Prometheus+grafana监控:cAdvisor输出的容器CPU相关的指标的解读
概述
对容器中的服务进行监控,常见方案是采用Prometheus+grafana。其中对容器服务的CPU的监控有一组指标,本文对它们进行了一些分析和解读,并做了一些试验。
查看cAdvisor输出的容器CPU监控指标
我们使用kubernetes进行管理,自带了容器监控cAdvisor exporter,可以直接通过页面查看监控指标,例如直接访问一台IP为172.18.12.188的node节点:
http://172.18.12.188:4194/metrics
直接在页面中搜索以 container_cpu 开头的指标,如下表所示:
| 名称 | 类型 | 单位 | 说明 |
|---|---|---|---|
| container_cpu_usage_seconds_total | counter | 秒数 |
该容器服务针对每个CPU累计消耗的CPU时间。如果有多个CPU,则总的CPU时间需要把各个CPU耗费的时间相加 |
| container_cpu_user_seconds_total | counter | 秒数 |
该容器服务累计消耗的用户(user)CPU时间 |
| container_cpu_system_seconds_total | counter | 秒数 |
该容器服务累计消耗的系统(system)CPU时间 |
| container_cpu_cfs_throttled_seconds_total | counter | 秒数 |
cfs 是完全公平调度器(Completely Fair Scheduler)的缩写,是Linux的一种控制CPU资源占用的机制,可以按指定比例分配调度CPU 的使用时间。这个指标指的是该容器服务被限制使用的CPU时间 |
| container_cpu_cfs_throttled_periods_total | counter | 个数 |
文档注释是:“Number of throttled period intervals.”,解释为被限制/节流的CPU时间周期数。 |
| container_cpu_cfs_periods_total | counter | 个数 |
文档注释是:“Number of elapsed enforcement period intervals。”,应该解释为已经执行的CPU时间周期数。 |
| container_cpu_load_average_10s | gauge | 文档注释是:“Value of container cpu load average over the last 10 seconds.”应该解释为过去10秒内的CPU负载的平均值。 |
用Grafana查看容器CPU指标
以我们部署在容器中的某自己开发的服务 cloud-bdp-interface为例,在grafana的dashborad中配置如下查询:
因为CPU指标是计数器(counter)类型,所以grafana 的metrics的配置用到 rate函数:
rate(container_cpu_usage_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m])
rate(container_cpu_user_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m])grafana查到的原始数据是:
container_cpu_usage_seconds_total
{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_os="linux",container_name="cloud-bdp-interface",cpu="cpu00",id="/kubepods/burstable/pod84ab880d-bc9f-11e8-abe2-fa163e6f3f6b/93069e41ed1ac7181fa69732736f927ebe8764b560ba281c9d392a5333c30020",image="reg.docker.tb/huawei/bdp@sha256:975ac36a806f39d75ea992967b63ded54bd7b9798e2f5109511953681cc1fe53",instance="k8s-node-1",job="kubernetes-cadvisor",kubernetes_io_hostname="k8s-node-1",name="k8s_cloud-bdp-interface_cloud-bdp-interface-5b9bbc567f-xkvpj_docker-new40_84ab880d-bc9f-11e8-abe2-fa163e6f3f6b_0",namespace="docker-new40",pod_name="cloud-bdp-interface-5b9bbc567f-xkvpj"}
同一个节点上的同一个服务,不同cpu的占用时间都有计量和统计,如下:

由此可见,要得到该容器服务的CPU使用的总的情况,需要对所有CPU求和,即:
sum(rate(container_cpu_usage_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m]))
container_cpu_user_seconds_total
{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_os="linux",container_name="cloud-bdp-interface",id="/kubepods/burstable/pod84ab880d-bc9f-11e8-abe2-fa163e6f3f6b/93069e41ed1ac7181fa69732736f927ebe8764b560ba281c9d392a5333c30020",image="reg.docker.tb/huawei/bdp@sha256:975ac36a806f39d75ea992967b63ded54bd7b9798e2f5109511953681cc1fe53",instance="k8s-node-1",job="kubernetes-cadvisor",kubernetes_io_hostname="k8s-node-1",name="k8s_cloud-bdp-interface_cloud-bdp-interface-5b9bbc567f-xkvpj_docker-new40_84ab880d-bc9f-11e8-abe2-fa163e6f3f6b_0",namespace="docker-new40",pod_name="cloud-bdp-interface-5b9bbc567f-xkvpj"}
从返回的数据看, container_cpu_user_seconds_total 不再区分不同的CPU,已经针对所有CPU进行了合并,是个总的user CPU时间。直接用 rate 就可以得到不同容器服务的CPU的user时间。
一些试验
我们用了一个自己开发的测试容器服务 cloud-bdp-interface。虽然虚机节点的CPU是8核,但我们用k8s限制其使用为2核。我们可以用实验测试一下,在实际运行时,这个2核的限制是否有效。具体方法如下:
登录到该容器服务中,可参见文章:https://blog.csdn.net/palet/article/details/82627658
在命令行输入如下命令,模拟一个无限循环的进程,把所有能用的CPU占满:
echo 'while True: pass'|python &用top命令,可以看到CPU占用为99.9%,可以理解为占用了CPU的1核
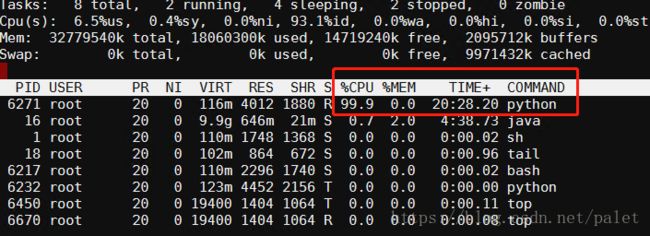
进一步加大压力,同时运行三个无限循环的进程:
echo 'while True: pass'|python &
echo 'while True: pass'|python &
echo 'while True: pass'|python &用top命令看CPU占用情况如下:

可以看到每个进程占用66.6%,三个进程加起来占用约200%,应该就是CPU的2核。
进一步查看grafna监控的指标,metrcs设置是:
sum(rate(container_cpu_usage_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m]))
rate(container_cpu_user_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m])
rate(container_cpu_system_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m])
rate(container_cpu_cfs_throttled_seconds_total{name=~"k8s_cloud-bdp-interface.*"}[5m])
监控结果如下:

可以看到,该容器服务的CPU占用,usage指标和user指标都约等于2.0, 也就是占用了2个CPU核心
小结
一般要对指定的容器服务进行监控,看一下 container_cpu_usage_seconds_total 指标就可以了。指标的格式如下:
sum(rate(container_cpu_usage_seconds_total{name=~"xxxxxxxxxxxxxxx.*"}[5m]))
要深入分析,可以再单独看 user CPU时间, system CPU时间等等,用如下指标格式:
rate(container_cpu_user_seconds_total{name=~"xxxxxxxxxxxxxxx.*"}[5m])
rate(container_cpu_system_seconds_total{name=~"xxxxxxxxxxxxxxx.*"}[5m])
附:CPU相关指标的原始注释
# HELP container_cpu_usage_seconds_total Cumulative cpu time consumed per cpu in seconds.
# TYPE container_cpu_usage_seconds_total counter
# HELP container_cpu_user_seconds_total Cumulative user cpu time consumed in seconds.
# TYPE container_cpu_user_seconds_total counter
# HELP container_cpu_cfs_periods_total Number of elapsed enforcement period intervals.
# TYPE container_cpu_cfs_periods_total counter
# HELP container_cpu_cfs_throttled_periods_total Number of throttled period intervals.
# TYPE container_cpu_cfs_throttled_periods_total counter
# HELP container_cpu_cfs_throttled_seconds_total Total time duration the container has been throttled.
# TYPE container_cpu_cfs_throttled_seconds_total counter
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
# HELP container_cpu_system_seconds_total Cumulative system cpu time consumed in seconds.
# TYPE container_cpu_system_seconds_total counter