Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 2.1. Text Detection
- 2.2. Text Recognition
- 2.3. Text Spotting Systems
- 3. Model
- 3.1. Overall Architecture
- 3.2. Text Proposal Network
- 3.3. Region Feature Encoder
- 3.4. Text Detection and Recognition
- 3.5. Loss Functions and Training
- 4. Experiments
- 4.1. Evaluation under Different Model Settings
- 4.2. Joint Training vs. Separate Training
- 4.3. Comparison with Other Methods
- 4.4. Speed
- 5. Conclusion
Abstract
In this work, we jointly address the problem of text detection and recognition in natural scene images based on convolutional recurrent neural networks. We propose a unified network that simultaneously localizes and recognizes text with a single forward pass, avoiding intermediate processes like image cropping and feature re-calculation, word separation, or character grouping. In contrast to existing approaches that consider text detection and recognition as two distinct tasks and tackle them one by one, the proposed framework settles these two tasks concurrently. The whole framework can be trained end-to-end, requiring only images, the groundtruth bounding boxes and text labels. Through end-to-end training, the learned features can be more informative, which improves the overall performance. The convolutional features are calculated only once and shared by both detection and recognition, which saves processing time. Our proposed method has achieved competitive performance on several benchmark datasets.
在这项工作中,我们共同解决了基于卷积递归神经网络的自然场景图像中文本检测和识别的问题。我们提出了一个统一的网络,该网络可以通过一次前向传递同时定位和识别文本,避免了诸如图像裁剪和特征重新计算,单词分离或字符分组之类的中间过程。与将文本检测和识别视为两个不同的任务并一一解决的现有方法相比,所提出的框架同时解决了这两个任务。整个框架可以端到端地进行培训,只需要图像,前景边界框和文本标签即可。通过端到端培训,学习到的功能可以提供更多信息,从而提高整体性能。卷积特征仅计算一次,并由检测和识别共享,从而节省了处理时间。我们提出的方法已经在几个基准数据集上取得了竞争性能。
1. Introduction
Text in natural scene images contains rich semantic information and is of great value for image understanding. As an important task in image analysis, scene text spotting, including both text detection and word recognition, attracts much attention in computer vision field. It has many potential applications, ranging from web image searching, robot navigation, to image retrieval.
自然场景图像中的文本包含丰富的语义信息,对于图像理解具有重要的价值。 作为图像分析中的一项重要任务,场景文本点检(包括文本检测和单词识别)在计算机视觉领域引起了很多关注。它具有许多潜在的应用程序,从网络图像搜索,机器人导航到图像检索。
Due to the large variability of text patterns and the highly complicated background, text spotting in natural scene images is much more challenging than from scanned documents. Although significant progress has been made recently based on Deep Neural Network (DNN) techniques, it is still an open problem [36].
由于文本模式的可变性和背景高度复杂,自然场景图像中的文本斑点比来自扫描文档的文本更具挑战性。 尽管基于深度神经网络(DNN)技术最近已经取得了重大进展,但这仍然是一个开放的问题[36]。
Previous works [28, 2, 12, 11] usually divide text spotting into a sequence of distinct sub-tasks. Text detection is performed firstly with a high recall to get candidate regions of text. Then word recognition is applied on the cropped text bounding boxes by a totally different approach, following word separation or character grouping. A number of techniques are also developed which solely focus on text detection or word recognition. However, the tasks of word detection and recognition are highly correlated. Firstly, the feature information can be shared between them. In addition, these two tasks can complement each other: better detection improves recognition accuracy, and the recognition information can refine detection results vice versa.
以前的著作[28,2,12,11]通常将文本点分成一系列不同的子任务。 首先以较高的查全率执行文本检测以获得文本的候选区域。 然后,通过完全不同的方法,在单词分离或字符分组之后,将单词识别应用于裁剪后的文本边界框。 还开发了仅专注于文本检测或单词识别的许多技术。 但是,单词检测和识别的任务高度相关。 首先,特征信息可以在它们之间共享。 另外,这两个任务可以相互补充:更好的检测可以提高识别精度,而识别信息可以使检测结果更精确,反之亦然。
To this end, we propose an end-to-end trainable text spotter, which jointly detects and recognizes words in an image. An overview of the network architecture is presented in Figure 1. It consists of a number of convolutional layers, a region proposal network tailored specifically for text (refer to as Text Proposal Network, TPN), an Recurrent Neural Network (RNN) encoder for embedding proposals of varying sizes to fixed-length vectors, multi-layer perceptrons for detection and bounding box regression, and an attention-based RNN decoder for word recognition. Via this framework, both text bounding boxes and word labels are provided with a single forward evaluation of the network. We do not need to process the intermediate issues such as character grouping [35, 26] or text line separation [32], and thus avoid error accumulation. The main contributions are thus three-fold.
为此,我们提出了一种端到端的可训练文本检测器,该检测器可以共同检测和识别图像中的单词。 图1给出了网络体系结构的概述。它由许多卷积层,专门为文本定制的区域提议网络(称为文本提议网络,TPN),用于嵌入的递归神经网络(RNN)编码器组成。 针对固定长度矢量的大小变化的建议,用于检测和边界框回归的多层感知器以及用于单词识别的基于注意力的RNN解码器。 通过该框架,为文本边界框和单词标签都提供了对网络的单个正向评估。 我们不需要处理诸如字符分组[35,26]或文本行分隔[32]之类的中间问题,从而避免了错误累积。 因此,主要贡献是三方面。
(1) An end-to-end trainable DNN is designed to optimize the overall accuracy and share computations. The network integrates both text detection and word recognition. With the end-to-end training of both tasks, the learned features are more informative, which can promote the detection performance as well as the overall performance. The convolutional features are shared by both detection and recognition, which saves processing time. To our best knowledge, this is the first attempt to integrate text detection and recognition into a single end-to-end trainable network.
(1)端到端可训练DNN旨在优化整体准确性并共享计算。 该网络集成了文本检测和单词识别功能。 通过这两个任务的端到端训练,学习到的功能将提供更多信息,从而可以提高检测性能以及整体性能。 通过检测和识别可以共享卷积特征,从而节省了处理时间。 据我们所知,这是将文本检测和识别集成到单个端到端可训练网络中的首次尝试。
(2) We propose a new method for region feature extraction. In previous works [4, 21], Region-of-Interest (RoI) pooling layer converts regions of different sizes and aspect ratios into feature maps with a fixed size. Considering the significant diversity of aspect ratios in text bounding boxes, it is sub-optimal to fix the size after pooling. To accommodate the original aspect ratios and avoid distortion, RoI pooling is tailored to generate feature maps with varying lengths. An RNN encoder is then employed to encode feature maps of different lengths into the same size.
(2)提出了一种新的区域特征提取方法。 在以前的作品[4,21]中,兴趣区域(RoI)池化层将大小和纵横比不同的区域转换为具有固定大小的特征图。 考虑到文本边框中纵横比的显着差异,在合并后固定大小是次佳的选择。 为了适应原始的宽高比并避免失真,RoI池经过了量身定制以生成具有不同长度的特征图。 然后采用RNN编码器将不同长度的特征图编码为相同大小。
(3) A curriculum learning strategy is designed to train the system with gradually more complex training data. Starting from synthetic images with simple appearance and a large word lexicon, the system learns a character-level language model and finds a good initialization of appearance model. By employing real-world images with a small lexicon later, the system gradually learns how to handle complex appearance patterns. we conduct a set of experiments to explore the capabilities of different model structures. The best model outperforms state-of-the-art results on a number of standard text spotting benchmarks, including ICDAR2011, 2015.
(3)设计了课程学习策略,以使用逐渐复杂的训练数据来训练系统。 从具有简单外观和大词词典的合成图像开始,系统学习字符级语言模型并找到外观模型的良好初始化。 通过稍后使用带有小词典的实际图像,系统逐渐学习了如何处理复杂的外观图案。 我们进行了一组实验,以探索不同模型结构的功能。 最佳模型在包括ICDAR2011、2015年在内的许多标准文本发现基准上均胜过最新结果。
2. Related Work
Text spotting essentially includes two tasks: text detection and word recognition. In this section, we present a brief introduction to related works on text detection, word recognition, and text spotting systems that combine both. There are comprehensive surveys for text detection and recognition in [30, 36].
文本发现本质上包括两个任务:文本检测和单词识别。 在本节中,我们将简要介绍有关文本检测,单词识别和结合了两者的文本识别系统的相关工作。 在[30,36]中有关于文本检测和识别的综合调查。
2.1. Text Detection
Text detection aims to localize text in images and generate bounding boxes for words. Existing approaches can be roughly classified into three categories: character based, text-line based and word based methods. Character based methods firstly find characters in images, and then group them into words. They can be further divided into sliding window based [12, 29, 35, 26] and Connected Components (CC) based [9, 20, 3] methods. Sliding window based approaches use a trained classifier to detect characters across the image in a multi-scale sliding window fashion. CC based methods segment pixels with consistent region properties (i.e., color, stroke width, density, etc.) into characters. The detected characters are further grouped into text regions by morphological operations, CRF or other graph models.
文本检测旨在图像中定位文本,并为单词生成边界框。 现有方法可大致分为三类:基于字符的方法,基于文本行的方法和基于单词的方法。 基于字符的方法首先在图像中找到字符,然后将它们分组为单词。 它们可以进一步分为基于滑动窗口的[12、29、35、26]和基于连接组件(CC)的[9、20、3]方法。 基于滑动窗口的方法使用训练的分类器以多尺度滑动窗口方式检测图像中的字符。 基于CC的方法将具有一致区域属性(即颜色,笔触宽度,密度等)的像素分割为字符。 通过形态操作,CRF或CRF将检测到的字符进一步分为文本区域
其他图形模型。
Text-line based methods detect text lines firstly and then separate each line into multiple words. The motivation is that people usually distinguish text regions initially even if characters are not recognized. Based on the observation that a text region usually exhibits high self-similarity to itself and strong contrast to its local background, Zhang et al. [32] propose to extract text lines by exploiting symmetry property. Zhang et al. [33] localize text lines via salient maps that are calculated by fully convolutional networks. Post-processing techniques are also proposed in [33] to extract text lines in multiple orientations.
基于文本行的方法首先检测文本行,然后将每行分成多个单词。 这样做的动机是,即使不识别字符,人们通常最初也会区分文本区域。 基于观察,一个文本区域通常表现出很高的自相似性,并且与它的局部背景形成强烈的反差。 Zhang et al.[32]提出通过利用对称性来提取文本行 。Zhang et al. [33]通过完全卷积网络计算的显着地图来定位文本行。 [33]中还提出了后处理技术,以提取多个方向的文本行。
More recently, a number of approaches are proposed to detect words directly in the images using DNN based techniques, such as Faster R-CNN [21], YOLO [13], SSD [18]. By extending Faster R-CNN, Zhong et al. [34] design a text detector with a multiscale Region Proposal Network (RPN) and a multilevel RoI pooling layer. Tian et al. [27] develop a vertical anchor mechanism, and propose a Connectionist Text Proposal Network (CTPN) to accurately localize text lines in natural image. Gupta et al. [6] use a Fully-Convolutional Regression Network (FCRN) for efficient text detection and bounding box regression, motivated by YOLO. Similar to SSD, Liao et al. [17] propose “TextBoxes" by combining predictions from multiple feature maps with different resolutions, and achieve the best-reported performance on text detection with datasets in [14, 28].
最近,提出了许多基于DNN的技术方法来直接检测图像中的单词,例如Faster R-CNN [21],YOLO [13],SSD [18]。 通过扩展Faster R-CNN,Zhong等人 [34]设计了一个带有多尺度区域提议网络(RPN)和多层RoI池层的文本检测器。 田等 [27]开发了一个垂直锚机制,并提出了一个连接文本提议网络(CTPN)来准确地定位自然图像中的文本行。 Gupta等[6]在YOLO的推动下,使用全卷积回归网络(FCRN)进行有效的文本检测和包围盒回归。 与SSD类似,Liao等[17]通过结合来自具有不同分辨率的多个特征图的预测来提出“文本框”,并在[14,28]中使用数据集实现了文本检测的最佳报告性能。
2.2. Text Recognition
Traditional approaches to text recognition usually perform in a bottom-up fashion, which recognize individual characters firstly and then integrate them into words by means of beam search [2], dynamic program ming [12], etc. In contrast, Jaderberg et al. [10] consider word recognition as a multi-class classification problem, and categorize each word over a large dictionary (about 90K words, i.e., class labels) using a deep CNN. With the success of RNNs on handwriting recognition [5], He et al. [7] and Shi et al. [23] solve word recognition as a sequence labelling problem. RNNs are employed to generate sequential labels of arbitrary length without character segmentation, and Connectionist Temporal Classification (CTC) is adopted to decode the sequence. Lee and Osindero [16] and Shi et al. [24] propose to recognize text using an attentionbased sequence-to-sequence learning structure. In this manner, RNNs automatically learn the character- level language model presented in word strings from the training data. The soft-attention mechanism allows the model to selectively exploit local image features. These networks can be trained end-to-end with cropped word image patches as input. Moreover, Shi et al. [24] insert a Spatial Transformer Network (STN) to handle words with irregular shapes.
传统的文本识别方法通常以自下而上的方式执行,首先识别单个字符,然后通过波束搜索[2],动态程序编写[12]等将它们集成到单词中。相反,Jaderberg等人[10]将单词识别视为多类分类问题,并使用深层CNN在大型字典(约90K个单词,即类标签)上对每个单词进行分类。随着RNN在手写识别上的成功[5],He等[7]和Shi等[23]解决了单词识别作为序列标签的问题。 RNN用于生成任意长度的连续标签,而无需字符分段,并且采用连接器时间分类(CTC)来解码序列。 Lee和Osindero [16]和Shi等 [24]提出使用基于注意力的序列到序列学习结构来识别文本。通过这种方式,RNN会自动从训练数据中学习以字符串形式呈现的字符级语言模型。软注意力机制允许模型选择性地利用局部图像特征。可以使用裁剪后的单词图像块作为输入端对端地训练这些网络。而且,Shi等 [24]插入一个空间变压器网络(STN)来处理形状不规则的单词。
2.3. Text Spotting Systems
Text spotting needs to handle both text detection and word recognition. Wang et al. [28] take the locations and scores of detected characters as input and try to find an optimal configuration of a particular word in a given lexicon, based on a pictorial structures formulation. Neumann and Matas [20] use a CC based method for character detection. These characters are then agglomerated into text lines based on heuristic rules. Optimal sequences are finally found in each text line using dynamic programming, which are the recognized words. These recognition-based pipelines lack explicit word detection.
文本检测需要同时处理文本检测和单词识别。 Wang等 [28]以检测到的字符的位置和分数作为输入,并基于图形结构公式,尝试在给定的词典中找到特定单词的最佳配置。 Neumann和Matas [20]使用基于CC的字符检测方法。 然后,根据启发式规则将这些字符聚集成文本行。 最后,使用动态编程在每个文本行中找到最佳序列,这些序列是公认的单词。 这些基于识别的管道缺乏显式的单词检测。
Some text spotting systems firstly generate text proposals with a high recall and a low precision, and then refine them during recognition with a separate model. It is expected that a strong recognizer can reject false positives, especially when a lexicon is given. Jaderberg et al. [11] use an ensemble model to generate text proposals, and then adopt the word classifier in [10] for recognition. Gupta et al. [6] employ FCRN for text detection and the word classifier in [10] for recognition. Most recently, Liao et al. [17] combine “TextBoxes" and “CRNN" [23], which yield state-of-the-art performance on text spotting task with datasets in [14, 28].
一些文本识别系统首先生成具有较高召回率和较低精度的文本提议,然后在识别过程中使用单独的模型对其进行优化。 期望强大的识别器可以拒绝误报,尤其是在提供词典的情况下。 Jaderberg等 [11]使用集成模型生成文本建议,然后采用[10]中的单词分类器进行识别。 Gupta等 [6]使用FCRN进行文本检测,并使用[10]中的单词分类器进行识别。 最近,廖等人 [17]结合使用“TextBoxes“和“CRNN” [23],它们在[14,28]中的数据集上产生了文本查找任务的最新性能。
3. Model
Our goal is to design an end-to-end trainable network, which simultaneously detects and recognizes all words in images. Our model is motivated by recent progresses in DNN models such as Faster R-CNN [21] and sequence-to-sequence learning [24, 16], but we take the special characteristics of text into consideration. In this section, we present a detailed description of the whole system.
我们的目标是设计一个端到端的可训练网络,该网络可以同时检测和识别图像中的所有单词。 我们的模型是受DNN模型的最新进展启发的,例如Faster R-CNN [21]和序列到序列学习[24,16],但是我们考虑了文本的特殊特征。 在本节中,我们将对整个系统进行详细描述。
Notation
All bold capital letters represent matrices and all bold lower-case letters denote column vectors. [a; b] concatenates the vectors a and b vertically, while [a; b] stacks a and b horizontally (column wise). In the following, the bias terms in neural networks are omitted.
表示法
所有粗体大写字母代表矩阵,所有粗体小写字母代表列向量。 [ a ; b ] [a; b] [a;b]将向量a和b垂直连接(行增加),而 [ a , b ] [a, b] [a,b]水平堆叠a和b(逐列)(列增加)。 在下文中,省略了神经网络中的偏置项。
3.1. Overall Architecture
The whole system architecture is illustrated in Figure 1. Firstly, the input image is fed into a convolutional neural network that is modified from VGG-16 net [25]. VGG-16 consists of 13 layers of 3 × 3 convolutions followed by Rectified Linear Unit (ReLU), 5 layers of 2×2 max- pooling, and Fully-Connected (FC) layers. Here we remove FC layers. As long as text in images can be relatively small, we only keep the 1st, 2nd and 4th layers of max-pooling, so that the downsampling ratio is increased from 1/32 to 1/8.
整个系统架构如图1所示。首先,输入图像被馈送到从VGG-16 net修改的卷积神经网络中[25]。 VGG-16由13层3×3卷积,紧随其后的是整流线性单元(ReLU),5层2×2最大池和全连接(FC)层组成。 在这里,我们删除FC层。 只要图像中的文本可以比较小,我们就只保留第一,第二和第四层的最大池,因此下采样率将从1/32增加到1/8。
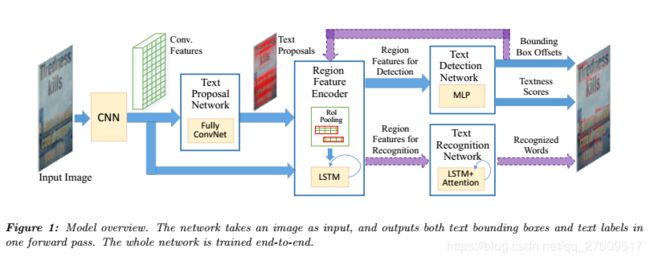
Given the computed convolutional features, TPN provides a list of text region proposals (bounding boxes). Then, Region Feature Encoder (RFE) converts the convolutional features of proposals into fixed-length representations. These representations are further fed into Text Detection Network (TDN) to calculate their textness scores and bounding box offsets. Next, RFE is applied again to compute fixed-length representations of text bounding boxes provided by TDN (see purple paths in Figure 1). Finally, Text Recognition Network (TRN) recognizes words in the detected bounding boxes based on their representations.
给定计算出的卷积特征,TPN提供了一个文本区域提议列表(边界框)。 然后,区域特征编码器(RFE)将投标的卷积特征转换为固定长度的表示形式。 这些表示形式进一步输入到文本检测网络(TDN)中,以计算其文本性得分和边界框偏移。 接下来,再次应用RFE来计算TDN提供的文本边界框的固定长度表示形式(请参见图1中的紫色路径)。 最后,文本识别网络(TRN)根据检测到的边界框中的单词识别单词。
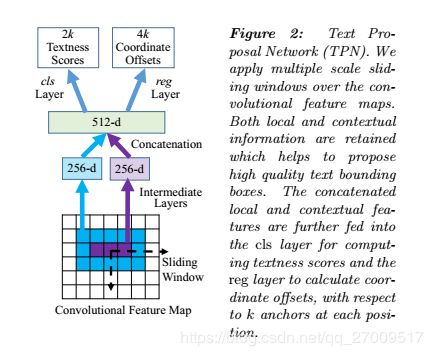
3.2. Text Proposal Network
Text proposal network (TPN) is inspired from RPN [21, 34], which can be regarded as a fully convolutional network. As presented in Figures 2, it takes convolutional features as input, and outputs a set of bounding boxes accompanied with “textness” scores and coordinate offsets which indicate scale-invariant translations and log-space height/width shifts relative to pre-defined anchors, as in [21].
文本提议网络(TPN)受到RPN [21,34]的启发,该网络可被视为完全卷积的网络。 如图2所示,它以卷积特征为输入,并输出一组带有“文本”分数和坐标偏移的边界框,这些分数和刻度指示相对于预定义锚的标度不变的平移和对数空间高度/宽度的偏移, 如[21]。
Considering that word bounding boxes usually have larger aspect ratios (W=H) and varying scales, we designed k = 24 anchors with 4 scales (with box areas of 1 6 2 , 3 2 2 , 6 4 2 , 8 0 2 16^2, 32^2, 64^2, 80^2 162,322,642,802) and 6 aspect ratios (1 : 1, 2 : 1, 3 : 1, 5 : 1, 7 : 1, 10 : 1).
考虑到单词边界框通常具有更大的长宽比(W = H)和不同的缩放比例,我们设计了k = 24个具有4个缩放比例的锚点(框面积为 1 6 2 、 3 2 2 、 6 4 2 、 8 0 2 16 ^ 2、32 ^ 2、64 ^ 2、80 ^ 2 162、322、642、802) 和6个宽高比(1:1、2:1、3:1、5:1、7:1、10:1)。
Inspired by [34], we apply two 256-d rectangle convolutional filters of different sizes (W = 5; H = 3 and W = 3; H = 1) on the feature maps to extract both local and contextual information. The rectangle filters lead to wider receptive fields, which is more suitable for word bounding boxes with large aspect ratios. The resulting features are further concatenated to 512-d vectors and fed into two sibling layers for text/non-text classification and bounding box regression.
受[34]的启发,我们在特征图上应用了两个大小不同的256维矩形卷积滤波器(W = 5; H = 3; W = 3; H = 1),以提取局部信息和上下文信息。 矩形滤镜可产生较宽的接收场,这更适合于具有大长宽比的单词边界框。 生成的特征进一步连接到512-d向量,并输入两个同级图层中,以进行文本/非文本分类和边界框回归。
3.3. Region Feature Encoder
To process RoIs of different scales and aspect ratios in a unified way, most existing works re-sample regions into fixed-size feature maps via pooling [4]. However, for text, this approach may lead to significant distortion due to the large variation of word lengths. For example, it may be unreasonable to encode short words like “Dr" and long words like “congratulations" into feature maps of the same size. In this work, we propose to re-sample regions according to their respective aspect ratios, and then use RNNs to encode the resulting feature maps of different lengths into fixed length vectors. The whole region feature encoding process is illustrated in Figure 3.
为了统一处理不同比例和长宽比的RoI,大多数现有作品通过合并将区域重新采样为固定大小的特征图[4]。 但是,对于文本来说,由于单词长度的较大变化,这种方法可能会导致严重的失真。 例如,将像“Dr”这样的短单词和像“祝贺”这样的长单词编码成相同大小的特征图可能是不合理的。 在这项工作中,我们建议根据区域的纵横比对区域进行重新采样,然后使用RNN将所得的不同长度的特征图编码为固定长度的向量。 整个区域特征编码过程如图3所示。
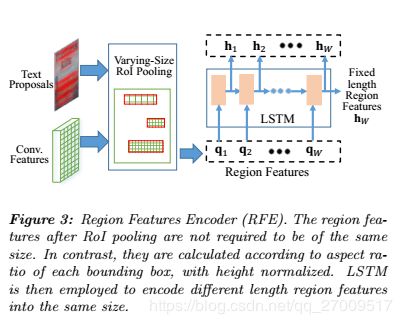
For an RoI of size h × w h×w h×w, we perform spatial maxpooling with a resulting size of
对于大小为 h × w h×w h×w的投资回报率,我们执行空间最大池化,结果大小为
H × m i n ( W m a x , 2 H w / h ) H×min(W_{max}, 2Hw/h) H×min(Wmax,2Hw/h)(1)
where the expected height H H H is fixed and the width is adjusted to keep the aspect ratio as 2 w / h 2w/h 2w/h (twice the original aspect ratio) unless it exceeds the maximum length W m a x W_{max} Wmax. Note that here we employ a pooling window with an aspect ratio of 1 : 2, which benefits the recognition of narrow shaped characters, like ‘i’, ‘l’, etc., as stated in [23].
除非预期高度 H H H超过最大长度 W m a x W_ {max} Wmax,否则预期高度 H H H是固定的,宽度已调整为将纵横比保持为 2 w / h 2w/h 2w/h(原始纵横比的两倍)。 请注意,这里我们使用的宽高比为1:2的合并窗口,这有利于识别狭窄形状的字符,如[23]中所述的“ i”,“ l”等。
Next, the resampled feature maps are considered as a sequence and fed into RNNs for encoding. Here we use Long-Short Term Memory (LSTM) [8] instead of vanilla RNN to overcome the shortcoming of gradient vanishing or exploding. The feature maps after the above varying-size RoI pooling are denoted as Q ∈ R C × H × W Q \in R^{C×H×W} Q∈RC×H×W , where W = m i n ( W m a x ; 2 H w = h ) W = min(W_{max}; 2Hw=h) W=min(Wmax;2Hw=h) is the number of columns and C C C is the channel size. We flatten the features in each column, and obtain a sequence q 1 , . . . , q W ∈ R C × H q_1,...,q_W \in R^{C×H} q1,...,qW∈RC×H which are fed into LSTMs one by one. Each time LSTM units receive one column of feature q t q_t qt, and update their hidden state h t h_t ht by a non-linear function: h t = f ( q t ; h t − 1 ) h_t = f(q_t; h_{t−1}) ht=f(qt;ht−1). In this recurrent fashion, the final hidden state h W h_W hW (with size R = 1024 R = 1024 R=1024) captures the holistic information of Q Q Q and is used as a RoI representation with fixed dimension.
接下来,将重新采样的特征图视为一个序列,并馈入RNN进行编码。 在这里,我们使用长期短期记忆(LSTM)[8]代替普通RNN来克服梯度消失或爆炸的缺点。 在上述大小可变的RoI池之后的特征图表示为 Q ∈ R C × H × W Q \in R ^ {C×H×W} Q∈RC×H×W,其中 W = m i n ( W m a x ; 2 H w = h W = min(W_{max}; 2Hw = h W=min(Wmax;2Hw=h是列数, C C C是通道大小。 我们将每列中的特征展平,并获得序列 q 1 , . . . , q W ∈ R c × H q_1,...,q_W \in R^{c×H} q1,...,qW∈Rc×H ,它们被逐一馈入LSTM。 每次LSTM单元收到一列特征 q t q_t qt,并通过非线性函数 h t = f ( q t ; h t − 1 h_t = f(q_t; h_ {t-1} ht=f(qt;ht−1更新其隐藏状态 h t h_t ht。 以这种循环方式,最终的隐藏状态 h W h_W hW(大小为 R = 1024 R = 1024 R=1024)捕获 Q Q Q的整体信息,并用作具有固定尺寸的RoI表示。
3.4. Text Detection and Recognition
Text Detection Network (TDN)
Text Detection Network (TDN) aims to judge whether the proposed RoIs are text or not and refine the coordinates of bounding boxes once again, based on the extracted region features hW . Two fully-connected layers with 2048 neurons are applied on h W h_W hW , followedby two parallel layers for classification and bounding box regression respectively.
文本检测网络(TDN)旨在基于提取的区域特征hW来判断建议的RoI是否为文本,并再次完善边界框的坐标。 在 h W h_W hW上应用两个具有2048个神经元的全连接层,然后分别使用两个并行层进行分类和边界框回归。
The classification and regression layers used in TDN are similar to those used in TPN. Note that the whole system refines the coordinates of text bounding boxes twice: once in TPN and then in TDN. Although RFE is employed twice to calculate features for proposals produced by TPN and later the detected bounding boxes provided by TDN, the convolutional features only need to be computed once.
TDN中使用的分类和回归层与TPN中使用的相似。 请注意,整个系统两次优化了文本边界框的坐标:一次在TPN中,然后在TDN中。 尽管两次使用RFE来计算TPN生成的提案的特征,然后再计算TDN提供的检测到的边界框,但是卷积特征只需要计算一次。
Text Recognition Network (TRN)
Text Recognition Network (TRN) aims to predict the text in the detected bounding boxes based on the extracted region features. As shown in Figure 4, we adopt LSTMs with attention mechanism [19, 24] to decode the sequential features into words.
文本识别网络(TRN)旨在根据提取的区域特征来预测检测到的边界框中的文本。 如图4所示,我们采用具有注意力机制的LSTM [19,24]将序列特征解码为单词。
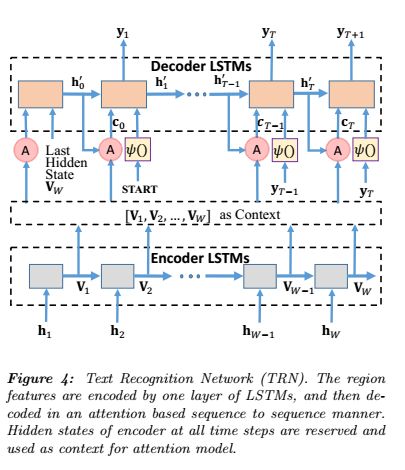
Firstly, hidden states at all steps h 1 , . . . , h W h_1,...,h_W h1,...,hW from RFE are fed into an additional layer of LSTM encoder with 1024 units. We record the hidden state at each time step and form a sequence of V = [ v 1 , . . . , v W ] ∈ R R × W V = [v_1,...,v_W ] \in R^{R×W} V=[v1,...,vW]∈RR×W . It includes local information at each time step and works as the context for the attention model.
首先,来自RFE的所有步骤 h 1 , . . . , h W h_1,...,h_W h1,...,hW的隐藏状态被馈送到具有1024个单位的LSTM编码器的附加层。 我们记录每个时间步的隐藏状态,并在中形成一个序列 V = [ v 1 , . . . , v W ] ∈ R R × W V = [v_1,...,v_W] \in R ^ {R×W} V=[v1,...,vW]∈RR×W。 它包括每个时间步骤的本地信息,并作为关注模型的上下文。
As for decoder LSTMs, the ground-truth word label is adopted as input during training. It can be regarded as a sequence of tokens s = { s 0 , s 1 , . . . , s T + 1 } s = \{s_0,s_1,...,s_{T +1}\} s={s0,s1,...,sT+1} where s 0 s_0 s0 and s T + 1 s_{T +1} sT+1 represent the special tokens START and END respectively. We feed decoder LSTMs with T + 2 T + 2 T+2 vectors: x 0 , x 1 , . . . , x T + 1 x_0, x_1, ... , x_{T +1} x0,x1,...,xT+1, where x 0 = [ v W ; A t t e n ( V , 0 ) ] x_0 = [v_W ; Atten(V, 0)] x0=[vW;Atten(V,0)] is the concatenation of the encoder’s last hidden state v W v_W vW and the attention output with guidance equals to zero; and x i = [ ψ ( s i − 1 ) ; A t t e n ( V , h i − 1 ′ ) ] x_i = [ \psi(s_{i−1}); Atten(V,h'_{ i−1})] xi=[ψ(si−1);Atten(V,hi−1′)], for i = 1 , . . . , T + 1 i = 1,...,T + 1 i=1,...,T+1, is made up of the embedding ψ ( ) \psi() ψ() of the ( i − 1 ) − t h (i − 1)-th (i−1)−th token s i − 1 s_{i−1} si−1 and the attention output guided by the hidden state of decoder LSTMs in the previous time-step h i − 1 ′ h'_{ i−1} hi−1′. The embedding function ψ ( ) \psi() ψ() is defined as a linear layer followed by a tanh non-linearity.
对于解码器LSTM,在训练过程中将真实的单词标签用作输入,可以将其视为令牌序列 s = { s 0 , s 1 , . . . , s T + 1 } s = \{s_0, s_1,...,s_ {T +1} \} s={s0,s1,...,sT+1},其中 s 0 s_0 s0和 s T + 1 s_ {T +1} sT+1分别代表特殊令牌START和END。 我们用 T + 2 T + 2 T+2个向量: x 0 , x 1 , . . . , x T + 1 x_0,x_1,...,x_ {T +1} x0,x1,...,xT+1向解码器LSTM馈送,其中 x 0 = [ v W ; A t t e n ( V , 0 ) ] x_0 = [v_W; Atten(V,0)] x0=[vW;Atten(V,0)]是编码器的最后一个隐藏状态 v W v_W vW和引导输出的注意力为零的的串联,即 x i = [ ψ ( s i − 1 ) ; A t t e n ( V , h i − 1 ′ ) ] x_i = [\psi(s_ {i-1});Atten(V,h'_ {i−1})] xi=[ψ(si−1);Atten(V,hi−1′)]; 对于 i = 1 , . . . . T + 1 i = 1,....T + 1 i=1,....T+1由第 i − 1 i − 1 i−1的嵌入 ψ ( ) \psi() ψ()的令牌 s i − 1 s_ {i-1} si−1和在先前时间步长 h i − 1 ′ h'_ {i-1} hi−1′中由解码器LSTM的隐藏状态引导的注意力输出组成。 嵌入函数 ψ ( ) \psi() ψ()被定义为线性层,其后是tanh非线性。
The attention function c i = A t t e n ( V , h i ′ ) c_i = Atten(V, h'_i) ci=Atten(V,hi′) is defined as follows:
注意函数 c i = A t t e n ( V , h i ′ ) c_i = Atten(V,h'_i ) ci=Atten(V,hi′)定义如下:
{ g i = t a n h ( W v v j + W h h i ′ ) , j = 1 , . . . , W α = s o f t m a x ( w g ⋅ [ g 1 , g 2 , . . . , g w ] ) , c i = ∑ j = 1 W α j v j , (2) \left \{ \begin{array}{c} g_i=tanh(W_{v}v_j+W_hh'_i) ,j=1,...,W \\ \alpha=softmax(w_g \cdot [g_1, g_2, ..., g_w]), \\ c_i=\sum^W_{j=1}\alpha_jv_j, \end{array} \right. \tag{2} ⎩⎨⎧gi=tanh(Wvvj+Whhi′),j=1,...,Wα=softmax(wg⋅[g1,g2,...,gw]),ci=∑j=1Wαjvj,(2)
where V = [ v 1 , . . . , v W ] V = [v_1,...,v_W ] V=[v1,...,vW] is the variable-length sequence of features to be attended, h i ′ h' _i hi′ is the guidance vector, W v W_v Wv and W h W_h Wh are linear embedding weights to be learned, α \alpha α is the attention weights of size W W W , and c i c_i ci is a weighted sum of input features.
其中 V = [ v 1 , . . . , v W ] V = [v_1,...,v_W] V=[v1,...,vW]是要处理的特征的可变长度序列, h i ′ h'_i hi′是引导向量, W v W_v Wv和 W h W_h Wh是要学习的线性嵌入权重 , α \alpha α是大小 W W W的注意力权重,而 c i c_i ci是输入要素的加权和。
At each time-step t = 0 ; 1 , . . . , T + 1 t = 0; 1,...,T + 1 t=0;1,...,T+1, the decoder LSTMs compute their hidden state h t ′ h'_ t ht′ and output vector y t y_t yt as follows:
在每个时间步长 t = 0 ; 1 , . . . , T + 1 t = 0; 1,...,T + 1 t=0;1,...,T+1,解码器LSTM计算其隐藏状态 h t ′ h'_ t ht′并输出向量 y t y_t yt如下:
{ h t ′ = f ( x t , h t − 1 ′ ) , y t = φ ( h t ′ ) = s o f t m a x ( W o h t ′ ) (3) \left \{ \begin{array}{c} h'_t=f(x_t,h'_{t-1}), \\ y_t = \varphi(h'_t)=softmax(W_oh'_t) \end{array} \right. \tag{3} {ht′=f(xt,ht−1′),yt=φ(ht′)=softmax(Woht′)(3)
where the LSTM [8] is used for the recurrence formula f ( ) f() f(), and W o W_o Wo linearly transforms hidden states to the output space of size 38, including 26 case-insensitive characters, 10 digits, a token representing all punctuations like “!” and “?”, and a special END token. At test time, the token with the highest probability in previous output y t y_t yt is selected as the input token at step t + 1 t+1 t+1, instead of the ground-truth tokens s 1 , . . . , s T s_1,...,s_T s1,...,sT . The process is started with the START token, and repeated until we get the special END token.
其中LSTM [8]用于递归公式 f ( ) f() f(), W o W_o Wo将隐藏状态线性转换为大小为38的输出空间,包括26个不区分大小写的字符,10位数字,一个表示所有标点符号的令牌,例如 “!“和”?”,以及特殊的END令牌。 在测试时,在步骤 t + 1 t + 1 t+1中选择先前输出 y t y_t yt中概率最高的令牌作为输入令牌,而不是地面令牌 s 1 , . . . , s T s_1,...,s_T s1,...,sT。 该过程从START令牌开始,然后重复进行,直到获得特殊的END令牌。
3.5. Loss Functions and Training
Loss Functions
Loss Functions As we demonstrate above, our system takes as input an image, word bounding boxes and their labels during training. Both TPN and TDN employ the binary logistic loss L c l s L_{cls} Lcls for classification, and smooth L 1 L_1 L1 loss L r e g L_{reg} Lreg [21] for regression. So the loss for training TPN is
损失函数如上所述,我们的系统在训练过程中将图像,单词边界框及其标签作为输入。 TPN和TDN均使用二进制逻辑损失 L c l s L_ {cls} Lcls进行分类,并平滑 L 1 L_1 L1损失 L r e g L_ {reg} Lreg [21]进行回归。 所以训练TPN的损失是
L T P N = 1 N ∑ i = 1 N L c l s ( p i , p i ∗ ) + 1 N + ∑ i = 1 N + L r e g ( d i , d i ∗ ) , ( 4 ) L_{TPN}=\frac{1}{N}\sum^{N}_{i=1}L_{cls}(p_i, p^*_i)+\frac{1}{N_+}\sum^{N_+}_{i=1}L_{reg}(d_i, d^*_i), (4) LTPN=N1∑i=1NLcls(pi,pi∗)+N+1∑i=1N+Lreg(di,di∗),(4)
where N N N is the number of randomly sampled anchors in a mini-batch and N + N_+ N+ is the number of positive anchors in this batch (the range of positive anchor indices is from 1 to N + N_+ N+). The mini-batch sampling and training process of TPN are similar to that used in [21]. An anchor is considered as positive if its Intersectionover-Union (IoU) ratio with a ground-truth is greater than 0.7 and considered as negative if its IoU with any ground-truth is smaller than 0:3. In this paper, N N N is set to 256 and N + N_+ N+ is at most 128. p i p_i pi denotes the predicted probability of anchor i i i being text and p i p_i pi is the corresponding ground-truth label (1 for text, 0 for non-text). d i d_i di is the predicted coordinate offsets ( d x i , d y i , d w i , d h i dx_i, dy_i, dw_i, dh_i dxi,dyi,dwi,dhi) for anchor i i i, and d i ∗ d^*_i di∗ is the associated offsets for anchor i i i relative to the ground-truth. Bounding box regression is only for positive anchors, as there is no ground- truth bounding box matched with negative ones.
其中 N N N是微型批次中随机采样的锚点数量, N + N _ + N+是该批次中的正锚点数量(正锚点索引的范围是1到 N + N _ + N+)。 TPN的小批量采样和训练过程与[21]中使用的相似。 如果锚点的与地面真实性的交点(IoU)比率大于0.7,则认为锚定为正;如果锚点与任何地面真实性的IoU小于0:3,则认为锚定为负。 在本文中, N N N设置为256, N + N _ + N+最多为128。 p i p_i pi表示锚点 i i i是文本的预测概率, p i p_i pi是相应的地面标签(文本为1,文本为0 对于非文本)。 d i d_i di是锚点 i i i的预测坐标偏移量( d x i , d y i , d w i , d h i dx_i,dy_i,dw_i,dh_i dxi,dyi,dwi,dhi),而 d i ∗ d ^ * _ i di∗是锚点 i i i相对于地面真相的相关偏移量。 边界框回归仅适用于正锚,因为不存在与负锚匹配的底线边界框。
For the final outputs of the whole system, we apply a multi-task loss for both detection and recognition:
对于整个系统的最终输出,我们将多任务损失应用于检测和识别:
L D R N = 1 N ^ ∑ i = 1 N ^ L c l s ( p ^ i , p ^ i ∗ ) + 1 N ^ + ∑ i = 1 N ^ + L r e g ( d ^ i , d ^ i ∗ ) + 1 N ^ + ∑ i = 1 N ^ + L r e c ( Y ( i ) , s ( i ) ) L_{DRN}=\frac{1}{\hat N}\sum^{\hat N}_{i=1}L_{cls}(\hat p_i, \hat p^*_i)+\frac{1}{\hat N_+}\sum^{\hat N_+}_{i=1}L_{reg}(\hat d_i, \hat d^*_i)+\frac{1}{\hat N_+}\sum^{\hat N_+}_{i=1}L_{rec}(Y^{(i)},s^{(i)}) LDRN=N^1∑i=1N^Lcls(p^i,p^i∗)+N^+1∑i=1N^+Lreg(d^i,d^i∗)+N^+1∑i=1N^+Lrec(Y(i),s(i)) (5)
where N ^ = 128 \hat N = 128 N^=128 is the number of text proposals sampled from the output of TPN, and N ^ + ≤ 64 \hat N_+ ≤ 64 N^+≤64 is the number of positive ones. The thresholds for positive and negative anchors are set to 0:6 and 0:4 respectively, which are less strict than those used for training TPN. In order to mine hard negatives, we first apply TDN on 1000 randomly sampled negatives and select those with higher textness scores. p ^ i \hat p_i p^i and d ^ i \hat d_i d^i are the outputs of TDN. s ( i ) s^{(i)} s(i) is the ground-truth tokens for sample i i i and Y ( i ) = { y 0 ( i ) , y 1 ( i ) , . . . , y T ( i + 1 ) } Y^{(i)} = \{y_0^{(i)}, y_1^{(i)},...,y_T^{(i+1 )}\} Y(i)={y0(i),y1(i),...,yT(i+1)} g is the corresponding output sequence of decoder LSTMs. L r e c ( Y , s ) = − ∑ t = 1 T + 1 l o g y t ( s t ) L_{rec}(Y,s) = −\sum^{T+1}_{t=1}log y_t(s_t) Lrec(Y,s)=−∑t=1T+1logyt(st) denotes the cross entropy loss on y 1 , . . . , y T + 1 y_1, ..., y_{T +1} y1,...,yT+1, where y t ( s t ) y_t(s_t) yt(st) represents the predicted probability of the output being s t s_t st at timestep t t t and the loss on y 0 y_0 y0 is ignored.
其中 N ^ = 128 \hat N = 128 N^=128是从TPN的输出中采样的文本提议的数量,而 N ^ + ≤ 64 \hat N_ +≤64 N^+≤64是肯定的提议的数量。 正锚和负锚的阈值分别设置为0:6和0:4,这比用于训练TPN的阈值严格。 为了挖掘硬底片,我们首先对1000个随机采样的底片应用TDN,选择那些具有较高的文本得分。 p ^ i \hat p_i p^i和 d ^ i \hat d_i d^i是TDN的输出。 s ( i ) s ^ {(i)} s(i)是样本 i i i和 Y ( i ) = { y 0 ( i ) , y 1 ( i ) , . … , y T ( i + 1 ) } Y ^ {(i)} = \{y_0 ^ {(i)},y_1 ^ {(i)} ,.…,y_T ^ {(i + 1)} \} Y(i)={y0(i),y1(i),.…,yT(i+1)}的真实令牌。 g是解码器LSTM的相应输出序列。 L r e c ( Y , s ) = − s u m t = 1 T + 1 l o g y t ( s t ) L_ {rec}(Y,s)= − \ sum ^ {T + 1} _ {t = 1} log y_t(s_t) Lrec(Y,s)=− sumt=1T+1logyt(st)表示 y 1 , . . . , y T + 1 y_1,...,y_ {T +1 } y1,...,yT+1上的交叉熵损失,其中 y t ( s t ) y_t(s_t) yt(st)表示在时间步 t t t处输出为 s t s_t st的预测概率,并且忽略 y 0 y_0 y0的损失。
Following [21], we use an approximate joint training process to minimize the above two losses together (ADAM [15] is adopted), ignoring the derivatives with respect to the proposed boxes’ coordinates.
按照[21],我们使用近似的联合训练过程将上述两个损失最小化(采用了ADAM [15]),而忽略了相对于所建议的盒子坐标的导数。
Data Augmentation
We sample one image per iteration in the training phase. Training images are resized to shorter side of 600 pixels and longer side of at most 1200 pixels. Data augmentation is also implemented to improve the robustness of our model, which includes:
- randomly rescaling the width of the image by ratio 1 or 0.8 without changing its height, so that the bounding boxes have more variable aspect ratios;
- randomly cropping a subimage which includes all text in the original image, padding with 100 pixels on each side, and resizing to 600 pixels on shorter side.
我们在训练阶段每次迭代采样一张图像。 将训练图像的尺寸调整为600像素的较短边和最多1200像素的较长边。 还实施了数据增强以提高模型的健壮性,其中包括:
1)在不更改图像高度的情况下,按比例1或0.8随机缩放图像的宽度,以使边框具有更多可变的宽高比;
2)随机裁剪包含原始图像中所有文本的子图像,在每侧填充100像素,并在较短的一侧调整为600像素。
Curriculum Learning
In order to improve generalization and accelerate the convergence speed, we design a curriculum learning [1] paradigm to train the model from gradually more complex data.
为了提高概括性并加快收敛速度,我们设计了一种课程学习范式[1],以从逐渐更复杂的数据中训练模型。
- We generate 48k images containing words in the “Generic” lexicon [11] of size 90k by using the synthetic engine proposed in [6]. The words are randomly placed on simple pure colour backgrounds (10 words per image on average). We lock TRN initially, and train the rest parts of our proposed model on these synthetic images in the first 30k iterations, with convolutional layers initialized from the trained VGG-16 model and other parameters randomly initialized according to Gaussian distribution. For efficiency, the first four convolutional layers are fixed during the entire training process. The learning rate is set to 10−5 for parameters in the rest of convolutional layers and 10−3 for randomly initialized parameters.
1)通过使用[6]中提出的合成引擎,我们生成了大小为90k的“通用”词典[11]中包含单词的48k图像。 这些单词被随机放置在简单的纯彩色背景上(每个图像平均10个单词)。 我们最初锁定TRN,然后在前30k迭代中在这些合成图像上训练我们提出的模型的其余部分,并从训练后的VGG-16模型初始化卷积层,并根据高斯分布随机初始化其他参数。 为了提高效率,在整个训练过程中,前四个卷积层是固定的。 对于其余卷积层中的参数,学习率设置为10-5,对于随机初始化的参数,学习率设置为10-3。
- In the next 30k iterations, TRN is added and trained with a learning rate of 10−3, together with other parts in which the learning rate for randomly initialized parameters is halved to 5 × 10−4. We still use the 48k synthetic images as they contain a comprehensive 90k word vocabulary. With this synthetic dataset, a character-level language model can be learned by TRN.
2)在接下来的30k迭代中,将添加TRN并以10-3的学习速率对其进行训练,以及将随机初始化参数的学习速率减半为5×10-4的其他部分。 我们仍然使用48k合成图像,因为它们包含全面的90k单词词汇。 使用此综合数据集,TRN可以学习字符级语言模型。
- In the next 50k iterations, the training examples are randomly selected from the “Synth800k” [6] dataset, which consists of 800k images with averagely 10 synthetic words placed on each real scene background. The learning rate for convolutional layers remains at 10−5, but that for others is halved to 10−4.
3)在接下来的50k迭代中,从“ Synth800k” [6]数据集中随机选择训练示例,该数据集由800k图像组成,每个真实场景背景上平均放置10个合成词。 卷积层的学习速率保持在10-5,而其他卷积层的学习速率减半到10-4。
- Totally 2044 real-world training images from ICDAR2015 [14], SVT [28] and AddF2k [34] datasets are employed for another 20k iterations. In this stage, all the convolutional layers are fixed and the learning rate for others is further halved to 10−5. These real images contain much less words than synthetic ones, but their appearance patterns are much more complex.
4)来自ICDAR2015 [14],SVT [28]和AddF2k [34]数据集的总共2044个现实训练图像用于另外20k迭代。 在这个阶段,所有的卷积层都是固定的,其他卷积层的学习率进一步减半至10-5。 这些真实图像包含的单词少于合成图像,但是它们的外观模式要复杂得多。
4. Experiments
In this section, we perform experiments to verify the effectiveness of the proposed method.All experiments are implemented on an NVIDIA Tesla M40 GPU with 24GB memory. We rescale the input image into multiple sizes during test phase in order to cover the large range of bounding box scales, and sample 300 proposals with the highest textness scores produced by TPN. The detected bounding boxes are then merged via NMS according to their textness scores and fed into TRN for recognition.
在本节中,我们将进行实验以验证该方法的有效性。所有实验均在具有24GB内存的NVIDIA Tesla M40 GPU上进行。 在测试阶段,我们将输入图像重新缩放为多种大小,以覆盖大范围的包围盒比例,并采样TPN产生的具有最高文本得分的300个建议。 然后,根据NMS的文本得分将检测到的边界框合并,并输入到TRN中进行识别。
Criteria
We follow the evaluation protocols used in ICDAR2015 Robust Reading Competition [14]: a bounding box is considered as correct if its IoU ratio with any ground-truth is greater than 0.5 and the recognized word also matches, ignoring the case. The words that contain alphanumeric characters and no longer than three characters are ignored. There are two evaluation protocols used in the task of scene text spotting: “End-to-End” and \Word Spotting". “End-to-End” protocol requires that all words in the image are to be recognized, with independence of whether the string exists or not in the provided contextualised lexicon, while “Word Spotting” on the other hand, only looks at the words that actually exist in the lexicon provided, ignoring all the rest that do not appear in the lexicon.
我们遵循ICDAR2015健壮阅读比赛[14]中使用的评估协议:如果包围盒的IoU比率与任何地面真实性之比大于0.5,并且识别的单词也匹配,则忽略大小写,则认为该包围盒是正确的。 包含字母数字字符且不超过三个字符的单词将被忽略。 在场景文本发现任务中使用两种评估协议:"End-to-End“和 "Word Spotting”。 "End-to-End“协议要求识别图像中的所有单词,而与所提供的上下文词典中是否存在字符串无关,而另一方面,” Word Spotting“仅查看实际中的单词 存在于提供的词典中,而忽略了所有未出现在词典中的其余部分。
Datasets
The commonly used datasets for scene text spotting include ICDAR2015 [14], ICDAR2011 [22] and Street View Text (SVT) [28]. We use the dataset for the task of “Focused Scene Text” in ICDAR2015 Robust Reading Competition, which consists of 229 images for training and 233 images for test. In addition, it provides 3 specific lists of words as lexicons for reference in the test phase, i.e., “Strong”, “Weak” and “Generic”. “Strong” lexicon provides 100 words per-image including all words appeared in the image. “Weak” lexicon contains all words appeared in the entire dataset, and “Generic” lexicon is a 90k word vocabulary proposed by [11]. ICDAR2011 does not provide any lexicon. So we only use the 90k vocabulary as context. SVT dataset consists of 100 images for training and 249 images for test. These images are harvested from Google Street View and often have a low resolution. It also provides a “Strong” lexicon with 50 words per-image. As there are unlabelled words in SVT, we only evaluate the “Word-Spotting” performance on this dataset.
用于场景文本发现的常用数据集包括ICDAR2015 [14],ICDAR2011 [22]和街景文本(SVT)[28]。我们将数据集用于ICDAR2015健壮阅读比赛中的“聚焦场景文本”任务,该数据集包含229张训练图像和233张测试图像。此外,它提供了3个特定的单词列表作为词典,供测试阶段参考,即“强”,“弱”和“通用”。 “强”词典每个图像提供100个单词,包括图像中出现的所有单词。 “弱”词典包含出现在整个数据集中的所有单词,“通用”词典是[11]提出的90k单词词汇。 ICDAR2011不提供任何词典。因此,我们仅将90k词汇用作上下文。 SVT数据集包括用于训练的100张图像和用于测试的249张图像。这些图像是从Google街景中获取的,通常分辨率较低。它还提供每个图像50个单词的“强大”词典。由于SVT中有未标记的单词,因此我们仅评估此数据集的“单词发现”性能。
4.1. Evaluation under Different Model Settings
In order to show the effectiveness of our proposed varying-size RoI pooling (see Section 3.3) and the attention mechanism (see Section 3.4), we examine the performance of our model with different settings in this subsection. With the fixed RoI pooling size of 4 × 20, we denote the models with and without the attention mechanism as “Ours Atten+Fixed” and “Ours NoAtten+Fixed” respectively. The model with both attention and varying-size RoI pooling is denoted as “Ours Atten+Vary”, in which the size of feature maps after pooling is calculated by Equ. (1) with H = 4 H = 4 H=4 and W m a x = 35 W_{max} = 35 Wmax=35.
为了显示我们提出的可变大小RoI池(请参阅第3.3节)和注意机制(请参见第3.4节)的有效性,我们在本小节中检查了具有不同设置的模型的性能。 在固定的RoI池大小为4×20的情况下,我们将带有注意机制和不带有注意机制的模型分别表示为“ Ours Atten + Fixed”和“ Ours NoAtten + Fixed”。 具有注意力和可变大小的RoI池的模型表示为“我们的注意力+变化”,其中池化后特征图的大小由Equ(1)计算。其中 H = 4 H = 4 H=4和 W m a x = 35 W_ {max} = 35 Wmax=35。
Although the last hidden state of LSTMs encodes the holistic information of RoI image patch, it still lacks details. Particularly for a long word image patch, the initial information may be lost during the recurrent encoding process. Thus, we keep the hidden states of encoder LSTMs at each time step as context. The attention model can choose the corresponding local features for each character during decoding process, as illustrated in Figure 5. From Table 1, we can see that the model with attention mechanism, namely “Ours Atten+Fixed”, achieves higher F-measures on all evaluated data than “Ours NoAtten+Fixed” which does not use attention.
尽管LSTM的最后一个隐藏状态对RoI图像补丁的整体信息进行了编码,但它仍然缺少细节。 特别是对于长字图像补丁,在循环编码过程中可能会丢失初始信息。 因此,我们将每个时间步长的编码器LSTM的隐藏状态作为上下文。 注意模型可以在解码过程中为每个字符选择相应的局部特征,如图5所示。从表1中可以看出,具有注意机制的模型“ Ours Atten + Fixed”在F上获得了更高的F值。 所有评估的数据都比“ Ours NoAtten + Fixed”高,没有引起注意。
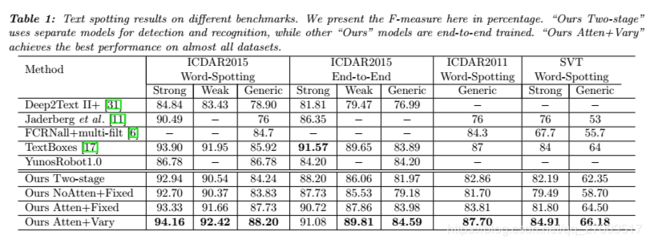
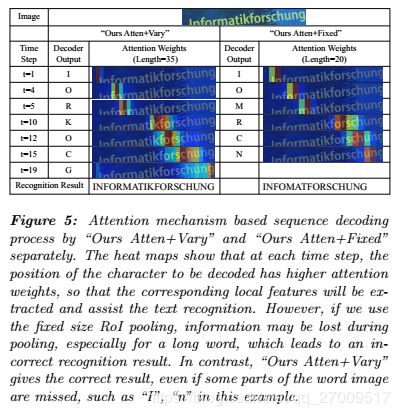
One contribution of this work is a new region feature encoder, which is composed of a varying-size RoI pooling mechanism and an LSTM sequence encoder. To validate its effectiveness, we compare the performance of models “Ours Atten+Vary” and “Ours Atten+Fixed”. Experiments shows that varying-size RoI pooling performs significantly better for long words. For example, “Informatikforschung" can be recognized correctly by \Ours Atten+Vary", but not by “Ours Atten+Fixed” (as shown in Figure 5), because a large portion of information for long words is lost by fixedsize RoI pooling. As illustrated in Table 1, adopting varying-size RoI pooling (“Ours Atten+Vary") instead of fixed- size pooling (“Ours Atten+Fixed") makes Fmeasures increase around 1% for ICDAR2015, 4% for ICDAR2011 and 3% for SVT with strong lexicon used.
这项工作的一个贡献是一个新的区域特征编码器,它由一个大小可变的RoI合并机制和一个LSTM序列编码器组成。 为了验证其有效性,我们比较了“ Ours Atten + Vary”和“ Ours Atten + Fixed”模型的性能。 实验表明,对于长字而言,可变大小的RoI池性能明显更好。 例如,"Ours Atten + Vary“可以正确识别\ Informatikforschung,而” Ours Atten + Fixed“则不能正确识别(如图5所示),因为固定大小的RoI池会丢失长字的大部分信息 。 如表1所示,采用大小可变的RoI池("Ours Atten + Vary“)而不是固定大小的池("Ours Atten + Fixed”)使ICDAR2015的Fmeasure增长约1%,ICDAR2011的Fmeasure增长约4%,ICDAR2011的Fmeasure增长约3%。 用于带有强大词典的SVT。
4.2. Joint Training vs. Separate Training
Previous works [11, 6, 17] on text spotting typically perform in a two-stage manner, where detection and recognition are trained and processed separately. The text bounding boxes detected by a model need to be cropped from the image and then recognized by another model. In contrast, our proposed model is trained jointly for both detection and recognition. By sharing convolutional features and RoI encoder, the knowledge learned from the correlated detection and recognition tasks can be transferred between each other and results in better performance for both tasks.
关于文本点点的先前工作[11、6、17]通常以两阶段的方式执行,其中检测和识别分别进行训练和处理。 一个模型检测到的文本边界框需要从图像中裁剪出来,然后被另一个模型识别。 相比之下,我们提出的模型则经过联合训练以进行检测和识别。 通过共享卷积特征和RoI编码器,可以从相互关联的检测和识别任务中学习到的知识可以在彼此之间传递,从而使这两个任务的性能更好。
To compare with the model “Ours Atten+Vary” which is jointly trained, we build a two-stage system (denoted as “Ours Two-stage”) in which detection and recognition models are trained separately. For fair comparison, the detector in “Ours Two-stage” is built by removing the recognition part from model “Ours Atten+Vary” and trained only with the detection objective (denoted as “Ours DetOnly”). As to recognition, we employ CRNN [23] that produces state-of-the-art performance on text recognition. Model \Ours Twostage" firstly adopts “Ours DetOnly” to detect text with the same multi-scale inputs. CRNN is then followed to recognize the detected bounding boxes. We can see from Table 1 that model “Ours Two-stage” performs worse than “Ours Atten+Vary” on all the evaluated datasets.
为了与共同训练的“ Ours Atten + Vary”模型进行比较,我们构建了一个两阶段系统(称为“ Ours Two-stage”),其中分别对检测和识别模型进行了训练。 为了公平地比较, "Ours Two-stage"中的检测器是通过从模型 "Ours Atten + Vary”中删除识别部分而构建的,并且仅以检测目标(表示为“ "Ours DetOnly”)进行训练。对于识别,我们采用 CRNN [23]产生了最先进的文本识别性能。模型"Ours Twostage“首先采用"Ours DetOnly”来检测具有相同多尺度输入的文本,然后跟随CRNN来识别检测到的边界框 从表1中可以看出,模型“我们的两阶段”在所有评估的数据集上的表现都比“Ours Atten+Vary”差。
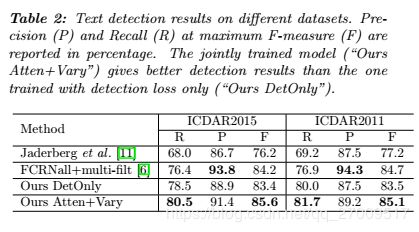
Furthermore, we also compare the detection-only performance of these two systems. Note that “Ours DetOnly” and the detection part of “Ours Atten+Vary” share the same architecture, but they are trained with different strategies: “Ours DetOnly” is optimized with only the detection loss, while “Ours Atten+Vary” is trained with a multi-task loss for both detection and recognition. In consistent with the “End-to- End” evaluation criterion, a detected bounding box is considered to be correct if its IoU ratio with any ground-truth is greater than 0:5. The detection results are presented in Table 2. Without any lexicon used, “Ours Atten+Vary” produces a detection performance with F-measures of 85:6% on ICDAR2015 and 85:1% on ICDAR2011, which are averagely 2% higher than those given by “Ours DetOnly”. This result illustrates that detector performance can be improved via joint training.
此外,我们还比较了这两个系统的仅检测性能。 请注意,“ Ours DetOnly”和“ Ours Atten + Vary”的检测部分共享相同的体系结构,但是它们采用不同的策略进行训练:“ Ours DetOnly”仅优化了检测损失,而“ Ours Atten + Vary”是优化的 经过多任务丢失训练的检测和识别。 与“端到端”评估标准一致,如果检测到的边界框与任何地面真相的IoU比大于0:5,则认为该边界框是正确的。 检测结果列于表2。在不使用任何词典的情况下,“ Ours Atten + Vary”产生的检测性能在ICDAR2015上为85:6%,在ICDAR2011上为85:1%,比平均高出2%。 由“我们的DetOnly”提供的内容。 该结果表明,通过联合训练可以提高探测器的性能。
4.3. Comparison with Other Methods
In this part, we compare the text spotting results of “Ours Atten+Vary” with other state-of-the-art approaches. As shown in Table 1, “Ours Atten+Vary” outperforms all compared methods on most of the evaluated datasets. In particular, our method shows an significant superiority when using a generic lexicon. It leads to a 1:5% higher recall on average than the stateof-the-art TextBoxes [17], using only 3 input scales compared with 5 scales used by TextBoxes.
在这一部分中,我们将“我们的注意力+差异”的文本发现结果与其他最新方法进行了比较。 如表1所示,在大多数评估的数据集上,“ Ours Atten + Vary”优于所有比较方法。 特别是,当使用通用词典时,我们的方法显示出明显的优势。 平均而言,与最新的TextBoxes [17]相比,召回率高出1:5%,仅使用3种输入比例,而TextBoxes使用5种比例。
Several text spotting examples are presented in Figure 6, which demonstrate that model “Ours Atten+Vary” is capable of dealing with words of different aspect ratios and orientations. In addition, our system is able to recognize words even if their bounding boxes do not cover the whole words, as it potentially learned a character-level language model from the synthetic data.
图6中显示了几个文本点样示例,这些示例表明模型“ Ours Atten + Vary”能够处理不同纵横比和方向的单词。 另外,我们的系统能够识别单词,即使它们的边界框不能覆盖整个单词,因为它可能会从合成数据中学习字符级语言模型。
4.4. Speed
Using an M40 GPU, model “Ours Atten+Vary” takes approximately 0:9s to process an input image of 600 × 800 pixels. It takes nearly 0:45s to compute the convolutional features, 0:02s for text proposal calculation, 0:25s for RoI encoding, 0:01s for text detection and 0:15s for word recognition. On the other hand, model “Ours Two-stage” spends around 0:45s for word recognition on the same detected bounding boxes, as it needs to crop the word patches, and re-calculate the convolutional features during recognition.
使用M40 GPU,“ Ours Atten + Vary”模型需要大约0:9s来处理600×800像素的输入图像。 计算卷积特征大约需要0:45s,用于文本提议计算需要0:02s,用于RoI编码需要0:25s,用于文本检测需要0:01s,并且要进行单词识别需要0:15s。 另一方面,模型“我们的两阶段”在相同的检测到的边界框上花费约0:45的时间进行单词识别,因为它需要裁剪单词补丁,并在识别过程中重新计算卷积特征。
5. Conclusion
In this paper we presented a unified end-to-end trainable DNN for simultaneous text detection and recognition in natural scene images. A novel RoI encoding method was proposed, considering the large diversity of aspect ratios of word bounding boxes. With this framework, scene text can be detected and recognized in a single forward pass efficiently and accurately. Experimental results illustrate that the proposed method can produce impressive performance on standard benchmarks. One of potential future works is on handling images with multi-oriented text.
在本文中,我们提出了一种统一的端到端可训练DNN,用于在自然场景图像中同时进行文本检测和识别。 提出了一种新的RoI编码方法,该方法考虑了词边界框的高宽比的多样性。 使用此框架,可以有效且准确地在单个前向通过中检测和识别场景文本。 实验结果表明,所提出的方法在标准基准上可以产生令人印象深刻的性能。 未来可能的工作之一是处理具有多方向文本的图像。