hadoop基础----hadoop实战(一)-----hadoop环境安装---手动安装官方1.0版本
准备工作
前面我们已经了解了有关于hadoop的相关原理
hadoop基础----hadoop理论(一)----Hadoop简介
hadoop基础----hadoop理论(二)-----hadoop学习路线(持续更新)
hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详解
hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce详解
本章开始进入实际操作阶段
因为在学习阶段一般我们没有那么多实体机来进行操作。也就是不能实现真正的分布式。
但是我们可以通过虚拟机来模拟分布式。
所以在安装hadoop之前,我们需要先准备好3台虚拟机。
这里我们使用的VMware Workstation
新建虚拟机的步骤如下:
hadoop基础------虚拟机(二)---虚拟机安装以及安装linux系统
根据上面的文章,我们就已经有了3台CentOS 6.4系统的虚拟机。
为了方便我们操作命令,我们需要让虚拟机与本机共享剪切板也就是我在本机剪切的命令能够直接粘贴到虚拟机里使用,相关设置参考:
hadoop基础-------虚拟机(三)-----VMware虚拟机下linux系统的与windows主机实现复制粘贴
然后我们需要把它们之间的网络调试一下,目的是 让3台虚拟机都能上外网而且 与 本机 能够相互通信。
因为我们是克隆的机子 所以虚拟机的mac是有冲突的 详细的解决注意看 linux基础十中的 可能遇到的问题。
虚拟机网络模式了解(熟悉的人可直接配置成桥接,并设置ip即可,不熟悉的需要看详细步骤):
hadoop基础-------虚拟机(五)-----虚拟机linux系统网络配置的三种模式
详细网络配置步骤在:
linux基础(十)----linux网络配置详细步骤---桥接模式和两台机子的远程通信
网络调好之后我们就可以就可以开始安装 hadoop环境了。
但是hadoop是开源的,所以发展到现在,已经有了很多分支版本。
由于Hadoop版本混乱多变,因此,Hadoop的版本选择问题一直令很多初级用户苦恼。
所以我们有必要对如果选取版本和了解版本信息的方法进行熟悉:
hadoop基础----hadoop实战(零)-----hadoop的平台版本选择
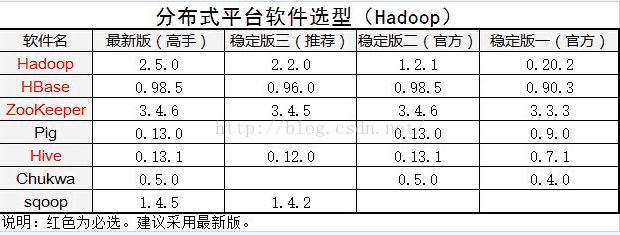
我们在生产环境中 建议使用第三方发行版,但是这里为了学习hadoop的安装原理等 我们这一次先手动安装hadoop1.0版,等学习到2.0版本的时候 再使用 第三方发行版进行安装。
根据上表 我们这里 就要进行 1.2.1版本的 Hadoop安装。
官网安装配置文档
http://hadoop.apache.org/docs/r1.2.1/cluster_setup.html
熟悉虚拟机环境
查看到系统版本
使用命令
cat /etc/redhat-release查看主机名
使用命令
hostname 查看主机名
一般没修改过的话 都是localhost.localdomain
我们需要修改主机名方便区分和识别。
设置主机名
临时设置
使用hostname命令设置主机名。格式为:hostname 主机名,如下。
[root@joe /]# hostname hadoop1
该设置为临时生效。重新启动系统后,设置失效。
永久设置
编辑/etc/sysconfig/network文件中的HOSTNAME字段就可以修改主机名。如下所示:
vim /etc/sysconfig/network NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=hadoop1
HOSTNAME=hadoop1 表示主机设置为hadoop1 .
注意:修改主机名后,需要重启系统后永久生效。
查看ip
使用命令查看ip
ifconfig架构和角色分配
我们先整理出三台虚拟机的ip和主机名
192.168.30.180 hadoop0
192.168.30.189 hadoop1
192.168.30.186 hadoop2
角色如下
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
192.168.30.189 hadoop1 作为slave担任DataNode 和 TaskTracker
192.168.30.186 hadoop2 作为slave担任DataNode 和 TaskTracker
其中NameNode/DataNode工作在HDFS层,JobTracker/TaskTracker工作在MapReduce层。
设备列表中hadoop0是master,担任NameNode 和JobTracker,hadoop1 ,hadoop2为slave,担任DataNode和TaskTracker。secondary namenode在hadoop 1.03中被废弃,用checkpoint node或backupnode来代替。这里暂没有配checkpoint node或backupnode。
用户权限配置
在各机器建立同名用户joe,可选自己喜欢的名称,用于管理hadoop。
如果当前是超级用户root
新建如下:
adduser joepasswd joe关于用户设置的详情可查看
linux管理(一)---用户管理及权限
下载hadoop安装包
进入官网中找到镜像页面找到我们使用的版本,这里是1.2.1稳定版。下载步骤如下图:
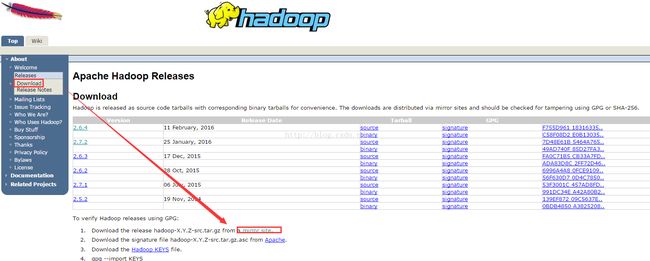
任意选择一个镜像,我这里选择第一个:

选择版本:

选择需要下载的文件,因为我们是linux系统中使用所以下载hadoop-1.2.1.tar.gz
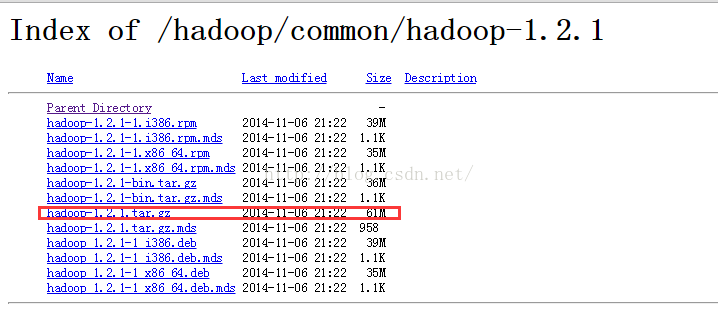
ps: 熟悉linux系统的同学也可以直接使用wget命令下载
wget http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz配置hosts
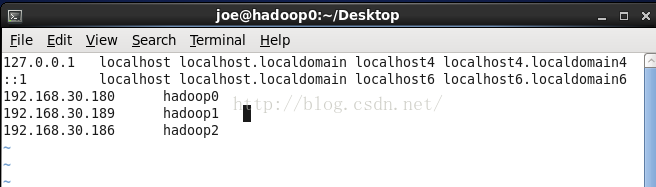
在每一台机器的/etc/hosts文件中加入ip地址和主机名的映射,也就是把之前查询出来的ip和主机名信息(下面的三行)加入到hosts文件中。
192.168.30.180 hadoop0
192.168.30.189 hadoop1
192.168.30.186 hadoop2
vim /etc/hosts配置好的hosts内容如下所示:
ps:如果遇到'readonly' option is set (add ! to override) 需要用root权限
su -输入root密码再编辑即可。
配置ssh无密码访问
ssh 用于登录远程主机, 并且在远程主机上执行命令. 它的目的是替换 rlogin 和 rsh, 同时在不安全的网络之上, 两个互不信任的主机之间, 提供加密的, 安全的通信连接. X11 连接和任意 TCP/IP 端口均可以通过此安全通道转发(forward).当用户通过连接并登录主机 hostname 后, 根据所用的协议版本, 用户必须通过钥匙的方法向远程主机证明他/她的身份。
执行以下命令:
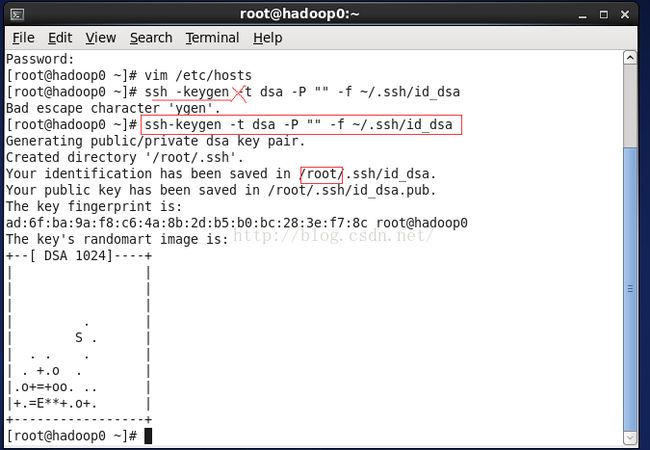
生成密钥文件
ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsaps:主要 不是 shh -keygen 中间没有空格。然后当前用户也需要注意,因为我们主要是用之前的同名用户joe在操作,所以应该用joe用户生成密钥文件。这样它们生成的目录路径是不一样的。
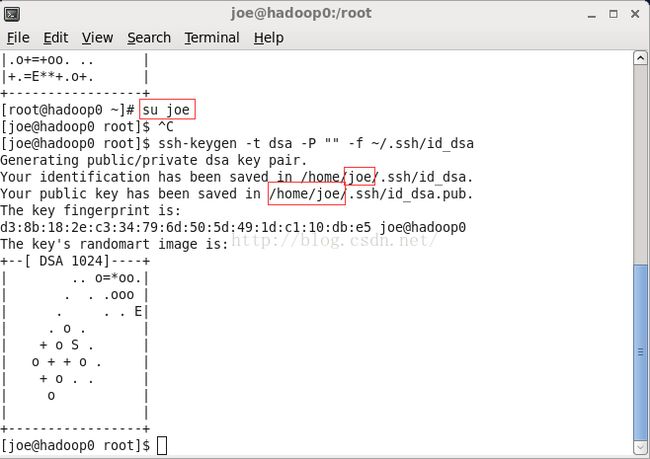
把密钥内容写到授权文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys并且把所有节点的authorized_keys的内容相互拷贝加入到每一个节点的authorized_keys中,配置完成后每一个节点的authorized_keys文件的内容应该是一样的。


这是其中一台的授权文件,我们把三台的内容都取出来 组合成最终的文件。最终每一台的authorized_keys内容都如下:
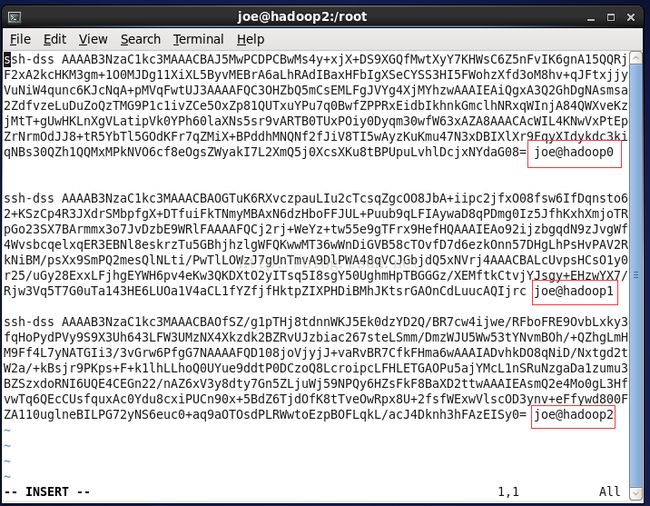
密钥文件授权
chmod 700 ~/.ssh
chmod 644 ~/.ssh/authorized_keys把密钥添加到缓存中
ssh-add测试ssh功能
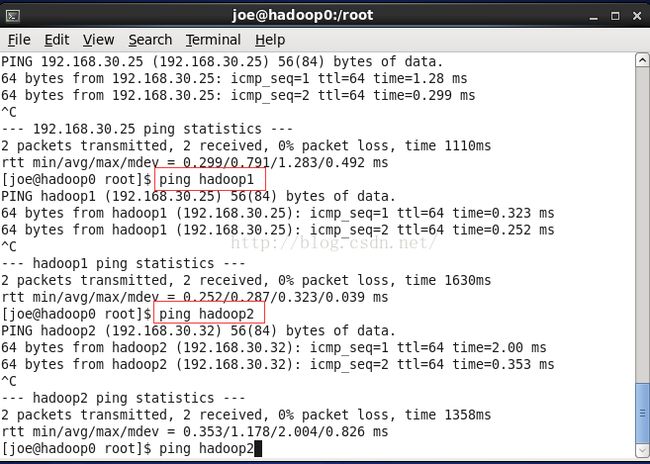
在继续安装前,一定要保证这一步安装正确,可以使用ssh 主机名命令来测试是否成功,例如:ssh hadoop1,如果成功则会进入到hadoop1机器中。
第一次连接可能会遇到询问:
The authenticity of host 'hadoop0 (192.168.30.180)' can't be established.
RSA key fingerprint is 21:b8:6a:49:c3:41:96:aa:5a:f0:cd:76:75:6c:1f:4e.
Are you sure you want to continue connecting (yes/no)? ^
如果回答yes的话能无密码登录 则没问题 这样会生成一个know hosts文件下次登录后就不会询问了,这种情况是主机有变动,估计是ip变了。

如果回答yes的话会再次询问你的密码才能登录就不能达到我们无密码登录的目的,这种情况需要解决一下,解决的方法看下文的可能遇到的问题。
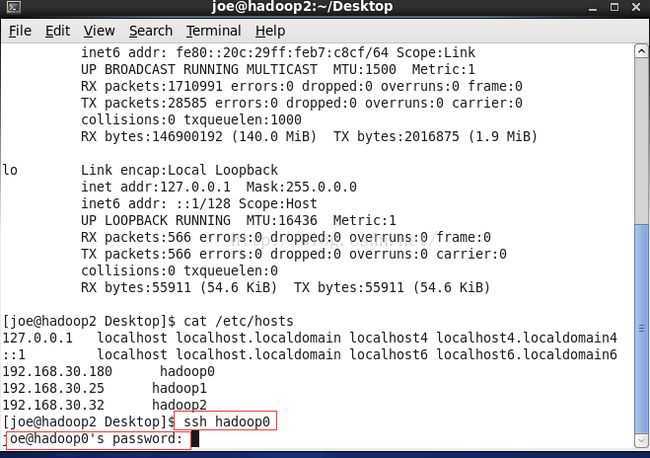
成功无密码连接之后 ~/.ssh/路径下会生成一个know hosts文件记录 成功连接过的密钥。
我们依次检查几台机器的~/.ssh/know hosts,如果都成功互联了对方,则ssh无密码登录设置成功。
cat ~/.ssh/know hosts
PS:
可能遇到的问题ssh: connect to host hadoop1 port 22: No route to host
这种情况是虚拟机的ip与hosts中写的不对应了。
解决方法
重新检查 几台机器的ip 以及相互之间 分别用 ip和 主机名是否能ping通。重新编辑hosts配置文件后重新生成密钥。
可能遇到的问题:The authenticity of host 'hadoop0 (192.168.30.180)' can't be established.
Are you sure you want to continue connecting (yes/no)? ^
如果回答yes的话能无密码登录 则没问题 这样会生成一个know hosts文件下次登录后就不会询问了,这种情况是主机有变动,估计是ip变了。
如果回答yes的话会再次询问你的密码才能登录。
就不能达到我们无密码登录的目的。
原因
密钥文件不起作用---权限问题或者主机的ip等信息有变动。
解决方法一
重新生成一遍密钥 分发一次。
ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys授权密钥文件
chmod 700 ~/.ssh
chmod 644 ~/.ssh/authorized_keys检查是否生成正确
ll ~/.ssh/
解决方法二
使用命令(相对安全的内网时才建议使用)
ssh -o StrictHostKeyChecking=no hadoop1 能实现无密码登录。
SSH对主机的public_key的检查等级是根据StrictHostKeyChecking变量来配置的。默认情况下,StrictHostKeyChecking=ask。简单所下它的三种配置值:
1.StrictHostKeyChecking=no
#最不安全的级别,当然也没有那么多烦人的提示了,相对安全的内网测试时建议使用。如果连接server的key在本地不存在,那么就自动添加到文件中(默认是known_hosts),并且给出一个警告。
2.StrictHostKeyChecking=ask #默认的级别,就是出现刚才的提示了。如果连接和key不匹配,给出提示,并拒绝登录。
3.StrictHostKeyChecking=yes #最安全的级别,如果连接与key不匹配,就拒绝连接,不会提示详细信息。
解决方法三
这个也是修改StrictHostKeyChecking配置实现无密码登录。
不过是直接修改配置文件。(相对安全的内网时才建议使用)
修改/etc/ssh/ssh_config文件(或$HOME/.ssh/config)中的配置,添加如下两行配置:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null当然,这是内网中非常信任的服务器之间的ssh连接,所以不考虑安全问题,就直接去掉了主机密钥(host key)的检查。
可能遇到问题:Agent admitted failure to sign using the key
解决方法
使用命令
ssh-add再尝试一次 ssh hadoop1
成功了。无密码登录成功。

可能遇到的情况:hadoop0能免密ssh到hadoop2,但hadoop2ssh到hadoop0需要密码
这种情况是因为 hadoop0中的密钥文件authorized_keys中hadoop2的密钥字符串有问题。 这种情况需要仔细检查一下 是否少了开头结尾的一些字符,或者 重新把hadoop2中authorized_keys的hadoop2的密钥字符串重新粘贴过来到hadoop0中一次。应该就可以了。 如果还是不行 就在 hadoop2中重新执行一次生成密钥 授权,把新的密钥粘贴到
hadoop0中的密钥文件authorized_keys中,并给hadoop0中的密钥文件authorized_keys授权 664即可。

安装hadoop
我们在前面已经下载了hadoop-1.2.1.tar.gz文件,现在用ssh工具把安装文件分别放到三台机子中的/home/joe目录下新建的hadoop文件夹中。
如下图:
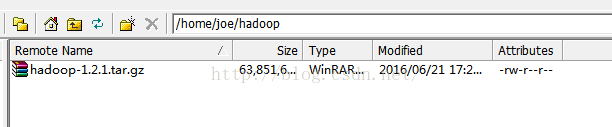
然后在控制台进入/home/joe/hadoop路径执行下面的命令把hadoop解压出来则安装完成。
cd /home/joe/hadoop
tar -zxvf hadoop-1.2.1.tar.gz 配置hadoop
因为在配置过程中会使用jdk的路径,如果之前没安装jdk的话可以安装下面的步骤把每一台的机子都安装上jdk。
linux软件(一)---CentOS安装jdk
进入到hadoop安装目录,(我自己的是/home/joe/hadoop/),运行ls看到conf文件夹,这里存放的是配置相关信息;bin文件夹,存放的是可执行的文件;
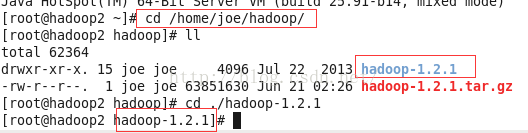
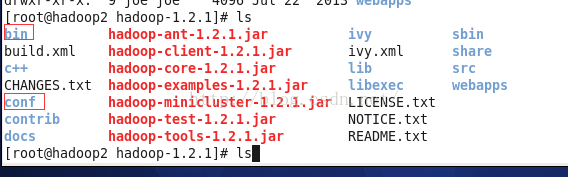
进入conf目录,配置hadoop文件,我们需要配置以下几个文件:
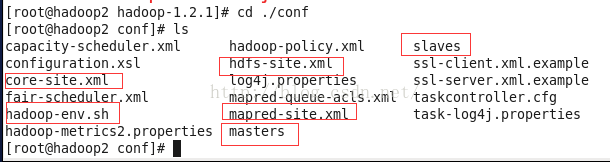
cd /home/joe/hadoop/hadoop-1.2.1/conf配置masters文件
我们上面已经做了角色分配
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
vim masters
配置slaves文件
192.168.30.189 hadoop1 作为slave担任DataNode 和 TaskTracker
192.168.30.186 hadoop2 作为slave担任DataNode 和 TaskTracker
vim slaves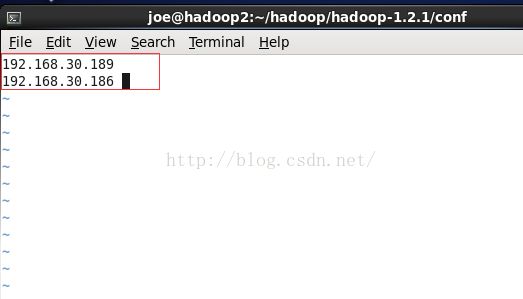
配置hadoop-env.sh文件
这里是配置jdk的安装地址,也就是jdk安装配置时的JAVA_HOME。我这里的路径是/home/joe/java/jdk1.8.0_91
vim hadoop-env.shexport JAVA_HOME=/home/joe/java/jdk1.8.0_91
配置hdfs-site.xml文件
配置replication,即数据保存份数。一般根据集群的机器数量来调整。我们这里是3台,可以设置成3。
vim hdfs-site.xml
在
如图:

PS:配置中还可以指定dfs.data.dir数据存储路径等参数。我们先用默认的,如有特殊需求可参考官网的配置。
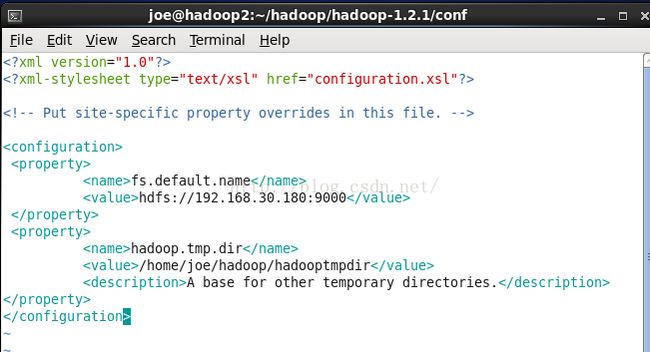
配置core-site.xml
配置namenode的地址和端口,以及临时目录
回顾一下角色:
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
端口可以自己选择 这里采用9000
vim core-site.xml
在
如图:
配置mapred-site.xml
配置jobtracker的地址和端口
回顾一下角色:
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
所以这里的ip还是180 跟 core-site.xml中的一样。
但是端口需要另外分配一个,因为NameNode已经用了9000端口,所以这里我们用9001.
vim mapred-site.xml
在
如图:

同步配置
这样我们就配置好了其中一台机器,其它几台机器也需要一模一样的配置。
我们可以分别手动去设置。但最好是 把配置复制过去。
我这里把整个hadoop文件夹复制过去,我首先设置了hadoop2,这里需要赋值到hadoop0和hadoop1:
scp -r /home/joe/hadoop/ hadoop0:/home/joe/
scp -r /home/joe/hadoop/ hadoop1:/home/joe/
检查配置
我们已经把hadoop2的给同步复制过来了,这里的路径要尤其注意,需要确保是 原安装路径的覆盖 替换,并检查 我们配置文件是否已经跟我们在hadoop2中的配置一样。

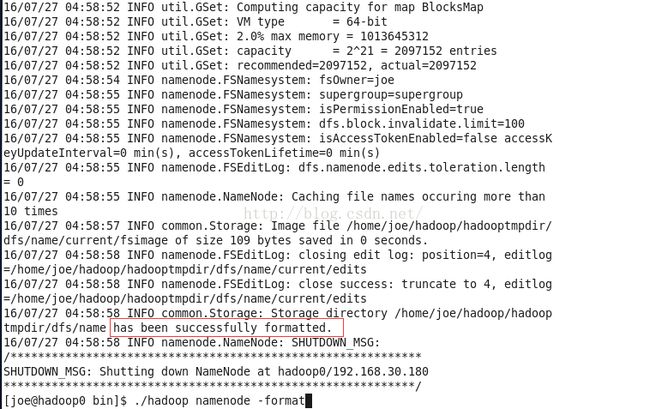
格式化hadoop的文件系统HDFS
配置完成之后我们已经安装完毕,现在做启动前的准备:格式化hadoop的文件系统。
三台机器任意一台 进入bin目录
cd /home/joe/hadoop/hadoop-1.2.1/bin/
./hadoop namenode -format
关闭master防火墙
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
防火墙关闭
也可把相应的配置中的端口打开,例如我上面设置的9000和9001,需要把每台机器的这2个端口都打开,
我这里为了方便,把hadoop0 机器(也就是master)的防火墙暂时关闭。需要root权限!再关闭防火墙。否则关闭无效。
service iptables stop
可以用下面命令查询防火墙状态,如果不是root权限该命令无效。
service iptables status
切换到root后关闭防火墙
su root
service iptables stop
service iptables status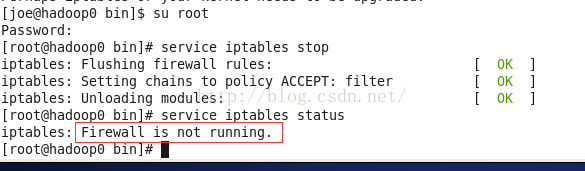
启动hadoop
切换回joe用户,因为我们只配置了joe用户在三台机器之间的互通访问。在三台机子中的任意一台进入hadoop的bin目录启动
cd /home/joe/hadoop/hadoop-1.2.1/bin/
./start-all.sh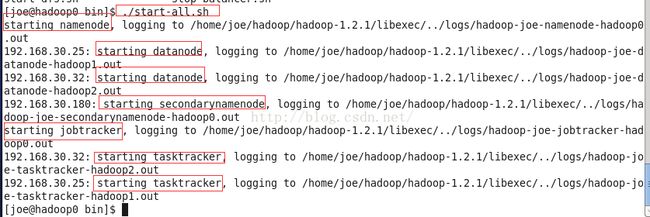
验证是否启动成功
方法一
验证Name和JobTracker
在master节点运行jps,如果出现以下红色框里的进程,说明NameNode 和JobTracker启动成功。
我们这里master是hadoop0
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
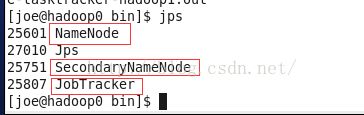
验证DataNode 和 TaskTracker
在slave节点运行jps,如果出现以下红色框里的进程,说明DataNode 和 TaskTracker启动成功
192.168.30.189 hadoop1 作为slave担任DataNode 和 TaskTracker
192.168.30.186 hadoop2 作为slave担任DataNode 和 TaskTracker
我们分别在 hadoop1和hadoop2运行jps
可能遇到的情况
DataNode 和TaskTracker没启动起来

解决方法
需要去相关的日志中查看原因,相应解决。如果要查看hadoop1的日志则需要在hadoop1中查看
cd /home/joe/hadoop/hadoop-1.2.1/libexec/../logs
ls
tail -f -n 800 hadoop-joe-datanode-hadoop1.log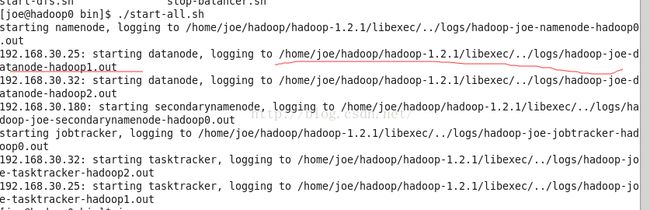
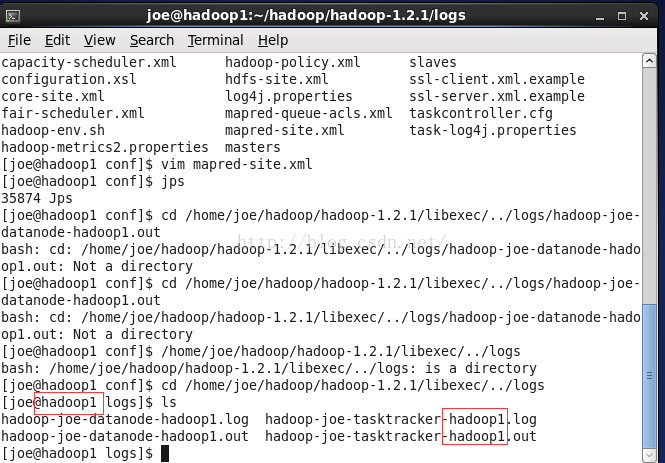

遇到的问题是java.net.NoRouteToHostException: No route to host
在配置hadoop的时候,很容易遇到以上错误,遇到以上问题的时候,一般可以通过以下几种方法解决。
1、从namenode主机ping其它主机名(如:ping slave1),如果ping不通,原因可能是namenode节点的/etc/hosts配置错误。
2、从datanode主机ping namenode主机名,如果ping不通,原因可能是datenode节点的/etc/hosts配置的配置错误。
3、查看namenode主机的9000(具体根据core-site.xml中的fs.default.name节点配置)端口,是否打开。
netstat -lnp|grep 9000#9000请换为你的设置的端口
执行以上命令,可以查看到9000端口正在被哪个进程使用。如下图,进程号为25601。

ps 25601
如果是nameNode 在使用该端口,则是对的。
4、关闭系统防火墙。这是最容易出现的问题。用此命令service iptables stop关闭后。
进入hadoop的bin目录 用下面命令
./stop-all.sh停止所有集群再启动一遍
./start-all.sh一切正常集群正常使用。
方法二
通过浏览器查看---端口是hadoop默认的 --NameNode是50070,JobTracker是50030,TaskTracker是50060.
192.168.30.180 hadoop0 作为master担任NameNode 和 JobTracker
192.168.30.189 hadoop1 作为slave担任DataNode 和 TaskTracker
192.168.30.186 hadoop2 作为slave担任DataNode 和 TaskTracker
NameNode
http://192.168.30.180:50070/dfshealth.jsp

JobTracker
http://192.168.30.180:50030/jobtracker.jsp

TaskTracker
http://192.168.30.189:50060/tasktracker.jsphttp://192.168.30.186:50060/tasktracker.jsp
PS:这2个打不开的话 需要把他们的防火墙也关闭才能用局域网内的浏览器访问。

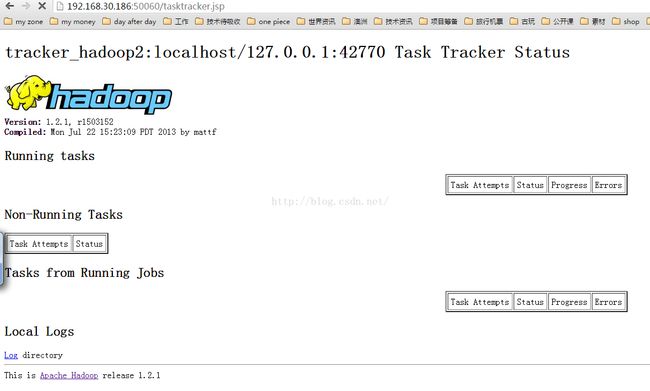
一些启动停止的命令
正式启动Hadoop啦,bin/目录下有很多启动脚本,可以根据自己的需要来启动停止Hadoop的守护进程。
start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、JobTracker、 TaskTrack
stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、JobTracker、 TaskTrack
start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
hadoop-daemons.sh start namenode 单独启动NameNode守护进程
hadoop-daemons.sh stop namenode单独停止NameNode守护进程
hadoop-daemons.sh start datanode 单独启动DataNode守护进程
hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
hadoop-daemons.sh start secondarynamenode单独启动SecondaryNameNode守护进程
hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
start-mapred.sh 启动Hadoop MapReduce守护进程JobTracker和TaskTracker
stop-mapred.sh停止Hadoop MapReduce守护进程JobTracker和TaskTracker
hadoop-daemons.sh start jobtracker 单独启动JobTracker守护进程
hadoop-daemons.sh stop jobtracker 单独停止JobTracker守护进程
hadoop-daemons.sh start tasktracker 单独启动TaskTracker守护进程
hadoop-daemons.sh stop tasktracker 单独启动TaskTracker守护进程
如果Hadoop集群是第一次启动,可以用start-all.sh。比较常用的启动方式是一个一个守护进程来启动,启动的步骤如下。
1.启动Hadoop的HDFS模块里的守护进程
HDFS里面的守护进程启动也有顺序,即:
1)启动NameNode守护进程;
2)启动DataNode守护进程;
3)启动SecondaryNameNode守护进程。
2.启动MapReduce模块里面的守护进程
MapReduce的守护进程启动也是有顺序的,即:
1)启动 JobTracker守护进程;
2)启动TaskTracker守护进程。
关闭的步骤正好相反,在这里就不描述了,可以自己试一下。
注意 正常情况下,我们是不使用start-all.sh和stop-all.sh来启动和停止Hadoop集群的。这样出错了不好找原因。建议一个一个守护进程来启动,哪个启动失败就去看相应的log日志,这样就缩小了找错的范围。