Tensorflow实战:LSTM原理及实现(详解)
LSTM规避了标准RNN中梯度爆炸和梯度消失的问题,所以会显得更好用,学习速度更快
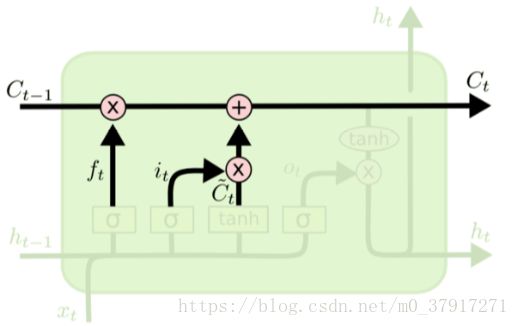
下图是最基本的LSTM单元连接起来的样子
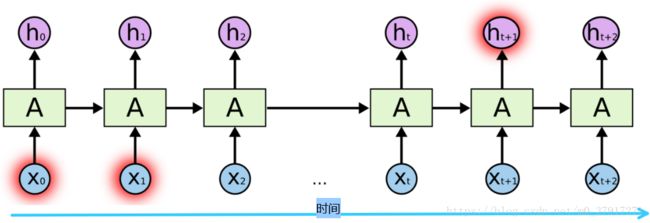
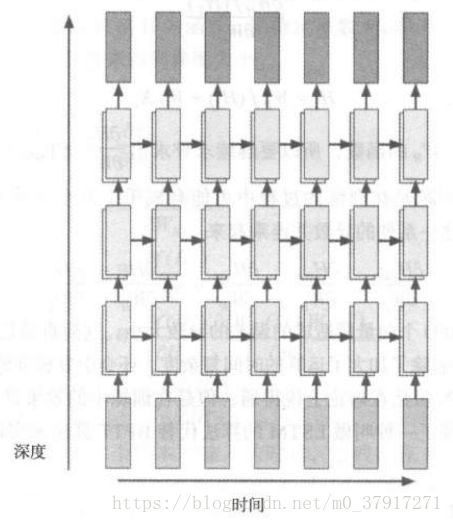
上图为一层LSTM单元连接起来的样子,在工业上,LSTM是可以像一个很大的方阵的,其中除了输入层和输出层分别对应着Xt和ht的值以外,中间的部分都是一层层的LSTM单元,拓扑结构如下:
LSTM内部结构
LSTM看上去就是这样一种效果,一个一个首尾相接,
同一层的会把前面单元的输出作为后面单元的输入;
前一层的输出会作为后一层的输入
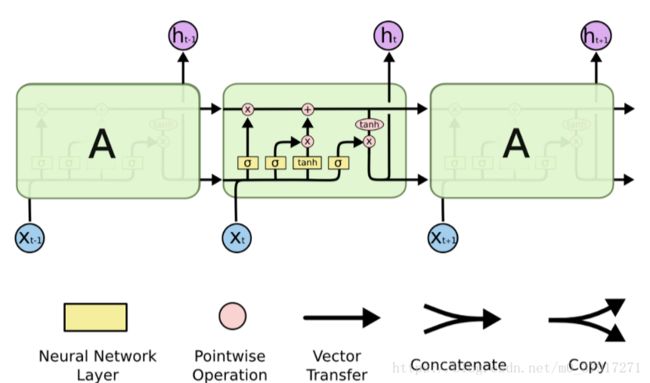
细胞状态
LSTM 的关键就是细胞状态,水平线在图上方从左到右贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易
左面的乘号是一个乘法操作,右面的加号就是普通的线性叠加、
这个操作相当于左侧的Ct-1进入单元后,先被一个乘法器乘以一个系数后,再线性叠加一个数值然后从右侧输出去

(一)忘记门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成
忘记门:
作用对象:细胞状态
作用:将细胞状态中的信息选择性的遗忘, 即丢掉老的不用的信息
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的类别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
例如,他今天有事,所以我。。。当处理到‘’我‘’的时候选择性的忘记前面的’他’,或者说减小这个词对后面词的作用。
左侧的ht-1和下面输入的xt经过了连接操作,再通过一个线性单元,经过一个σ也就是sigmoid函数生成一个0到1之间的数字作为系数输出,表达式如左:
Wf和bf作为待定系数是要进行训练学习的

(二)产生要更新的新信息
包含两个小的神经网络层
一个是熟悉的sigmoid部分
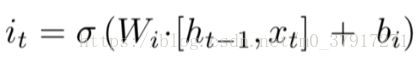
另一个tanh标识(映射到-1到1)也是一个神经网络层,表达式为:

其中的W和b都是要通过训练得到的

(三)
更新细胞状态,
新细胞状态 = 旧细胞状态 × 忘记门结果 + 要更新的新信息
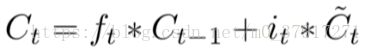
(四)
基于细胞状态,确定输出什么值
一个输出到同层下一个单元,一个输出到下一层的单元上
首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。
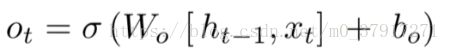
接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
![]()
在语言模型中,这种影响是可以影响前后词之间词形的相关性的,例如前面输入的是一个代词或名词,后面跟随的动词会学到是否使用“三单形式”或根据前面输入的名词数量来决定输出的是单数形式还是复数形式。

以下为本文实现LSTM的代码,使用了perplexity(即平均cost的自然常数指数,是语言模型中用来比较模型性能的重要指标,越低表示模型输出的概率分布在预测样本上越好)来测评模型,代码及详细注释如下:
import time
import numpy as np
import tensorflow as tf
from tensorflow.models.tutorials.rnn.ptb import reader
'''处理输入数据的类'''
class PTBInput(object):
def __init__(self, config, data, name=None):
self.batch_size = batch_size = config.batch_size #读取config中的batch_size,num_steps到本地变量
self.num_steps = num_steps = config.num_steps
self.epoch_size = ((len(data) // batch_size) - 1) // num_steps #全部样本被训练的次数
self.input_data, self.targets = reader.ptb_producer(data, batch_size, num_steps, name=name)
'''语言模型的类'''
class PTBModel(object):
def __init__(self, is_training, #训练标记
config, #配置参数
input_): #PTBInput类的实例input_
self._input = input_
batch_size = input_.batch_size
num_steps = input_.num_steps
size = config.hidden_size #LSTM的节点数
vocab_size = config.vocab_size #词汇表的大小
def lstm_cell(): #定义默认的LSTM单元
return tf.contrib.rnn.BasicLSTMCell(
size, #隐含节点数
forget_bias=0.0, #忘记门的bias
state_is_tuple=True) #代表接受和返回的state将是2-tuple的形式
attn_cell = lstm_cell #不加括号表示调用的是函数,加括号表示调用的是函数的结果
if is_training and config.keep_prob < 1: #如果在训练状态且Dropout的keep_prob小于1
#在前面的lstm_cell后接一个Dropout层
def attn_cell():
return tf.contrib.rnn.DropoutWrapper(
lstm_cell(), output_keep_prob=config.keep_prob
)
#使用RNN堆叠函数tf.contrib.rnn.MultiRNNCell将前面构造的lstm_cell多层堆叠得到cell,堆叠次数为config中num_layers
cell = tf.contrib.rnn.MultiRNNCell(
[attn_cell() for _ in range(config.num_layers)],
state_is_tuple=True)
self._initial_state = cell.zero_state(batch_size, tf.float32) #设置LSTM单元的初始化状态为0
'''词嵌入部分'''
with tf.device("/cpu:0"):
embedding = tf.get_variable( #初始化词向量embedding矩阵
"embedding", [vocab_size, size], dtype=tf.float32) #行数词汇表数vocab_size,列数(每个单词的向量位数)设为hidden_size
inputs = tf.nn.embedding_lookup(embedding, input_.input_data) #查询单词的向量表达获得inputs
if is_training and config.keep_prob < 1: #如果为向量状态则再添加一层Dropout层
inputs = tf.nn.dropout(inputs, config.keep_prob)
'''定义输出outputs'''
outputs = []
state = self._initial_state
#为了控制训练过程,我们会限制梯度在反向传播时可以展开的步数为一个固定的值,而这个步数也就是num_steps
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: #第二次循环开始,使用tf.get_variable_scope().reuse_variables()设置复用变量
tf.get_variable_scope().reuse_variables()
#每次循环,传入inputs和state到堆叠的LSTM单元,得到输出的cell_output和更新后的state
#inputs有三个维度,1:batch中第几个样本,2:样本中第几个单词,3:单词的向量维度
(cell_output, state) = cell(inputs[:, time_step, :], state) #inputs[:, time_step, :]表示所有样本的第time_step个单词
outputs.append(cell_output) #添加到输出列表outputs
#将output内容用tf.concat串接到一起,并使用tf.reshape将其转为一个很长的一维向量
output = tf.reshape(tf.concat(outputs, 1), [-1, size])
#定义权重
softmax_w = tf.get_variable(
"softmax_w", [size, vocab_size], dtype=tf.float32)
#定义偏置
softmax_b = tf.get_variable(
"softmax_b", [vocab_size], dtype=tf.float32)
#输出乘上权重并加上偏置得到logits,即网络最后的输出
logits = tf.matmul(output, softmax_w) + softmax_b
#使用如下函数计算输出logits和targets的偏差
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[logits],
[tf.reshape(input_.targets, [-1])],
[tf.ones([batch_size * num_steps], dtype=tf.float32)])
self._cost = cost = tf.reduce_sum(loss) / batch_size #汇总batch的总误差,再计算到平均每个样本的误差cost
self._final_state = state #保留最终的状态为final_state
if not is_training:
return
self._lr = tf.Variable(0.0, trainable=False) #定义学习速率并设为不可训练的
tvars = tf.trainable_variables() #获取全部可训练的参数
#针对前面得到的cost,计算tvars的梯度,并用tf.clip_by_global_norm设置梯度的最大范数max_grad_norm
#这就是Gradient Clipping的方法,控制梯度的最大范数,防止梯度爆炸,某种程度上起到正则化的效果
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),
config.max_grad_norm)
optimizer = tf.train.GradientDescentOptimizer(self._lr) #定义优化器
#创建训练操作_train_op,用optimizer.apply_gradients将clip过的梯度应用到所有可训练参数tvars上
self._train_op = optimizer.apply_gradients(zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step()) #生成全局统一的训练步数
#设置一个名为_new_lr的placeholder用以控制学习速率
self._new_lr = tf.placeholder(
tf.float32, shape=[], name="new_learning_rate")
self._lr_update = tf.assign(self._lr, self._new_lr) #将_new_lr的值赋给当前的学习速率_lr
#用以外部控制学习速率
def assign_lr(self, session, lr_value):
session.run(self._lr_update, feed_dict={self._new_lr: lr_value}) #执行_lr_update操作完成对学习速率的修改
''' @property装饰器可以将返回变量设为只读,防止修改变量引发问题
这里定义input,initial_state,cost,final_state,lr,train_op为只读,方便外部访问'''
@property
def input(self):
return self._input
@property
def initial_state(self):
return self._initial_state
@property
def cost(self):
return self._cost
@property
def final_state(self):
return self._final_state
@property
def lr(self):
return self._lr
@property
def train_op(self):
return self._train_op
'''小模型的设置'''
class SmallConfig(object):
init_scale = 0.1 #网络中权重的初始scale
learning_rate = 1.0 #学习速率的初始值
max_grad_norm = 5 #前面提到的梯度的最大范数
num_layers = 2 #LSTM可以堆叠的层数
num_steps = 20 #LSTM梯度反向传播的展开步数
hidden_size = 200 #LSTM内隐含节点数
max_epoch = 4 #初始学习速率可训练的epoch数
max_max_epoch = 13 #总共可训练的epoch数
keep_prob = 1.0 #dropout保留节点的比例
lr_decay = 0.5 #学习速率的衰减速度
batch_size = 20 #每个batch中样本数
vocab_size = 10000 #词汇表大小
'''中等大小模型的设置'''
class MediumConfig(object):
init_scale = 0.1 #减小,小一些有利于温和的训练
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 35 #增大
hidden_size = 650 #增大
max_epoch = 6 #增大
max_max_epoch = 39 #增大
keep_prob = 0.5 #减小,之前设为1即没有dropout
lr_decay = 0.8 #学习迭代次数增大,因此学习速率的衰减次数减小
batch_size = 20
vocab_size = 10000
'''大型模型设置'''
class MediumConfig(object):
init_scale = 0.04 #减小
learning_rate = 1.0
max_grad_norm = 10 #增大
num_layers = 2
num_steps = 35
hidden_size = 1500 #增大
max_epoch = 14 #增大
max_max_epoch = 55 #增大
keep_prob = 0.35 #减小,之前设为1即没有dropout
lr_decay = 1 / 1.15 #学习迭代次数增大,因此学习速率的衰减次数减小
batch_size = 20
vocab_size = 10000
'''测试用设置,参数尽量使用最小值,只为测试可以完整运行模型'''
class TestConfig(object):
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 1
num_layers = 1
num_steps = 2
hidden_size = 2
max_epoch = 1
max_max_epoch = 1
keep_prob = 1.0
lr_decay = 0.5
batch_size = 20
vocab_size = 10000
'''训练一个epoch数据'''
def run_epoch(session, model, eval_op=None, verbose=False):
start_time = time.time() #记录当前时间
costs = 0.0 #初始化损失costs
iters = 0 #初始化迭代数
state = session.run(model.initial_state) #执行初始化状态并获得初始状态
feches = { #输出结果的字典表
"cost":model.cost,
"final_state":model.final_state
}
if eval_op is not None: #如果有评测操作,也加入feches
feches["eval_op"] = eval_op
for step in range(model.input.epoch_size): #训练循环,次数为epoch_size
feed_dict = {}
for i, (c, h) in enumerate(model.initial_state): #生成训练用的feed_dict,将全部LSTM单元的state加入feed_dict
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
# 执行feches对网络进行一次训练,得到cost和state
vals = session.run(feches, feed_dict)
cost = vals["cost"]
state = vals["final_state"]
costs += cost #累加cost到costs
iters += model.input.num_steps #累加num_steps到iters
if verbose and step % (model.input.epoch_size // 10) == 10: #每完成约10%的epoch,就进行一次结果的展示
#一次展示当前epoch的进度,perplexity和训练速度
#perplexity(即平均cost的自然常数指数,是语言模型中用来比较模型性能的重要指标,越低表示模型输出的概率分布在预测样本上越好)
print("%.3f perplexity: %.3f speed: %.0f wps" %
(step * 1.0 / model.input.epoch_size, np.exp(costs / iters),
iters * model.input.batch_size / (time.time() - start_time)))
return np.exp(costs / iters) #返回perplexity作为函数结果
raw_data = reader.ptb_raw_data('F://研究生资料/data/simple-examples/data/') #直接读取解压后的数据
train_data, valid_data, test_data, _ = raw_data #得到训练数据,验证数据和测试数据
config = SmallConfig() #定义训练模型的配置为SmallConfig
eval_config = SmallConfig() #测试配置需和训练配置一致
eval_config.batch_size = 1 #将测试配置的batch_size和num_steps修改为1
eval_config.num_steps = 1
#创建默认的Graph
with tf.Graph().as_default():
# 设置参数的初始化器,令参数范围在[-init_scale,init_scale]之间
initializer = tf.random_uniform_initializer(-config.init_scale, config.init_scale)
'''使用PTBInput和PTBModel创建一个用来训练的模型m,以及用来验证的模型mvalid和测试的模型mtest,
其中训练和验证模型直接使用前面的config,测试模型使用前面的测试配置eval_config'''
#训练模型m
with tf.name_scope("Train"):
train_input = PTBInput(config=config, data=train_data, name="TrainInput")
with tf.variable_scope("Model", reuse=None, initializer=initializer):
m = PTBModel(is_training=True, config=config, input_=train_input)
#验证模型mvalid
with tf.name_scope("Valid"):
valid_input = PTBInput(config=config, data=valid_data, name="ValidInput")
with tf.variable_scope("Model", reuse=True, initializer=initializer):
mvalid = PTBModel(is_training=False, config=config, input_=valid_input)
#测试模型mtest
with tf.name_scope("Test"):
test_input = PTBInput(config=eval_config, data=test_data, name="TestInput")
with tf.variable_scope("Model", reuse=True, initializer=initializer):
mtest = PTBModel(is_training=False, config=eval_config, input_=test_input)
sv = tf.train.Supervisor() #创建训练的管理器
with sv.managed_session() as session: #使用sv.managed_session()创建默认session
for i in range(config.max_max_epoch): #执行多个epoch数据的循环
lr_decay = config.lr_decay ** max(i + 1 - config.max_max_epoch, 0.0)#计算累计的学习速率衰减值(只计算超过max_epoch的轮数)
m.assign_lr(session, config.learning_rate * lr_decay) #将初始学习速率呈上累计的衰减,并更新学习速率
'''循环内执行一个epoch的训练和验证并输出当前的学习速率,训练和验证集上的perplexity'''
print("Epoch: %d Learning rate: %.3f" % (i + 1, session.run(m.lr)))
train_perplexity = run_epoch(session, m, eval_op=m.train_op, verbose=True)
print("Epoch: %d Train Perplexity: %.3f" % (i + 1, train_perplexity))
valid_perplexity = run_epoch(session, mvalid)
print("Epoch: %d Valid Perplexity: %.3f" % (i + 1, valid_perplexity))
'''完成全部训练后,计算并输出模型在测试集上的perplexity'''
test_perplexity = run_epoch(session, mtest)
print("Test Perplexity: %.3f" % test_perplexity)
结果如下:
Epoch: 13 Learning rate: 1.000
0.004 perplexity: 60.833 speed: 11641 wps
0.104 perplexity: 46.656 speed: 11364 wps
0.204 perplexity: 51.109 speed: 11372 wps
0.304 perplexity: 50.082 speed: 11419 wps
0.404 perplexity: 50.203 speed: 11437 wps
0.504 perplexity: 50.504 speed: 11413 wps
0.604 perplexity: 49.936 speed: 11394 wps
0.703 perplexity: 50.170 speed: 11379 wps
0.803 perplexity: 50.362 speed: 11379 wps
0.903 perplexity: 49.721 speed: 11376 wps
Epoch: 13 Train Perplexity: 49.700
Epoch: 13 Valid Perplexity: 138.165
Test Perplexity: 132.954