kafka写入的过程
前几天和大佬交流,说一些大牛可以分分钟复制一个中间件,拿这个标准衡量自己还是差的有点远的,在工作中经常用到的是kafka,现在有点时间再深入了解一下kafka的写入过程。
几个基本的概念:
- broker: 消息处理结点,多个broker组成kafka集群。
- topic: 一类消息,如page view,click行为等。
- partition: topic的物理分组,每个partition都是一个有序队列。
- replica:partition 的副本,保障 partition 的高可用。
- producer: 产生信息的主体,可以是服务器日志信息等。
- consumer: 消费producer产生话题消息的主体。
- Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 的一个 Consumer 消费,但可以被多个 consumer group 消费。
- segment: 多个大小相等的段组成了一个partition。
- offset: 一个连续的用于定位被追加到分区的每一个消息的序列号,最大值为64位的long大小,19位数字字符长度。
- massage: kafka中最基本的传递对象,有固定格式。
- zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息。
- controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
partition、segment、offset都是为topic服务的,每个topic可以分为多个partition,一个partition相当于一个大目录,每个partition下面有多个大小相等的segment文件,这个segment是由message组成的,而每一个的segment不一定由大小相等的message组成。segment大小及生命周期在server.properties文件中配置。offset用于定位位于段里的唯一消息,这个offset用于定位partition中的唯一性。
kafka的总体数据流程
(图来自:https://www.jianshu.com/p/d3e963ff8b70):
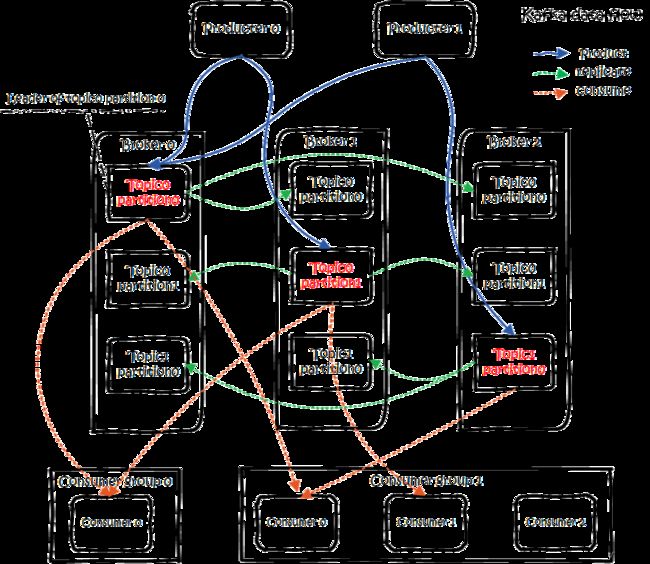
Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,然后进行业务处理。图中有两个topic,topic 0有两个partition,topic 1有一个partition,三副本备份。可以看到consumergroup1中的consumer2没有分到partition处理,这是有可能出现的。关于broker、topics、partitions的一些元信息用zk来存,监控和路由啥的也都会用到zk。
生产
生产流程大致如下:
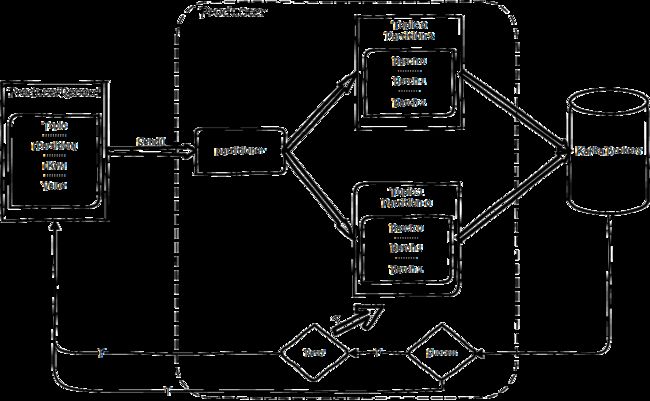
创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先序列化,然后按照topic和partition,放进对应的发送队列中。kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。发送到partition分为两种情况
- 指定了key,按照key进行哈希,相同key去一个partition。
- 没有指定key,round-robin来选partition
生产者将消息发送至该 partition leader。之后生产者会根据设置的 request.required.acks 参数不同,选择等待或或直接发送下一条消息。
-
request.required.acks = 0 表示 Producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
-
request.required.acks = 1 表示 Producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
-
request.required.acks = -1 表示 Producer 等待来自 Leader 和所有 Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,除非 Leader 节点和所有 Follower 节点都宕机了,否则不会发生消息的丢失。
文件组织
kafka的数据,实际上是以文件的形式存储在文件系统的。topic下有partition,partition下有segment,segment是实际的一个个文件,topic和partition都是抽象概念。
在目录/KaTeX parse error: Expected '}', got 'EOF' at end of input: {topicName}-{partitionid}/下,存储着实际的log文件(即segment),还有对应的索引文件。
每个segment文件大小相等,文件名以这个segment中最小的offset命名,文件扩展名是.log;segment对应的索引的文件名字一样,扩展名是.index。有两个index文件,一个是offset index用于按offset去查message,一个是time index用于按照时间去查,其实这里可以优化合到一起,下面只说offset index。总体的组织是这样的:

为了减少索引文件的大小,降低空间使用,方便直接加载进内存中,这里的索引使用稀疏矩阵,不会每一个message都记录下具体位置,而是每隔一定的字节数,再建立一条索引。 索引包含两部分,分别是baseOffset,还有position。
- baseOffset:意思是这条索引对应segment文件中的第几条message。这样做方便使用数值压缩算法来节省空间。例如kafka使用的是varint。
- position:在segment中的绝对位置。
接下来弄清楚segment具体细节之后再说offset:
offset
个人认为发送的核心是围绕着offset来的,offset是一个连续的用于定位被追加到分区的每一个消息的序列号。一个消费组消费partition,需要保存offset记录消费到哪,这样保证一个partition内部消费的顺序性,以前保存在zk中,由于zk的写性能不好,以前的解决方法都是consumer每隔一分钟上报一次。这里zk的性能严重影响了消费的速度,而且很容易出现重复消费。在0.10版本后,kafka把这个offset的保存,从zk总剥离,保存在一个名叫__consumeroffsets topic的topic中。写进消息的key由groupid、topic、partition组成,value是偏移量offset。topic配置的清理策略是compact。总是保留最新的key,其余删掉。一般情况下,每个key的offset都是缓存在内存中,查询的时候不用遍历partition,如果没有缓存,第一次就会遍历partition建立缓存,然后查询返回。
确定consumer group位移信息写入__consumers_offsets的哪个partition,具体计算公式:
__consumers_offsets partition = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
那么对于分区中的一个offset例如等于345552怎么去查找相应的message呢?
先找到该message所在的segment文件,通过二分查找的方式寻找小于等于345552的offset,假如叫S的segment符合要求,如果S等于345552则S上一个segment的最后一个message即为所求;如果S小于345552则依次遍历当前segment即可找到。实际上offset的存储采用了稀疏索引,这样对于稠密索引来说节省了存储空间,但代价是查找费点时间。
这里稍稍总结一下:由于kafka需要保证一个partition顺序消费,但是内部又分为很多个segment,那怎么保证顺序的呢,核心就是offset是不断递增的,而segment又是根据offset排序,所以整体是有序的。
kafka支持3种消息投递语义
- At most once 消息至多会被发送一次,但如果产生网络延迟等原因消息就会有丢失。
- At least once 消息至少会被发送一次,上面既然有消息会丢失,那么给它加一个消息确认机制即可解决,但是消息确认阶段也还会出现同样问题,这样消息就有可能被发送两次。
- Exactly once 消息只会被发送一次,这是我们想要的效果。
那么kafka是怎么解决的呢?
生产幂等性:思路是这样的,为每个producer分配一个pid,作为该producer的唯一标识。producer会为每一个
- 消息的seq比broker的seq大超过时,说明中间有数据还没写入,即乱序了。
- 消息的seq不比broker的seq小,那么说明该消息已被保存。
事务性/原子性广播:引入tid(transaction id),和pid不同,这个id是应用程序提供的,用于标识事务,和producer是谁并没关系。就是任何producer都可以使用这个tid去做事务,这样进行到一半就死掉的事务,可以由另一个producer去恢复。同时为了记录事务的状态,类似对offset的处理,引入transaction coordinator用于记录transaction log。在集群中会有多个transaction coordinator,每个tid对应唯一一个transaction coordinator。
注:transaction log删除策略是compact,已完成的事务会标记成null,compact后不保留。
做事务时,先标记开启事务,写入数据,全部成功就在transaction log中记录为prepare commit状态,否则写入prepare abort的状态。之后再去给每个相关的partition写入一条marker(commit或者abort)消息,标记这个事务的message可以被读取或已经废弃。成功后在transaction log记录下commit/abort状态,至此事务结束。
参考地址:
https://blog.csdn.net/sand_clock/article/details/68486599
https://www.jianshu.com/p/d3e963ff8b70(内容大部分来源于此)
https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
https://cwiki.apache.org/confluence/display/KAFKA/KIP-98±+Exactly+Once+Delivery+and+Transactional+Messaging#KIP-98-ExactlyOnceDeliveryandTransactionalMessaging-TransactionalGuarantees