centos7下搭建hadoop、hbase、hive、spark分布式系统架构
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
如果想了解架构原理,可以参考:https://blog.csdn.net/luanpeng825485697/article/details/80319552
在使用前建议先将当前用户设置为root用户。参考https://blog.csdn.net/luanpeng825485697/article/details/80278383中修改用户权限的第三种方法。有了权限就会方便操作。
在根目录下创建文件夹/lp/hadoop,用来在这里面存放hadoop生态环境
分布式hadoop部署
首先,在http://hadoop.apache.org/releases.html找到最新稳定版tar包,我选择的是hadoop-2.7.3.tar.gz
下载解压到/lp/hadoop/hadoop-2.7.3
hdfs的架构:hdfs部分由NameNode、SecondaryNameNode和DataNode组成。DataNode是真正的在每个存储节点上管理数据的模块,NameNode是对全局数据的名字信息做管理的模块,SecondaryNameNode是它的从节点,以防挂掉。
最后再说map-reduce:Map-reduce依赖于yarn和hdfs,另外还有一个JobHistoryServer用来看任务运行历史
hadoop虽然有多个模块分别部署,但是所需要的程序都在同一个tar包中,所以不同模块用到的配置文件都在一起,让我们来看几个最重要的配置文件:
各种默认配置:core-default.xml, hdfs-default.xml, yarn-default.xml, mapred-default.xml
各种web页面配置:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml
从这些配置文件也可以看出hadoop的几大部分是分开配置的。
除上面这些之外还有一些重要的配置:hadoop-env.sh、mapred-env.sh、yarn-env.sh,他们用来配置程序运行时的java虚拟机参数以及一些二进制、配置、日志等的目录配置
下面我们真正的来修改必须修改的配置文件。
修改etc/hadoop/core-site.xml,把配置改成:
fs.defaultFS
hdfs://127.0.0.1:9001
io.file.buffer.size
131072
这里面配置的是hdfs的文件系统地址:本机的9001端口,你可以填如自己的hdfs的地址,可以是ip,也可以是域名,如果是域名保证这个域名可以被正确的解析到ip,可以在hosts文件添加一个域名映射。
修改etc/hadoop/hdfs-site.xml,把配置改成:
dfs.namenode.name.dir
file:///lp/hadoop/dfs/name
dfs.datanode.data.dir
file:///lp/hadoop/dfs/data
dfs.datanode.fsdataset.volume.choosing.policy
org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
dfs.namenode.http-address
127.0.0.1:8305
dfs.namenode.secondary.http-address
127.0.0.1:8310
这里面配置的是hdfs文件存储在本地的哪里以及secondary namenode的地址
修改etc/hadoop/yarn-site.xml,把配置改成:
yarn.resourcemanager.hostname
127.0.0.1
yarn.resourcemanager.webapp.address
127.0.0.1:8320
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
864000
yarn.log-aggregation.retain-check-interval-seconds
86400
yarn.nodemanager.remote-app-log-dir
/lp/hadoop/YarnApp/Logs
yarn.log.server.url
http://127.0.0.1:8325/jobhistory/logs/
yarn.nodemanager.local-dirs
/lp/hadoop/YarnApp/nodemanager
yarn.scheduler.maximum-allocation-mb
5000
yarn.scheduler.minimum-allocation-mb
1024
yarn.nodemanager.vmem-pmem-ratio
4.1
yarn.nodemanager.vmem-check-enabled
false
这里面配置的是yarn的日志地址以及一些参数配置
通过cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml创建etc/hadoop/mapred-site.xml,内容改为如下:
mapreduce.framework.name
yarn
Execution framework set to Hadoop YARN.
yarn.app.mapreduce.am.staging-dir
/lp/hadoop/YarnApp/tmp/hadoop-yarn/staging
mapreduce.jobhistory.address
127.0.0.1:8330
mapreduce.jobhistory.webapp.address
127.0.0.1:8331
mapreduce.jobhistory.done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done
mapreduce.jobhistory.intermediate-done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
mapreduce.jobhistory.joblist.cache.size
1000
mapreduce.tasktracker.map.tasks.maximum
8
mapreduce.tasktracker.reduce.tasks.maximum
8
mapreduce.jobtracker.maxtasks.perjob
5
The maximum number of tasks for a single job.
A value of -1 indicates that there is no maximum.
这里面配置的是mapred的任务历史相关配置
如果你的hadoop部署在多台机器,那么需要修改etc/hadoop/slaves,把其他slave机器ip加到里面,如果只部署在这一台,那么就留一个localhost即可。
如果hadoop分布式部署在多台机器上,每台机器上的部署都是一样的,都要知道master(主)的位置,每一个slaves(从)的位置。
下面我们启动hadoop,启动之前我们配置好必要的环境变量:
在hadoop-env.sh里写JAVA_HOME
export JAVA_HOME="你的java安装地址"
为这边写的是
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
这一部分下面的命令,需要在/lp/hadoop/hadoop-2.7.3目录下执行,可以在/lp/hadoop/hadoop-2.7.3目录下右健(在终端中打开),然后再执行下面的hadoop部署的命令
先启动hdfs,在此之前要格式化分布式文件系统,执行:
./bin/hdfs namenode -format myclustername
如果格式化正常可以看到/lp/hadoop/dfs下生成了name目录(如果格式化再次执行,之前的数据就不能用了。所以安装后只执行一次)
然后启动namenode,执行:
./sbin/hadoop-daemon.sh --script hdfs start namenode
如果正常启动,可以看到启动了相应的进程,并且/lp/hadoop/hadoop-2.7.3/logs目录下生成了相应的日志
然后启动datanode,执行:
./sbin/hadoop-daemon.sh --script hdfs start datanode
如果考虑启动secondary namenode,可以用同样的方法启动
下面我们启动yarn,先启动resourcemanager,执行:
./sbin/yarn-daemon.sh start resourcemanager
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
然后启动nodemanager,执行:
./sbin/yarn-daemon.sh start nodemanager
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
然后启动MapReduce JobHistory Server,执行:
./sbin/mr-jobhistory-daemon.sh start historyserver
下面我们看下web界面
打开http://127.0.0.1:8320/cluster看下yarn管理的集群资源情况(因为在yarn-site.xml中我们配置了yarn.resourcemanager.webapp.address是127.0.0.1:8320)
打开http://127.0.0.1:8331/jobhistory看下map-reduce任务的执行历史情况(因为在mapred-site.xml中我们配置了mapreduce.jobhistory.webapp.address是127.0.0.1:8331)
打开http://127.0.0.1:8305/dfshealth.html看下namenode的存储系统情况(因为在hdfs-site.xml中我们配置了dfs.namenode.http-address是127.0.0.1:8305)
到此为止我们对hadoop的部署完成。
以后再启动就不需要再输入这么多启动命令,只需要启动start-dfs.sh和start-yarn.sh就可以了,他们会自动启动namenode、datanode、secondarynamenode,和 resourcemanager、nodemanager。
[root@localhost hadoop-2.7.3]# ./sbin/start-dfs.sh
自动启动namenode、datanode、secondarynamenode。
Starting namenodes on [localhost]
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is 1e:64:5d:6d:26:40:c9:3e:14:0a:5f:50:6f:2f:3f:52.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
root@localhost's password:
localhost: starting namenode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-namenode-localhost.out
root@localhost's password:
localhost: starting datanode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [localhost]
root@localhost's password:
localhost: starting secondarynamenode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-localhost.out
[root@localhost hadoop-2.7.3]# ./sbin/start-yarn.sh
自动启动 resourcemanager、nodemanager。
starting yarn daemons
starting resourcemanager, logging to /lp/hadoop/hadoop-2.7.3/logs/yarn-root-resourcemanager-localhost.out
root@localhost's password:
localhost: starting nodemanager, logging to /lp/hadoop/hadoop-2.7.3/logs/yarn-root-nodemanager-localhost.out
下面试验一下hadoop的功能。
在/lp/hadoop/hadoop-2.7.3文件夹下新建一个文件data,内容为
1
2
3
4
先验证一下hdfs分布式文件系统,执行以下命令看是否有输出:
创建HDFS目录(注意不是本地目录)
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -mkdir /input
[root@localhost hadoop-2.7.3]# cat data
1
2
3
4
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -put data /input
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -ls /input
Found 1 items
-rw-r--r-- 3 work supergroup 8 2016-11-03 16:56 /input/data
但是在存放数据的目录/lp/hadoop/dfs/data,是看不出来有变化的:
这时候,在http://127.0.0.1:8305/dfshealth.html上能够看出一些变化:
Configured Capacity: 2.62 TB
DFS Used: 48 KB (0%)
Non DFS Used: 3.99 GB
DFS Remaining: 2.62 TB (99.85%)
创建HDFS文件夹
./bin/hadoop fs -mkdir /input
删除HDFS文件夹
./bin/hadoop fs -rmr /input
上面的命令就把output文件夹删除了,-rmr是一个递归删除操作,会删除该文件夹下面的所有文件以及文件夹。也可以选用-rm ,单个删除。
添加本地文件到hdfs目录
先在本地创建两个文件夹/lp/hadoop/dfs/input、/lp/hadoop/dfs/output
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -put /lp/hadoop/dfs/input /input
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -put /lp/hadoop/dfs/output /output
上面命令的hadoop fs -put 后面的第一个参数是本地路径,第二个参数是hadoop HDFS上的路径,意思就是将本地路径加载到HDFS上。
注意:在将本地目录添加为hdfs目录以后,再更改本地目录,并不会修改hdfs目录。
现在跑一个hadoop命令wc看看:
# ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar -input /input -output /output -mapper cat -reducer wc
可以看到结果:
# ./bin/hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 work supergroup 0 2016-11-03 17:17 /output/_SUCCESS
-rw-r--r-- 3 work supergroup 25 2016-11-03 17:17 /output/part-00000
# ./bin/hadoop fs -cat /output/part-00000
4 4 12
原来是wc的输出格式:
行数 单词数 字节数
hbase的部署
首先从http://www.apache.org/dyn/closer.cgi/hbase/下载稳定版安装包,我下的是hbase-1.2.6-bin.tar.gz
下载解压到/lp/hadoop/hbase-1.2.6
解压后修改conf/hbase-site.xml,改成:
hbase.cluster.distributed
true
hbase.rootdir
hdfs://localhost:9001/hbase
hbase.zookeeper.quorum
127.0.0.1
hbase.coprocessor.master.classes
org.apache.hadoop.hbase.security.access.AccessController
hbase.coprocessor.region.classes
org.apache.hadoop.hbase.security.token.TokenProvider,org.apache.hadoop.hbase.security.access.AccessController,org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint
其中hbase.rootdir配置的是hdfs地址,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致
其中hbase.zookeeper.quorum是zookeeper的地址,可以配多个,我们试验用就先配一个
修改 /lp/hadoop/hbase-1.2.6/conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
hbase的部署,需要在/lp/hadoop/hbase-1.2.6目录下右健(在终端中打开),然后执行hbase部署的命令
启动hbase,执行
./bin/start-hbase.sh
这时有可能会让你输入本地机器的密码
启动成功后可以看到几个进程起来,包括zookeeper的HQuorumPeer和hbase的HMaster、HRegionServer
然后启动hbase的shell
./bin/hbase shell
下面我们试验一下hbase的使用,执行:
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 3.0000 average load
创建一张表
hbase(main):004:0> create 'table1','field1'
0 row(s) in 1.3430 seconds
=> Hbase::Table - table1
获取一张表
hbase(main):005:0> t1 = get_table('table1')
0 row(s) in 0.0010 seconds
=> Hbase::Table - table1
添加一行
hbase(main):008:0> t1.put 'row1', 'field1:qualifier1', 'value1'
0 row(s) in 0.4160 seconds
读取全部
hbase(main):009:0> t1.scan
ROW COLUMN+CELL
row1 column=field1:qualifier1, timestamp=1470621285068, value=value1
1 row(s) in 0.1000 seconds
我们同时也看到hdfs中多出了hbase存储的目录(注意下面的命令是在/lp/hadoop/hadoop-2.7.3目录下执行):
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -ls /hbase
Found 7 items
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/.tmp
drwxr-xr-x - root supergroup 0 2016-08-08 09:58 /hbase/MasterProcWALs
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/WALs
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/data
-rw-r--r-- 3 root supergroup 42 2016-08-08 09:05 /hbase/hbase.id
-rw-r--r-- 3 root supergroup 7 2016-08-08 09:05 /hbase/hbase.version
drwxr-xr-x - root supergroup 0 2016-08-08 09:24 /hbase/oldWALs
这说明hbase是以hdfs为存储介质的,因此它具有分布式存储拥有的所有优点
hbase的架构如下:
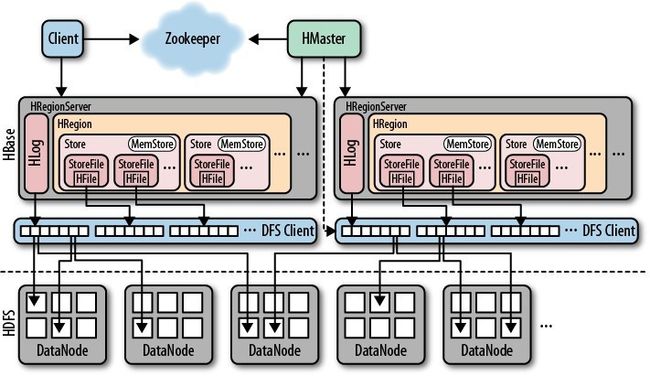
其中HMaster负责管理HRegionServer以实现负载均衡,负责管理和分配HRegion(数据分片),还负责管理命名空间和table元数据,以及权限控制
HRegionServer负责管理本地的HRegion、管理数据以及和hdfs交互。
Zookeeper负责集群的协调(如HMaster主从的failover)以及集群状态信息的存储
客户端传输数据直接和HRegionServer通信
Hive
从http://mirrors.hust.edu.cn/apache/hive下载安装包,我下的是apache-hive-2.1.1-bin.tar.gz
解压后,我们先准备hdfs,执行:
解压后在 /lp/hadoop/apache-hive-2.1.1-bin
打开conf,准备配置文件 cp hive-env.sh.template hive-env.sh
修改HADOOP_HOME:HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
复制hive-default.xml.template粘贴为hive-site.xml
复制hive-log4j2.properties.template粘贴为hive-log4j2.properties
复制hive-exec-log4j2.properties.template粘贴为hive-exec-log4j2.properties
解压后,我们先准备hdfs,执行(下面的命令是在/lp/hadoop/hadoop-2.7.3目录下执行的):
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -mkdir /tmp
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user/hive
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user/hive/warehourse
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -chmod g+w /tmp
[root@localhost hadoop-2.7.3]# ./bin/hadoop fs -chmod g+w /user/hive/warehourse
使用hive必须提前设置好HADOOP_HOME环境变量,这样它可以自动找到我们的hdfs作为存储,不妨我们把各种HOME和各种PATH都配置好:
vim ~/.bashrc
点击a修改,添加以下内容
HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
export HADOOP_HOME
HBASE_HOME=/lp/hadoop/hbase-1.2.6
export HBASE_HOME
HIVE_HOME=/lp/hadoop/apache-hive-2.1.1-bin
export HIVE_HOME
PATH=$PATH:$HOME/bin
PATH=$PATH:$HBASE_HOME/bin
PATH=$PATH:$HIVE_HOME/bin
PATH=$PATH:$HADOOP_HOME/bin
export PATH
按esc退出编辑,按ZZ保存退出。
执行一下“source ~/.bashrc ”,重新加载修改后的配置。
修改/lp/hadoop/apache-hive-2.1.1-bin/conf/hive-site.xml,把其中的${system:java.io.tmpdir}都修改成/lp/hadoop/apache-hive-2.1.1-bin/tmp,你也可以自己设置成自己的tmp目录,把${system:user.name}都换成用户名,为这里替换成了luanpeng
初始化元数据数据库(默认保存在本地的derby数据库,也可以配置成mysql),注意,不要先执行hive命令,否则这一步会出错,(注意下面的命令是在/lp/hadoop/apache-hive-2.1.1-bin目录下执行)
[root@localhost apache-hive-2.1.1-bin]# ./bin/schematool -dbType derby -initSchema
成功之后我们可以以客户端形式直接启动hive,如:
[root@localhost apache-hive-2.1.1-bin]# ./bin/hive
hive> show databases;
OK
default
Time taken: 1.886 seconds, Fetched: 1 row(s)
hive>
试着创建个数据库是否可以:
hive> create database mydatabase;
OK
Time taken: 0.721 seconds
hive> show databases;
OK
default
mydatabase
Time taken: 0.051 seconds, Fetched: 2 row(s)
hive>
这时候,还是单机版。需要启动server。启动之前,先把端口改一下。
修改/lp/hadoop/apache-hive-2.1.1-bin/conf/hive-site.xml文件
hive.server2.thrift.port
10000
改成
hive.server2.thrift.port
8338
然后启动命令:
[root@localhost apache-hive-2.1.1-bin]# mkdir log ;
[root@localhost apache-hive-2.1.1-bin]# nohup ./bin/hiveserver2 &>log/hive.log &
这时可以通过jdbc客户端连接这个服务访问hive,端口是8338.
Spark
下载Spark版本和地址:
http://apache.fayea.com/spark/spark-2.0.1/spark-2.3.0-bin-hadoop2.7.tgz
解压后的目录为/lp/hadoop/spark-2.3.0-bin-hadoop2.7
spark有多种部署方式,Standalone模式、Spark On Mesos模式、Spark On YARN模式。
下面我们尝试spark单机直接跑、spark集群运行,spark在yarn上运行。
首先支持单机直接跑
如执行样例程序:(下面的命令是在/lp/hadoop/spark-2.3.0-bin-hadoop2.7中执行的)
[root@localhost spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit examples/src/main/python/pi.py 10
打印出很多日志,其中有如下几条重要日志:
2018-05-14 20:12:43 INFO DAGScheduler:54 - Job 0 finished: reduce at /lp/hadoop/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/pi.py:44, took 0.981974 s
Pi is roughly 3.142740
2018-05-14 20:12:43 INFO AbstractConnector:318 - Stopped Spark@3c839941{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-05-14 20:12:43 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.122.1:4040
表示,计算任务成功了。
下面是spark集群运行任务
修改下默认端口,修改sbin/start-master.sh 文件
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8080
fi
改成
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8340
fi
改一下UI端口从8081到8341, 修改sbin/start-slaves.sh文件
if [ "$SPARK_WORKER_WEBUI_PORT" = "" ]; then
SPARK_WORKER_WEBUI_PORT=8341
fi
运行命令:
[root@localhost spark-2.3.0-bin-hadoop2.7]# sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /lp/hadoop/spark-2.3.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-localhost.out
此时,打开 http://127.0.0.1:8340/ 可以看到:
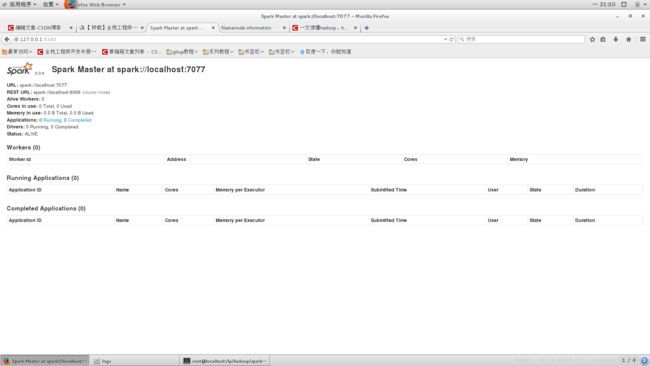
根据图片中的url:spark://localhost:7077
再启动slave
[root@localhost spark-2.3.0-bin-hadoop2.7]# ./sbin/start-slave.sh spark://localhost:7077
看日志/lp/hadoop/spark-2.3.0-bin-hadoop2.7/logs文件夹中的日志若没有报错,则ok
看 http://127.0.0.1:8340/增加了一个 worker,我们可以根据需要启动多个worker
看slave 的UI 界面 http://127.0.0.1:8341/ 也能正常看到。 (11.27注:看起来主从都是这台机器)
现在,就可以把刚刚单机的任务提交到spark集群上来运行了:
[root@localhost spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit --master spark://localhost:7077 examples/src/main/python/pi.py 10
结果日志包括了:
2018-05-14 21:25:44 INFO DAGScheduler:54 - Job 0 finished: reduce at /lp/hadoop/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/pi.py:44, took 1.894816 s
Pi is roughly 3.152956
2018-05-14 21:25:44 INFO AbstractConnector:318 - Stopped Spark@556e488{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-05-14 21:25:44 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.122.1:4040
spark部署在yarn集群上
spark程序也可以部署到yarn集群上执行,也就是我们部署hadoop时启动的yarn。当然部署在yarn上首先要要求启动了hadoop的hdfs和yarn。
我们需要提前配置好HADOOP_CONF_DIR,修改/etc/profile文件,添加:
HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
export HADOOP_HOME
HBASE_HOME=/lp/hadoop/hbase-1.2.6
export HBASE_HOME
HIVE_HOME=/lp/hadoop/apache-hive-2.1.1-bin
export HIVE_HOME
PATH=$PATH:$HOME/bin
PATH=$PATH:$HBASE_HOME/bin
PATH=$PATH:$HIVE_HOME/bin
PATH=$PATH:$HADOOP_HOME/bin
export PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
运行以下命令,重新加载配置文件
source /etc/profile
下面我们把任务部署到yarn集群上去:
[root@localhost spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit --master yarn --deploy-mode cluster examples/src/main/python/pi.py 10
在Hadoop任务的管理界面 http://127.0.0.1:8320/cluster 能看到跑了这个任务:
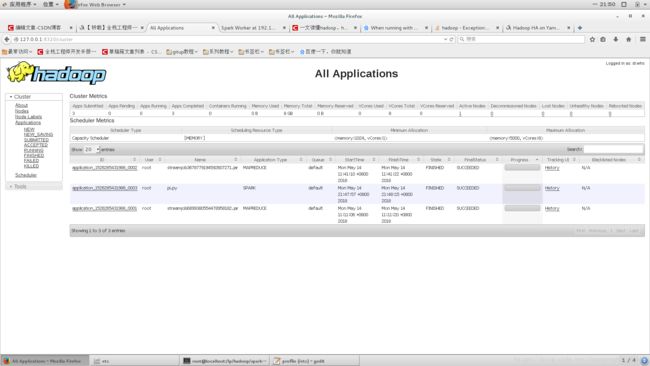
总结一下
hdfs是所有hadoop生态的底层存储架构,它主要完成了分布式存储系统的逻辑,凡是需要存储的都基于其上构建
yarn是负责集群资源管理的部分,这个资源主要指计算资源,因此它支撑了各种计算模块
map-reduce组件主要完成了map-reduce任务的调度逻辑,它依赖于hdfs作为输入输出及中间过程的存储,因此在hdfs之上,它也依赖yarn为它分配资源,因此也在yarn之上
hbase基于hdfs存储,通过独立的服务管理起来,因此仅在hdfs之上
hive基于hdfs存储,通过独立的服务管理起来,因此仅在hdfs之上
spark基于hdfs存储,即可以依赖yarn做资源分配计算资源也可以通过独立的服务管理,因此在hdfs之上也在yarn之上,从结构上看它和mapreduce一层比较像
总之,每一个系统负责了自己擅长的一部分,同时相互依托,形成了整个hadoop生态。