此,人们在两帧差分法的基础上提出了三帧差分法。

三帧差分法的运算过程如图2-3所示。记视频序列中第n+1帧、第n帧和第n−1帧的图像分别为fn+1、fn和fn−1,三帧对应像素点的灰度值记为fn+1(x , y) 、fn(x , y) 和fn−1(x , y) , 按照式2.13分别得到差分图像Dn+1和Dn,对差分图像Dn+1和Dn按照式2.15进行与操作,得到图像Dn',然后再进行阈值处理、连通性分析,最终提取出运动目标。
![]()
在帧间差分法中,阈值 T 的选择非常重要。如果阈值T选取的值太小,则无法抑制差分图像中的噪声;如果阈值T选取的值太大,又有可能掩盖差分图像中目标的部分信息;而且固定的阈值T无法适应场景中光线变化等情况。为此,有人提出了在判决条件中加入对整体光照敏感的添加项的方法,将判决条件修改为:

其中, N A为待检测区域中像素的总数目,λ为光照的抑制系数,A可设为整帧图像。添加项![]() 表达了整帧图像中光照的变化情况。如果场景中的光照变化较小,则该项的值趋向于零;如果场景中的光照变化明显,则该项的值明显增大,导致式2.16右侧判决条件自适应地增大,最终的判决结果为没有运动目标,这样就有效地抑制了光线变化对运动目标检测结果的影响。
表达了整帧图像中光照的变化情况。如果场景中的光照变化较小,则该项的值趋向于零;如果场景中的光照变化明显,则该项的值明显增大,导致式2.16右侧判决条件自适应地增大,最终的判决结果为没有运动目标,这样就有效地抑制了光线变化对运动目标检测结果的影响。
3、两帧差分和三帧差分的比较
图 2-5 是采用帧间差分法对自拍序列 lab 序列进行运动目标检测的实验结果,(b)图是采用两帧差分法的检测结果,(c)图是采用三帧差分法的检测结果。lab序列中的目标运动较快,在这种情况下,运动目标在不同图像帧内的位置明显不同,采用两帧差分法检测出的目标会出现“重影”的现象,采用三帧差分法,可以检测出较为完整的运动目标。

综上所述,帧间差分法的原理简单,计算量小,能够快速检测出场景中的运动目标。但由实验结果可以看出,帧间差分法检测的目标不完整,内部含有“空洞”,这是因为运动目标在相邻帧之间的位置变化缓慢,目标内部在不同帧图像中相重叠的部分很难检测出来。帧间差分法通常不单独用在目标检测中,往往与其它的检测算法结合使用。