目标检测--IOU,bounding box
文章目录
- 1.IOU的意义
- 2 边框回归是什么?
- 2.1 边框回归怎么做的?
- 2.1.1 Input:
- 2.1.2 Output:
- 2.2 为什么宽高尺度会设计这种形式?
- 2.2.1 x,y 坐标除以宽高
- 2.2.2 宽高坐标Log形式
- 2.2.3 为什么IoU较大,认为是线性变换?
- other
1.IOU的意义

如图红色框和绿色框所示,红色框是Selective Search提取的的Region Proposal记为R,而绿色是我们的实际要达到的检测框(Ground Truth)记为G。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。 如果我们能对红色的框进行微调, 使得经过微调后的窗口跟Ground Truth 更接近, 这样岂不是定位会更准确。 确实,Bounding-box regression 就是用来微调这个窗口的。
IOU就是**(R∩G)/(R∪G)** 。定义这个的目的就是为了在训练时为已标定的Bounding-Box寻找一个能够扩张为该Bounding-Box的Region Proposal,当IOU小于某个值得时候就必须被丢弃,这样的具体原因是因为能够进行Bounding-Box regression的两个框的是差异比较小的,这样才能进行线性模拟(下面会讲述的)。
2 边框回归是什么?
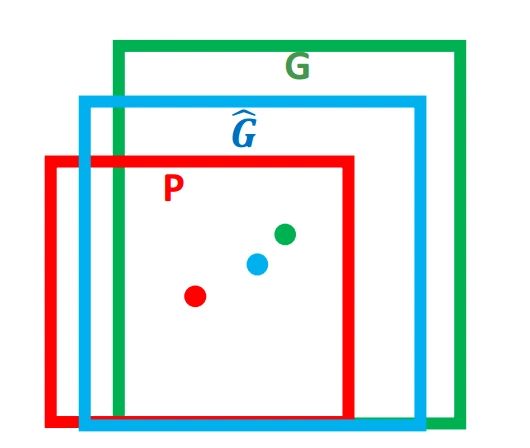
对于窗口一般使用四维向量 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。 对于下图, 红色的框 P P P 代表原始的Region Proposal, 绿色的框 G G G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P P P 经过映射得到一个跟真实窗口 G G G 更接近的回归窗口 G ^ \hat G G^。
边框回归的目的既是:给定 ( P x , P y , P w , P h ) (P_x,P_y,P_w,P_h) (Px,Py,Pw,Ph)寻找一种映射 f f f, 使得 f ( P x , P y , P w , P h ) = ( G ^ x , G ^ y , G ^ w , G ^ h ) f(P_x,P_y,P_w,P_h)=(\hat G_x,\hat G_y,\hat G_w,\hat G_h) f(Px,Py,Pw,Ph)=(G^x,G^y,G^w,G^h)并且 ( G ^ x , G ^ y , G ^ w , G ^ h ) ≈ ( G x , G y , G w , G h ) (\hat G_x,\hat G_y,\hat G_w,\hat G_h)≈(Gx,Gy,Gw,Gh) (G^x,G^y,G^w,G^h)≈(Gx,Gy,Gw,Gh)
2.1 边框回归怎么做的?
那么经过何种变换才能从图 2 中的窗口 P P P 变为窗口 G ^ \hat G G^呢?,用 P P P的参数进行计算, 比较简单的思路就是: 平移+尺度放缩
-
先做平移 ( Δ x , Δ y ) (Δx,Δy) (Δx,Δy), Δ x = P w d x ( P ) Δx=P_wd_x(P) Δx=Pwdx(P), Δ y = P h d y ( P ) Δy=P_hd_y(P) Δy=Phdy(P) 这是R-CNN论文的:
G ^ x = P w d x ( P ) + P x , ( 1 ) \hat G_x=P_wd_x(P)+P_x, (1) G^x=Pwdx(P)+Px,(1)
G ^ y = P h d y ( P ) + P y , ( 2 ) \hat G_y=P_hd_y(P)+P_y, (2) G^y=Phdy(P)+Py,(2) -
然后再做尺度缩放 ( S w , S h ) (S_w, S_h) (Sw,Sh), S w = e x p ( d w ( P ) ) S_w=exp(d_w(P)) Sw=exp(dw(P)), S h = e x p ( d h ( P ) ) S_h=exp(d_h(P)) Sh=exp(dh(P)) , 对应论文中:
G ^ w = P w e x p ( d w ( P ) ) , ( 3 ) \hat G_w=P_wexp(d_w(P)), (3) G^w=Pwexp(dw(P)),(3)
G ^ h = P h e x p ( d h ( P ) ) , ( 4 ) \hat G_h=P_hexp(d_h(P)), (4) G^h=Phexp(dh(P)),(4)
观察(1)-(4)我们发现, 边框回归学习就是 d x ( P ) d_x(P) dx(P), d y ( P ) d_y(P) dy(P), d w ( P ) d_w(P) dw(P), d h ( P ) d_h(P) dh(P)这四个变换。下一步就是设计算法那得到这四个映射。
线性回归就是给定输入的特征向量 X X X, 学习一组参数 W W W, 使得经过线性回归后的值跟真实值 Y(Ground Truth)非常接近. 即 Y ≈ W X Y≈WX Y≈WX 。 那么 Bounding-box 中我们的输入以及输出分别是什么呢?
2.1.1 Input:
R e g i o n P r o p o s a l → P = ( P x , P y , P w , P h ) RegionProposal→P=(Px,Py,Pw,Ph) RegionProposal→P=(Px,Py,Pw,Ph),这个是什么? 输入就是这四个数值吗?其实真正的输入是这个窗口对应的 CNN 特征,也就是 R-CNN 中的 Pool5 feature(特征向量)。 (注:训练阶段输入还包括 Ground Truth, 也就是下边提到的 t ∗ = ( t x , t y , t w , t h ) t_∗=(t_x,t_y,t_w,t_h) t∗=(tx,ty,tw,th)
2.1.2 Output:
需要进行的平移变换和尺度缩放 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) dx(P),dy(P),dw(P),dh(P) dx(P),dy(P),dw(P),dh(P), 或者说是 Δ x , Δ y , S w , S h Δx,Δy,S_w,S_h Δx,Δy,Sw,Sh 。 我们的最终输出不应该是 Ground Truth 吗? 是的, 但是有了这四个变换我们就可以直接得到 Ground Truth, 这里还有个问题, 根据(1)~(4)我们可以知道, P 经过 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) dx(P),dy(P),dw(P),dh(P) dx(P),dy(P),dw(P),dh(P)得到的并不是真实值 G G G, 而是预测值 G ^ \hat G G^。 的确, 这四个值应该是经过 Ground Truth 和 Proposal 计算得到的真正需要的平移量 ( t x , t y ) (t_x, t_y) (tx,ty)和尺度缩放 t w , t h t_w, t_h tw,th。这也就是 R-CNN 中的(6)~(9):
t x = ( G x − P x ) / P w , ( 6 ) t_x=(G_x-P_x)/P_w, (6) tx=(Gx−Px)/Pw,(6)
t y = ( G y − P y ) / P h , ( 7 ) t_y=(G_y-P_y)/P_h, (7) ty=(Gy−Py)/Ph,(7)
t w = l o g ( G w / P w ) , ( 8 ) t_w=log(G_w/P_w), (8) tw=log(Gw/Pw),(8)
t h = l o g ( G h / P h ) , ( 9 ) t_h=log(G_h/P_h), (9) th=log(Gh/Ph),(9)
那么目标函数可以表示为 d ∗ ( P ) = w ∗ T Φ 5 ( P ) d_∗(P)=w^T_∗Φ_5(P) d∗(P)=w∗TΦ5(P), Φ 5 ( P ) Φ_5(P) Φ5(P)是输入 region Proposal 的特征向量, w ∗ w_∗ w∗是要学习的参数( ∗ * ∗表示 x , y , w , h x,y,w,h x,y,w,h, 也就是每一个变换对应一个目标函数) , d ∗ ( P ) d_∗(P) d∗(P)是得到的预测值。 我们要让预测值跟真实值 t ∗ = ( t x , t y , t w , t h ) t_∗=(t_x,t_y,t_w,t_h) t∗=(tx,ty,tw,th)差距最小, 得到损失函数为:
L o s s = ∑ i N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 Loss=\sum^N_i(t^i_*-\hat w ^T_* ϕ_5(P^i))^2 Loss=∑iN(t∗i−w^∗Tϕ5(Pi))2
函数优化目标为:
W ∗ = a r g m i n w ∗ ∑ i N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 + λ ∣ ∣ w ^ ∗ ∣ ∣ 2 ) W_*=argmin_{w_*}\sum^N_i(t^i_*-\hat w^T_*ϕ_5(P^i))^2+\lambda||\hat w_*||^2) W∗=argminw∗∑iN(t∗i−w^∗Tϕ5(Pi))2+λ∣∣w^∗∣∣2)
2.2 为什么宽高尺度会设计这种形式?
这边我重点解释一下为什么设计的 t x , t y tx,ty tx,ty为什么除以宽高,为什么 t w , t h t_w,t_h tw,th会有log形式!!!
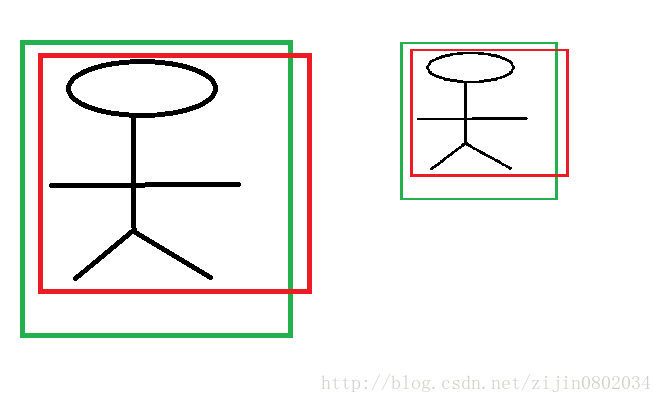
首先CNN具有尺度不变性, 以图3为例:
2.2.1 x,y 坐标除以宽高
上图的两个人具有不同的尺度,因为他都是人,我们得到的特征相同。假设我们得到的特征为 ϕ 1 , ϕ 2 ϕ_1,ϕ_2 ϕ1,ϕ2,那么一个完好的特征应该具备 ϕ 1 = ϕ 2 ϕ_1=ϕ_2 ϕ1=ϕ2。ok,如果我们直接学习坐标差值,以 x x x坐标为例, x i , p i x_i,p_i xi,pi分别代表第 i i i个框的 x x x坐标,学习到的映射为 f f f, f ( ϕ 1 ) = x 1 − p 1 f(ϕ_1)=x_1−p_1 f(ϕ1)=x1−p1,同理 f ( ϕ 2 ) = x 2 − p 2 f(ϕ_2)=x_2−p_2 f(ϕ2)=x2−p2。从上图显而易见, x 1 − p 1 ≠ x 2 − p 1 x_1−p_1≠x_2−p_1 x1−p1=x2−p1。也就是说同一个 x x x对应多个 y y y,这明显不满足函数的定义。边框回归学习的是回归函数,然而你的目标却不满足函数定义,当然学习不到什么。
2.2.2 宽高坐标Log形式
我们想要得到一个放缩的尺度,也就是说这里限制尺度必须大于0。我们学习的 t w , t h t_w,t_h tw,th怎么保证满足大于0呢?直观的想法就是EXP函数,如公式(3), (4)所示,那么反过来推导就是Log函数的来源了。
2.2.3 为什么IoU较大,认为是线性变换?
当输入的 Proposal 与 Ground Truth 相差较小时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归来建模对窗口进行微调, 否则会导致训练的回归模型不 work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这里我来解释:
Log函数明显不满足线性函数,但是为什么当Proposal 和Ground Truth相差较小的时候,就可以认为是一种线性变换呢?大家还记得这个公式不?参看高数1。
l i m x = 0 l o g ( 1 + x ) = x lim_{x=0}log(1+x)=x limx=0log(1+x)=x
现在回过来看公式(8):
t w = l o g ( G w / P w ) = l o g ( G w + P w − P w P w ) = l o g ( 1 + G w − P w P w ) t_w=log(G_w/P_w)=log(\frac{G_w+P_w-P_w}{P_w})=log(1+\frac{G_w-P_w}{P_w}) tw=log(Gw/Pw)=log(PwGw+Pw−Pw)=log(1+PwGw−Pw)
当且仅当 G w − P w = 0 G_w−P_w=0 Gw−Pw=0的时候,才会是线性函数,也就是宽度和高度必须近似相等。
other
如上图中P是训练时生成的边框(要满足IOU的条件) G ^ \hat G G^为中间的经过回归的边框,G是我们训练样本中标定的边框。我们该如何从P生成到 G ^ \hat G G^呢?首先我们需要知道该如何确定一个边框在一幅图的位置对于窗口一般使用四维向量(x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。我们要将P变换到 G ^ \hat G G^只需要进行平移后缩放就可以了,这是几何上的直观想法(本文中 G ^ \hat G G^与P变换后的窗体指代一个对象)

边框回归学习就是 d x ( P ) d_x(P) dx(P), d y ( P ) d_y(P) dy(P), d w ( P ) d_w(P) dw(P), d h ( P ) d_h(P) dh(P)这四个变换。下一步就是设计算法那得到这四个映射。
那么问题就来了,我们从图形中获得的数据不可能真的是坐标,不然就成了在某个位置固定了对应得一个变换方法而不管该位置的图形到底是什么东西。我们获得的对象是该Region Proposal的特征向量,这也是十分合理的,想象一下人在确定一幅图中某个固定大小区域的对象时,如该区域只有对象的一部分图片,我们也是进行扩大视野最后就能看到整个对象了呀,最后的视野也就是Ground Truth。而人接受的输入是像素点,那么对应的在回归中就接受特征向量。
在人接受到图片是就知道该如何移动自己的目光来寻找整个对象,相当于人知道当前看到的部分在实际物体对象中所处的位置后,就知道该如何变换自己的目光和视野范围,如看到左半脸就知道将目光平移到右边再扩大自己的视野。类似的在接收到特定Region Proposal的特征向量,算法应该知道朝什么方向移动和如何进行尺度缩放(这些都是从训练中习得的)。这使用数学语言就是一种由特征向量向 d x ( P ) d_x(P) dx(P), d y ( P ) d_y(P) dy(P), d w ( P ) d_w(P) dw(P), d h ( P ) d_h(P) dh(P)的映射关系!
如何能得到该关系呢,还是要进行训练,下图是我们追求的尺度变换的方法,也就是监督学习中的类似于label的量。
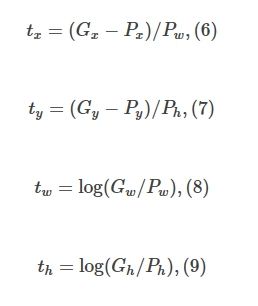
那么我们实际做的尺度变换可以定义为 d ∗ = ( P ) = w ∗ T Φ 5 ( P ) d_*=(P)=w^T_*Φ_5(P) d∗=(P)=w∗TΦ5(P), Φ 5 ( P ) Φ_5(P) Φ5(P)是输入 Proposal 的特征向量, w ∗ w_∗ w∗是要学习的参数( ∗ * ∗表示 x , y , w , h x,y,w,h x,y,w,h, 也就是每一个变换对应一个目标函数,也就是刚刚说的映射关系), d ∗ ( P ) d_∗(P) d∗(P)是得到的预测值。 我们要让预测值跟真实值 t ∗ = ( t x , t y , t w , t h ) t_∗=(t_x,t_y,t_w,t_h) t∗=(tx,ty,tw,th)差距最小, 得到损失函数为:
L o s s = ∑ i N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 Loss=\sum^N_i(t^i_*-\hat w ^T_* ϕ_5(P^i))^2 Loss=∑iN(t∗i−w^∗Tϕ5(Pi))2
优化函数为:
W ∗ = a r g m i n w ∗ ∑ i N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 + λ ∣ ∣ w ^ ∗ ∣ ∣ 2 ) W_*=argmin_{w_*}\sum^N_i(t^i_*-\hat w^T_*ϕ_5(P^i))^2+\lambda||\hat w_*||^2) W∗=argminw∗∑iN(t∗i−w^∗Tϕ5(Pi))2+λ∣∣w^∗∣∣2)
reference:
https://segmentfault.com/a/1190000011918305
https://blog.csdn.net/zijin0802034/article/details/77685438