深度学习经典目标检测实例分割语义分割网络的理解之一 CNN
这一系列的深度学习网络还是放在一起学习会比较深刻。
CNN, 只分类
RCNN, 分类加标框
FAST-RCNN, 快速分类加标框
FASTER-RCNN, 更快地分类加标框
MASK-RCNN 分类标框加上像素级别分割
另外网上已经有很多这系列的博文了,帮了我不少忙,但有些不乏没有说清楚或者是错误的内容,我会尽量避免这些,如有不对的地方请指示出来,非常感谢。
本文参考了的博文
https://blog.csdn.net/panglinzhuo/article/details/75207855 @dadadaplz
https://blog.csdn.net/u012389932/article/details/52946887 @fengbingchun
目前的分割任务主要有两种:
(1)像素级别的语义分割
(2)实例分割
这个有意思,什么叫实例分割呢?它与语义分割有什么区别与联系呢?
顾名思义,像素级别的语义分割,对图像中的每个像素都划分出对应的类别,即实现像素级别的分类;
而类的具体对象,即为实例,那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。比如说图像有多个人甲、乙、丙,那边他们的语义分割结果都是人,而实例分割结果却是不同的对象,具体如下图所示: 
1. 卷积
卷积操作的示意图:
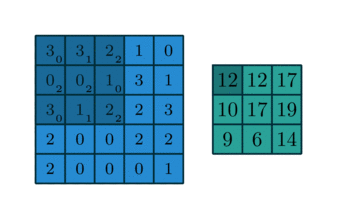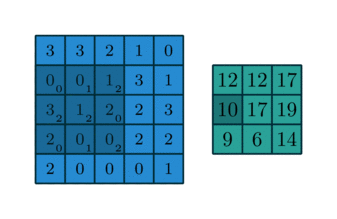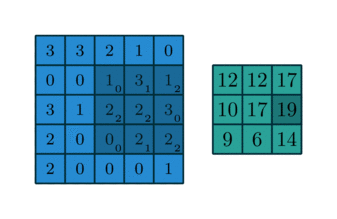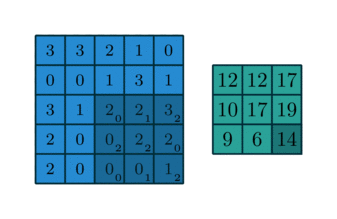
蓝色图像为input feature map;绿色图像为output feature map
当有多个input and output feature maps时,卷积核用一个4-D数组表示:
output_channels,input_channels,filter_rows,filter_columns
output feature maps的个数与output_channels数目相等。
卷积操作的计算方式如下:
已知:
- i input size
- kernel size k
- stride s
- padding size p
则输出大小为: ![]()
特殊的卷积操作
- Half(same) padding
输出size与输入size相同(i.e., o = i)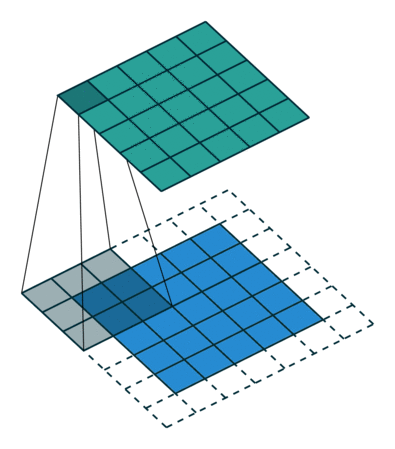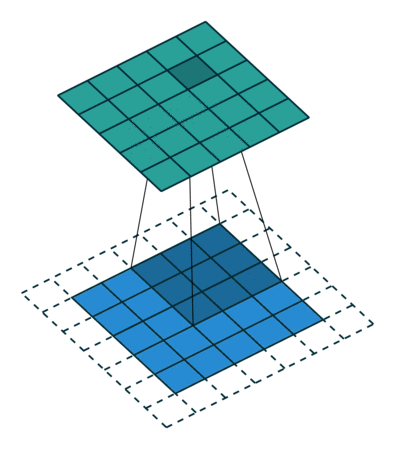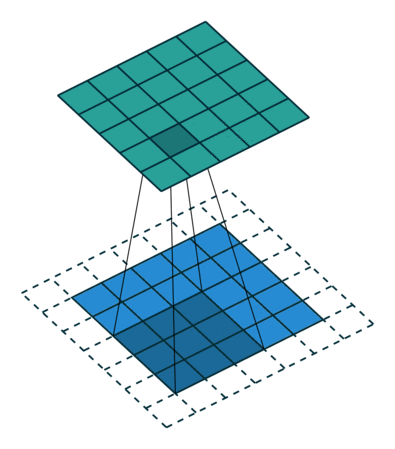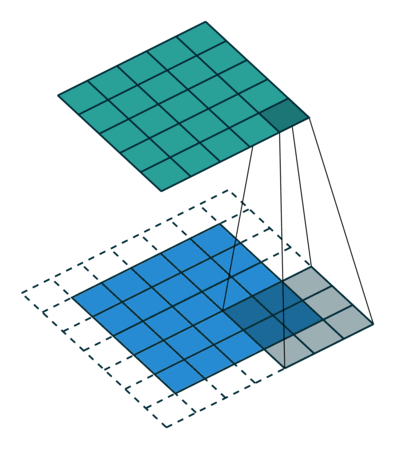
- Full padding
输出size大于输入size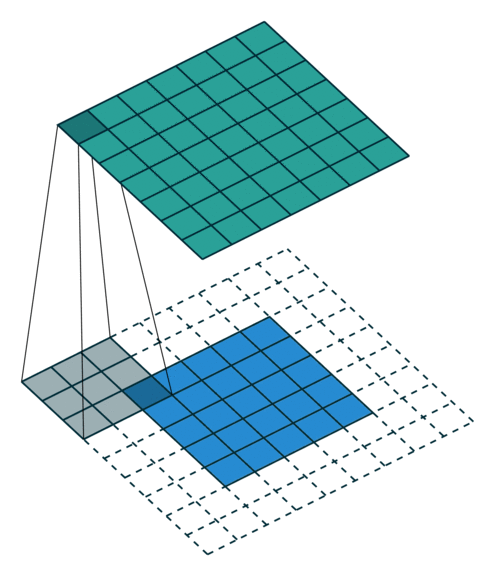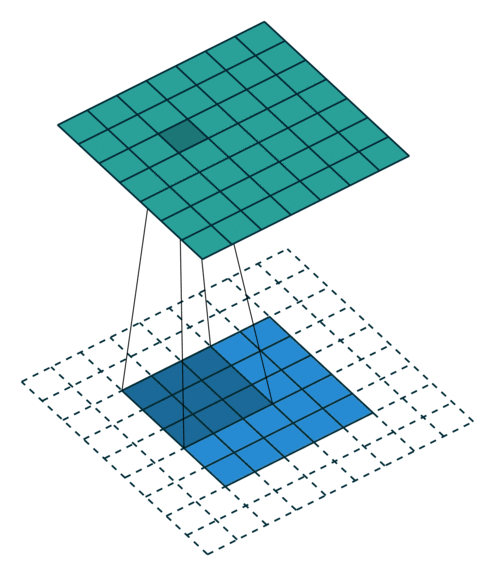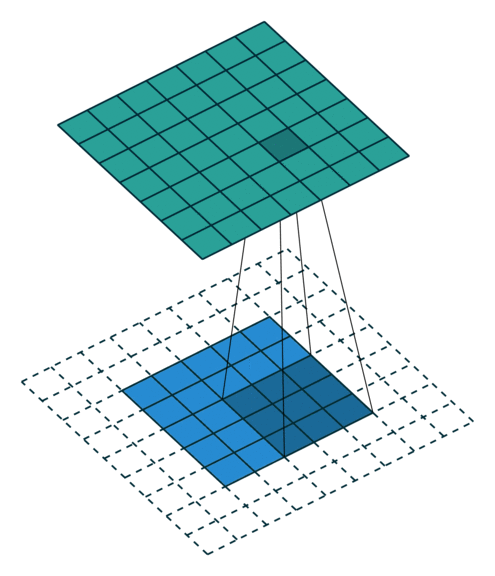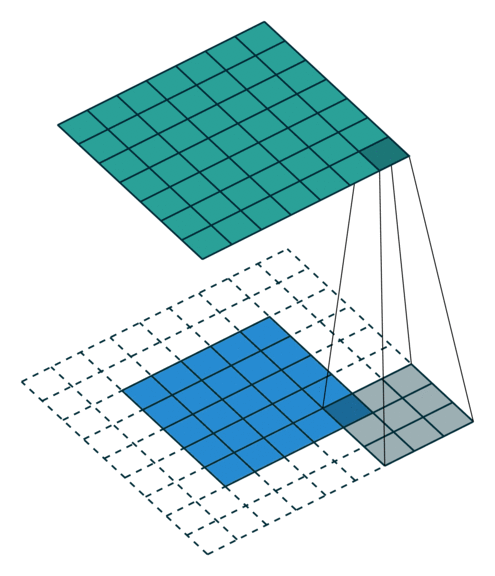
卷积中的矩阵操作
二维卷积数学表达式:
矩阵A(ma, na)矩阵B(mb, nb)则:
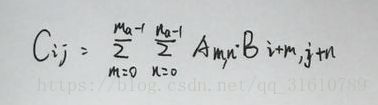
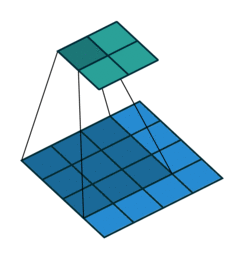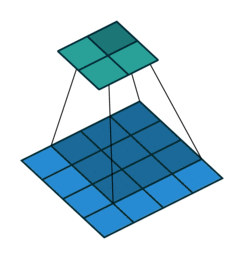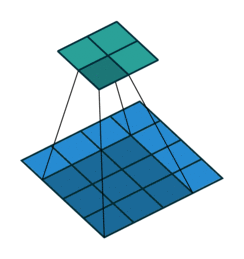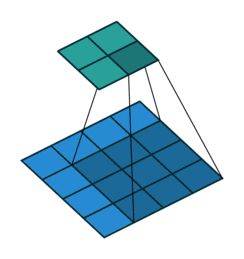
将大小为(3,3)的卷积核表示成如下图所示的(16,4)矩阵C.T(表示矩阵C的转置):
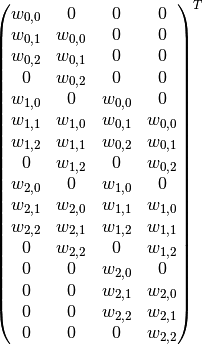
其中w的下标i,j分别表示卷积核的第i行第j列元素。
- 卷积的矩阵操作
将输入4*4的原始图像A展开成(16,1)向量,则将卷积核作用于图像A等同于下面的矩阵操作:
C * A = B
其中,B为卷积后得到的(4,1)向量,再reshape成(2,2)矩阵即为输出。
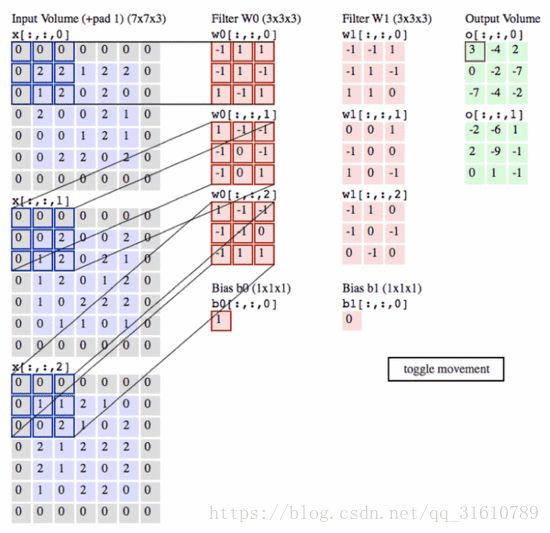
补充一点,多通道的卷积运算机理
下图来自 https://blog.csdn.net/u014114990/article/details/51125776 @deep_learninger
在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小,即将输入的第i个通道分别于第i个kernel卷积之后叠加,得到第一个输出通道map。
下图或许更方便理解:
一般常见的激活函数relu,这里不做扩展。

Polling层的运算:
一般有max polling, mean polling等。
注意polling层的反向传递比FC复杂一些,因为涉及到了下采样,具体可以参见@迷川浩浩_ZJU的下面这篇博文
https://blog.csdn.net/qq_21190081/article/details/72871704
关于卷积和全连接的比较:
在图像处理方面:
FC的缺点: 1. 参数过多,随便上亿
2. 没有利用好像素间的位置关系
3. 网络层数的限制:因为FC很难传递过三层,较深的FC难以训练
CNN的有点:1. 局部连接,减少参数。
2. 权值共享:一组连接可以共享一个权值,减少参数(废话)。
3. 下采样: polling 减少参数,增强鲁棒性。减少不重要的参数,提高准确性,降低过拟合。
一般CNN的框架:
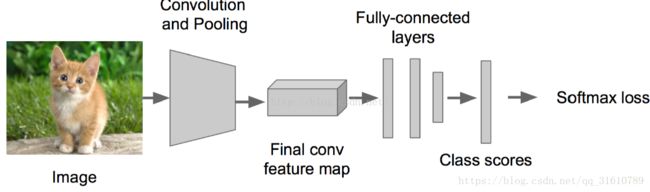
接下来以Alexnet为例,解析它的各种参数:
一个非常重要的公式(虽然使用TensorFlow搭建网络时几乎用不到):
Wo = (Wi - Wk + 2p)/s +1
Wo: 输出尺度
Wi:输入尺度
Wk:卷积核尺度
p: Padding 的圈数(输入外围补零)
s: stride 步长
TensorFlow 中的尺度运算法则!
padding = 'SAME' 输出为ceil(Wi/s)
padding = 'VAILD' 输出为ceil((Wi-Wk+1)/s)
ceil()表示向上取整
一个典型的Alexnet 网络(用单GPU训练的模型,由于现在GPU一般都够Alexnet用了)
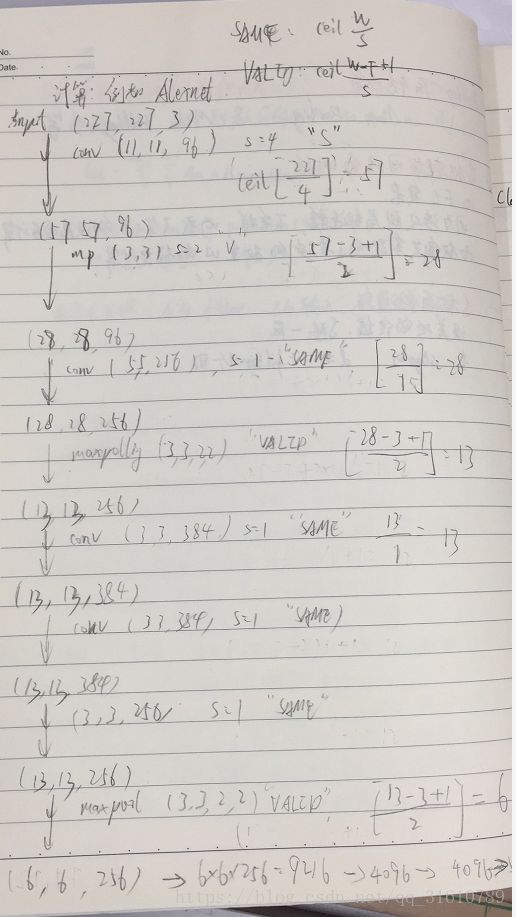
最后FC输出维度是类的个数。