卷积神经网络的发展综述
部分内容来自《Recent_Advances_in_Convolutional_Neural_Networks》,本人在此文基础上进行了一些删改。
摘要
过去几年,深度学习在解决诸如图像目标识别、语音识别和自然语言处理等很多问题方面都表现出色。在各种类型的神经网络当中,卷积神经网络是得到最深入研究的。早期由于缺乏训练数据和计算能力,要在不产生过拟合的情况下训练出高性能卷积神经网络是很困难的。ImageNet这样的大规模标记数据的出现和GPU计算性能的快速提高,使得对卷积神经网络的研究迅速井喷。本文我将纵览卷积神经网络近来发展,同时介绍卷积神经网络在视觉识别方面的一些应用。
关键词
深度学习、卷积神经网络、计算机视觉、AlexNet、池化、激活函数、ImageNet
前言
卷积神经网络(Convolutional Neural Network, CNN)是一种常见的深度学习网络架构,受生物自然视觉认知机制启发而来。1959年,Hubel & Wiesel [1] 发现了视觉系统的信息处理,可视皮层是分级的。举例说明:人眼观察一个气球,
首先从原始信号摄入开始(瞳孔摄入像素Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。下图是人脑进行人脸识别的一个示例图:
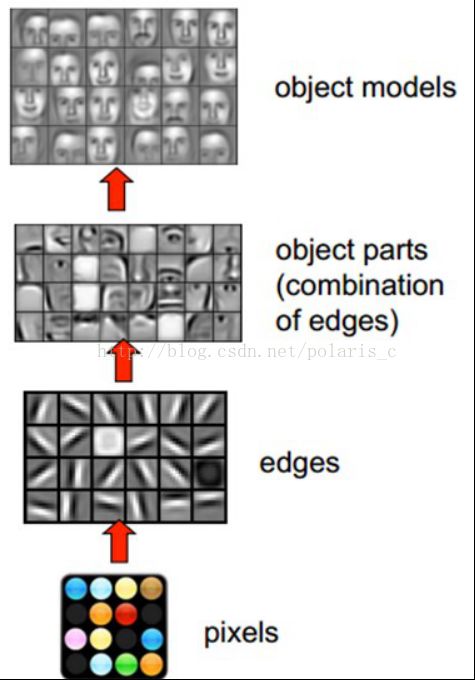
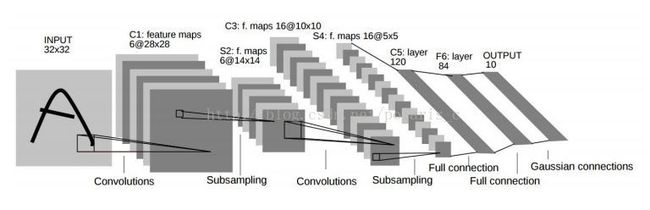
20世纪 90年代,LeCun et al. [1,2]等人发表论文,确立了CNN的现代结构,后来又对其进行完善。他们设计了一种多层的人工神经网络,取名叫做LeNet-5,可以对手写数字做分类。和其他神经网络一样,LeNet-5 也能使用反响传播算法(backpropagation)[3]训练。
CNN能够得出原始图像的有效表征,这使得CNN能够直接从原始像素中,经过极少的预处理,识别视觉上面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5对于复杂问题的处理结果并不理想。 之后,人们设计了很多方法,想要克服难以训练深度CNN的困难。其中,最著名的是Krizhevsky et al.提出了一个经典的CNN结构,并在图像识别任务上取得了重大突破。其方法的整体框架叫做 AlexNet[4],与 LeNet-5类似,但层次结构上要更加深一些。同时使用了非线性激活函数ReLu[5]与Dropout[6]方法,取得了卓越的效果。
AlexNet大获成功,掀起了卷积神经网络的研究热潮。在这之后,研究人员又提出了其他的改善方法,其中最著名的要数 ZFNet [7], VGGNet [8], GoogleNet [9] 和 ResNet [10]这四种。从结构看,CNN发展的一个方向就是层数变得更多,ILSVRC 2015冠军 ResNet是 AlexNet的20多倍,是 VGGNet的8倍多。通过增加深度,网络便能够利用增加的非线性得出目标函数的近似结构,同时得出更好的特性表征。但是,这样做同时也增加了网络的整体复杂程度,使网络变得难以优化,很容易过拟合。研究人员提出了很多方法来解决这一问题。
在下面的章节中,我会先列出CNN的组成部分,然后介绍CNN不同方面的最近进展,并引入快速计算技巧。探讨CNN在图像分类、物体识别等不同方面的应用进展,最后归纳总结。
基本组成
在不同的资料中,对 CNN的组成部分都有着不同的描述。不过,CNN的基本组成成分是比较一致的。以分类数字的 LeNet-5[1]为例,这个 CNN含有三种类型的神经网络层:
卷积层(Convolutions layer):学习输入数据的特征表示,卷积层由很多的卷积核(convolutional kernel)组成,卷积核用来计算不同的特征图(feature map)。激活函数(activation function)给CNN卷积神经网络引入了非线性,常用的有sigmoid、tanh、ReLU函数。
池化层(Pooling layer):降低卷积层输出的特征向量,同时改善结果,使结构不容易出现过拟合)。典型的操作包括平均池化[10]和最大化池化[11-13]。通过卷积层与池化层,我可以获得更多的抽象特征。
全连接层(Full connected layer):将卷积层和池化层堆叠起来以后,就能够形成一层或多层全连接层,这样就能够实现高阶的推理能力,在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全链接层,后者relu常见于卷积层。
CNN的改进
自从2012年AlexNet成功以后,研究人员设计了很多种完善 CNN 的方法。在这一节中,我将从多个方面进行介绍。
三大改进型CNN
ZFNet [7]对AlexNet的改进首先在第一层的卷积核尺寸从11x11降为7x7,同时将卷积时的步长从4降至2。这样使中间的卷积层扩张从而可以捕捉到更多的信息。
VGGNet [8]将网络的深度扩展到了19层,并且在每个卷积层使用了3x3这种小尺寸的卷积核。结果证明深度对网络性能有着重要影响。
GoogleNet [9]同时增加了网络的宽度与深度,并且相比于更窄更浅的网络,其在没有明显增多的计算量的情况下使网络性能明显增强。
池化层改进
池化层是CNN的重要组成部分,通过减少卷积层之间的连接,降低运算复杂程度。以下是常用的几种循环方法:
1)Lp 池化:Lp池化是建立在复杂细胞运行机制的基础上,受生物启发而来[24] [25]
2)混合池化:受随机Dropout [16] 和 DropConnect [28], Yu et al.启发而来
3)随机池化:随机循环 [30] 是受 dropout启发而来的方法
4)Spatial pyramid pooling:空间金字塔池化[26]可以把任何尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免 cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。一般的CNN都需要输入图像的大小是固定的,这是因为全连接层的输入需要固定输入维度,但在卷积操作是没有对图像尺度有限制,所有作者提出了空间金字塔池化,先让图像进行卷积操作,然后转化成维度的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像。
总结
本文中,我主要从计算机视觉的角度对最近CNN取得的进展进行了深度的研究。我讨论了CNN在不同方面取得的进步:比如,层的设计,活跃函数、损失函数。除了从CNN的各个方面回顾其进展,我还介绍了CNN在计算机视觉任务上的应用,其中包括图像分类、物体检测、物体追踪、姿态估计、文本检测、视觉显著检测、动作识别和场景标签。
虽然在实验的测量中,CNN获得了巨大的成功,但是,仍然还有很多工作值得进一步研究。首先,鉴于最近的CNN变得越来越深,它们也需要大规模的数据库和巨大的计算能力,来展开训练。人为搜集标签数据库要求大量的人力劳动。所以,大家都渴望能开发出无监督式的CNN学习方式。
同时,为了加速训练进程,虽然已经有一些异步的SGD算法,证明了使用CPU和GPU集群可以在这方面获得成功,但是,开放高效可扩展的训练算法依然是有价值的。在训练的时间中,这些深度模型都是对内存有高的要求,并且消耗时间的,这使得它们无法在手机平台上部署。如何在不减少准确度的情况下,降低复杂性并获得快速执行的模型,这是重要的研究方向。
其次,CNN运用于新任务的一个主要障碍是:如何选择合适的超参数?比如学习率、卷积过滤的核大小、层数等等,这需要大量的技术和经验。这些超参数存在内部依赖,这会让调整变得很复杂。最近的研究显示,在学习式CNN架构的选择技巧上,存在巨大的提升空间。
最后,关于CNN依然缺乏统一的理论。目前的CNN模型运作模式依然是黑箱。我甚至都不知道它是如何工作的,工作原理是什么。当下,值得把更多的精力投入到研究CNN的基本规则上去。同时,正如早期的CNN发展是受到了生物视觉感知机制的启发,深度CNN和计算机神经科学二者需要进一步的深入研究。也有一些开放性的问题,比如,生物学上大脑中的学习方式如何帮助人们设计更加高效的深度模型?带权重分享的回归计算方式是否可以计算人类的视觉皮质等等。这篇文章不仅能让我更好地理解CNN,同时我也希望能帮助到想要学习研究CNN的朋友们。
参考文献
[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
[2] B. B. Le Cun, J. S. Denker, D. Henderson, R. E. Howard, W. Hub-bard, and L. D. Jackel, “Handwritten digit recognition with a back-propagation network,”in Advances in neural information processing systems. Citeseer, 1990.
[3] R. Hecht-Nielsen, “Theory of the backpropagation neural network,” in International Joint Conference on Neural Networks, 1989, pp. 593–605.
[4] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classfication with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[5] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in ICML, 2010, pp. 807–814.
[6] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” arXiv preprint arXiv:1207.0580, 2012.
[7] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in ECCV, 2014.
[8] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in ICLR, 2015.
[9] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” CoRR, vol. abs/1409.4842, 2014.
[10] T. Wang, D. Wu, A. Coates, and A. Ng, “End-to-end text recognition with convolutional neural networks,” in International Conference on Pattern Recognition (ICPR), 2012, pp. 3304–3308.
[11] J. Yang, K. Yu, Y. Gong, and T. Huang, “Linear spatial pyramid matching using sparse coding for image classification,” in CVPR, 2009.
[12] Y. Boureau, J. Ponce, and Y. LeCun, “A theoretical analysis of feature pooling in visual recognition,” in ICML, 2010, pp. 111–118.
[13] M. Ranzato, F. J. Huang, Y. Boureau, and Y. LeCun, “Unsupervised learning of invariant feature hierarchies with applications to object recognition,”in CVPR, 2007.
[14] Y. Tang, “Deep learning using linear support vector machines,”arXiv preprint arXiv:1306.0239, 2013.
[15] M. Lin, Q. Chen, and S. Yan, “Network in network,” CoRR, vol.abs/1312.4400, 2013.
[16] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Re-thinking the Inception Architecture for Computer Vision,” 2015, arXiv:1512.00567v1.
[17] E. P. Simoncelli and D. J. Heeger, “A model of neuronal responses in visual area mt,” Vision research, vol. 38, no. 5, pp. 743–761, 1998.
[18] A. Hyv¨arinen and U. K¨oster, “Complex cell pooling and the statistics of natural images,” Network: Computation in Neural Systems, vol. 18, no. 2, pp. 81–100, 2007.
[19] J. B. Estrach, A. Szlam, and Y. Lecun, “Signal recovery from pooling representations,” in ICML, 2014, pp. 307–315.
[20] C. Gulcehre, K. Cho, R. Pascanu, and Y. Bengio, “Learned-norm pooling for deep feedforward and recurrent neural networks,” in Machine Learning and Knowledge Discovery in Databases. Springer, 2014, pp. 530–546.
[21] L. Wan, M. Zeiler, S. Zhang, Y. L. Cun, and R. Fergus, “Regularization of neural networks using dropconnect,” in ICML, 2013, pp. 1058–1066.
[22] D. Yu, H. Wang, P. Chen, and Z. Wei, “Mixed pooling for convolutional neural networks,” in Rough Sets and Knowledge Technology. Springer, 2014, pp. 364–375.
[23] M. D. Zeiler and R. Fergus, “Stochastic pooling for regularization of deep convolutional neural networks,” CoRR, vol. abs/1301.3557, 2013.
[24] O. Rippel, J. Snoek, and R. P. Adams, “Spectral representations for convolutional neural networks,” arXiv preprint arXiv:1506.03767, 2015.
[25] M. Mathieu, M. Henaff, and Y. LeCun, “Fast training of convolutional networks through ffts,” arXiv preprint arXiv:1312.5851, 2013.
[26] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in Computer Vision–ECCV 2014, 2014, pp. 346–361.12
[27] S. Singh, A. Gupta, and A. Efros, “Unsupervised discovery of mid-level discriminative patches,” ECCV, pp. 73–86, 2012.
[28] Y. Gong, L. Wang, R. Guo, and S. Lazebnik, “Multi-scale orderless pooling of deep convolutional activation features,” in ECCV, 2014.
[29] H. J´egou, F. Perronnin, M. Douze, J. Sanchez, P. Perez, and C. Schmid,“Aggregating local image descriptors into compact codes,” PAMI, vol. 34, no. 9, pp. 1704–1716, 2012.
[30] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in ICML, 2013.
[31] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” arXiv preprint arXiv:1502.01852, 2015.