python网络爬虫--爬取淘宝联盟
互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。
网络爬虫,也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网,Spider就是一只在网上爬来爬去的蜘蛛。网络爬虫就是根据网页的地址来寻找网页的,也就是全球统一资源定位符URL,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定。
爬虫的基本流程:
-
发送请求
-
获得响应内容
-
解析内容
-
保存数据
爬虫所需的工具:
1. 请求库:requests,selenium(可以驱动浏览器解析渲染CSS和JS,但有性能劣势(有用没用的网页都会加载))
2. 解析库:正则,xpath,beautifulsoup,pyquery
3. 存储库:文件,MySQL,Mongodb,Redis
下面实现一个爬虫,爬取符合条件的淘宝联盟网站的商品。
1. URL分析
我们首先打开淘宝联盟网址,在搜索栏随便输入一件 商品,比如“鞋子”
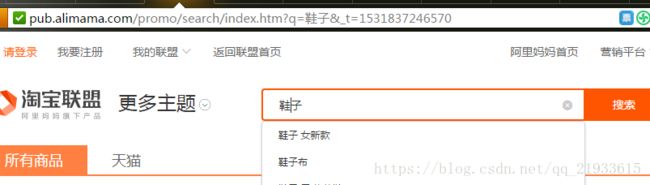
2. 按F12可以查看访问当前网页发送的所有请求

现在发现没东西,因为有的网站是动态加载的,当我们下拉滚动条时,看到有如下请求:
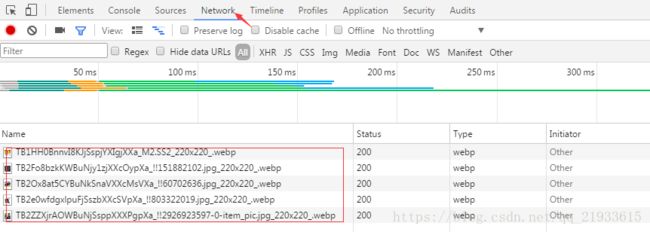
然后点击下一页,有 下面的请求:

URL:http://pub.alimama.com/items/search.json?q=%E9%9E%8B%E5%AD%90&_t=1531837246570&toPage=2&perPageSize=50&auctionTag=&shopTag=yxjh&t=1531837861744&_tb_token_=58efe1f76686e&pvid=10_218.88.24.143_1018_1531837246340
通过分析这就是我们所要请求的URL。
3. 请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意: 一般做爬虫都会加上请求头
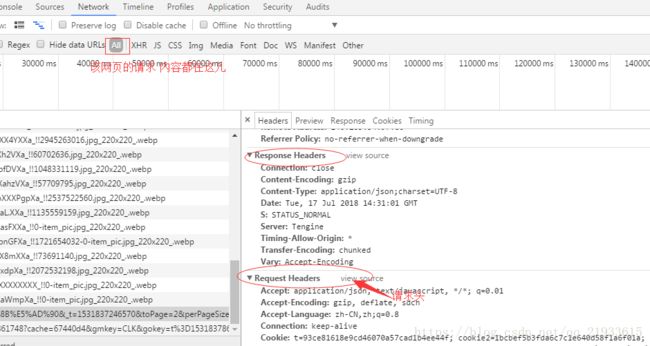
请求头需要注意的参数:
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
4、请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
5、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2. 请求并获取响应
我们通过不同的方式来分别请求并获取响应,具体实现如下:
1.url请求,获取响应的json数据,并将json数据转换成dict 采用 urllib2 实现
#url请求,获取响应的json数据,并将json数据转换成dict 采用 urllib2 实现
def getJSONText(url):
try:
page = urllib2.urlopen(url)
data = page.read()
#print (data)
#print (type(data))
#dict_data = json.loads(data)
dict_data = demjson.decode(data)
#print dict_data
#print type(dict_data)
return dict_data
except:
return ""2.#url请求,获取响应的json数据,并将json数据转换成dict 采用 添加请求头、设置代理的方式 实现
#url请求,获取响应的json数据,并将json数据转换成dict 采用 添加请求头、设置代理的方式 实现
def getJSONText2(url):
try:
proxies = {
"http": "http://221.10.159.234:1337",
"https": "https://60.255.186.169:8888",
}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
data = requests.get(url, headers=headers,proxies=proxies).text
print (data)
print (type(data))
# dict_data = json.loads(data)
dict_data = demjson.decode(data)
print dict_data
print type(dict_data)
return dict_data
except:
return "" 3.采用selenium实现
#url请求,获取响应的json数据,并将json数据转换成dict 采用selenium实现
def get_browser_text(url):
#browser = webdriver.Chrome(executable_path="C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe")
browser = webdriver.Firefox(executable_path="C:\\Program Files (x86)\\Mozilla Firefox\\geckodriver.exe")
try:
browser.get(url)
print(browser.page_source)
browserdata = browser.page_source
browser.close()
# res = r'(.*?)'
res = r'(.*?)
'
json_data = re.findall(res, browserdata, re.S | re.M)
print json_data
for value in json_data:
print value
dict_data = demjson.decode(json_data)
print 'dict_data:'
print dict_data
# print type(dict_data)
return dict_data
except:
return ""4.
# 获取单个商品的HTML代码并用正则匹配出描述、服务、物流3项参数 采用urllib2
def getHTMLText(url):
try:
data = urllib2.urlopen(url).read()
res = r'3. 爬虫完整代码如下:
#coding=utf-8
__author__ = 'yansong'
# 2018.07.12
# 抓取淘宝联盟 比率>10 ,描述、服务、物流3项参数高于或持平于同行业的商品图片。
import json
import demjson
import urllib2
import os
import time
import requests
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import sys
reload(sys)
sys.setdefaultencoding('utf8')
path_name = u'T恤宽松日系男款' #图片保存的文件夹名称
Myname = u'T恤宽松日系男款' #搜索关键字
# 创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,path_name)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#url请求,获取响应的json数据,并将json数据转换成dict 采用selenium实现
def get_browser_text(url):
#browser = webdriver.Chrome(executable_path="C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe")
browser = webdriver.Firefox(executable_path="C:\\Program Files (x86)\\Mozilla Firefox\\geckodriver.exe")
try:
browser.get(url)
print(browser.page_source)
browserdata = browser.page_source
browser.close()
# res = r'(.*?)'
res = r'(.*?)
'
json_data = re.findall(res, browserdata, re.S | re.M)
print json_data
for value in json_data:
print value
dict_data = demjson.decode(json_data)
print 'dict_data:'
print dict_data
# print type(dict_data)
return dict_data
except:
return ""
#url请求,获取响应的json数据,并将json数据转换成dict 采用 urllib2 实现
def getJSONText(url):
try:
page = urllib2.urlopen(url)
data = page.read()
#print (data)
#print (type(data))
#dict_data = json.loads(data)
dict_data = demjson.decode(data)
#print dict_data
#print type(dict_data)
return dict_data
except:
return ""
# 获取单个商品的HTML代码并用正则匹配出描述、服务、物流3项参数 采用urllib2
def getHTMLText(url):
try:
data = urllib2.urlopen(url).read()
res = r' 10.00:
# time.sleep(1)
# print '详细信息:'
# print type(tkRate)
# print type(zkPrice)
# print '比率:%f' % (tkRate)
# print '价格:%f' % (zkPrice)
# print sellerId
# print auctionId
# print pictUrl
# print auctionUrl # 淘宝链接
# print type(sellerId)
print auctionUrl
# 每件商品的子url (描述相符、发货速度、服务态度 等信息)
# sub_url = ('http://pub.alimama.com/pubauc/searchPromotionInfo.json?oriMemberId=%d&blockId=&t=1531369204612&_tb_token_=e370663ebef17&pvid=10_118.112.188.32_760_1531368931581' % (sellerId))
sub_url = auctionUrl # 每件商品的淘宝url
sub_url_data = getHTMLText(sub_url) # 获取店铺的 描述、服务、物流 信息
print type(sub_url_data)
print len(sub_url_data)
# 如果返回的是空字符串, 则说明没有取到我们想要的字段,是因为淘宝有不同的页面,对于这种页面我们需要进一步分析下面的url
if (len(sub_url_data) == 0):
info_url = ('https://world.taobao.com/item/%d.htm' % (auctionId))
info_data = urllib2.urlopen(info_url).read()
res_info = r' 4. 运行效果
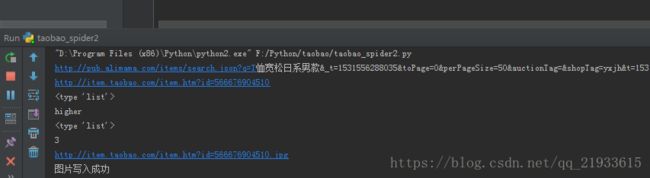
抓取的图片在指定的目录下:
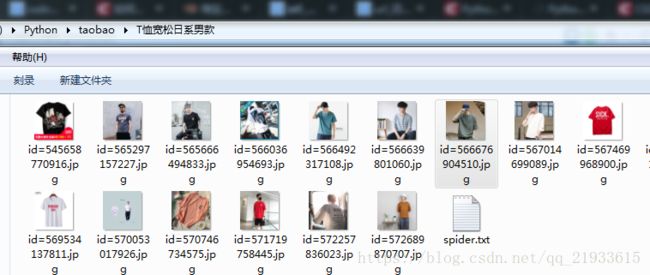
同时写了一个spider.txt文件,里面是详细的URL信息:

单个商品的淘宝链接如:http://item.taobao.com/item.htm?id=566676904510
淘宝链接构成: http://item.taobao.com/item.htm?+id=566676904510 抓取的图片名称是以商品的id来命名的,我们根据图片就可以快速找到该商品,该爬虫抓取的都是 比率>10 ,描述、服务、物流3项参数高于或持平于同行业的商品,也可以根据自己需要,抓取价格、销售量等符合自己要求的商品。