Transformer 与BERT模型
Transformer 与BERT模型
- 1. Transformer
- 1.1 序列到序列任务与Encoder-Decoder框架
- 1.2 Transformer的优势
- 1.3 Transformer的框架原理
- 参考链接
- 2. BERT
- 参考链接:
Task 10
- Transformer的原理。
- BERT的原理。
- 利用预训练的BERT模型将句子转换为句向量,进行文本分类。
参考:
transformer github实现:https://github.com/Kyubyong/transformer
transformer pytorch分步实现:http://nlp.seas.harvard.edu/2018/04/03/attention.html
搞懂Transformer结构,看这篇PyTorch实现就够了:https://www.tinymind.cn/articles/3834
“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统:https://segmentfault.com/a/1190000015575985
bert理论:
bert系列1: https://medium.com/dissecting-bert/dissecting-be…
bert系列2: https://medium.com/dissecting-bert/dissecting-be…
bert系列3: https://medium.com/dissecting-bert/dissecting-be…
5 分钟入门 Google 最强NLP模型:BERT:https://www.jianshu.com/p/d110d0c13063
BERT – State of the Art Language Model for NLP: BERT – State of the Art Language Model for NLP https://www.lyrn.ai/2018/11/07/explained-bert-state-of-the-art-language-model-for-nlp/
google开源代码:GitHub - google-research/bert: https://github.com/google-research/bert
bert实践:
干货 BERT fine-tune 终极实践教程: 干货 | BERT fine-tune 终极实践教程 - 简书https://www.jianshu.com/p/aa2eff7ec5c1
小数据福音!BERT在极小数据下带来显著提升的开源实现: 小数据福音!BERT在极小数据下带来显著提升的开源实现 https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650752891&idx=5&sn=8a44293a57da96db51b9a13feb6223d7&chksm=871a8305b06d0a134e332a6831dbacc9ee79b28a79658c130fe6162f33211788cab18a55ec90&scene=21#wechat_redirect
BERT实战(源码分析+踩坑):BERT实战(源码分析+踩坑) - 知乎
https://zhuanlan.zhihu.com/p/58471554
1. Transformer
1.1 序列到序列任务与Encoder-Decoder框架
序列到序列(Sequence-to-Sequence)是自然语言处理中的一个常见任务,主要用来做泛文本生成的任务,像机器翻译、文本摘要、歌词/故事生成、对话机器人等。
目前Encoder-Decoder框架是解决序列到序列问题的一个主流模型。模型使用Encoder对source sequence进行压缩表示,使用Decoder基于源端的压缩表示生成target sequence。该结构的好处是可以实现两个sequence之间end-to-end方式的建模,模型中所有的参数变量统一到一个目标函数下进行训练,模型表现较好。
图1展示了Encoder-Decoder模型的结构,从底向上是一个机器翻译的过程。
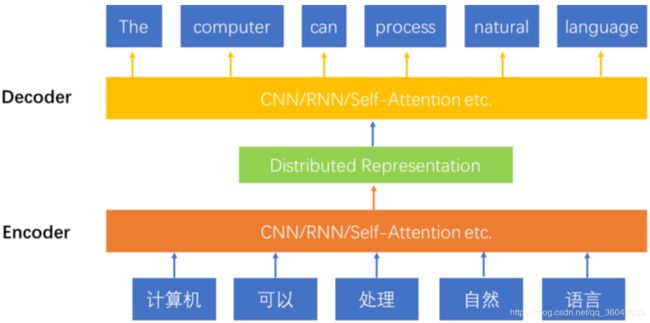
图1: 使用Encoder-Decoder模型建模序列到序列的问题
Encoder和Decoder可以选用不同结构的Neural Network,比如RNN、CNN。RNN的工作方式是对序列根据时间步,依次进行压缩表示。使用RNN的时候,一般会使用双向的RNN结构。具体方式是使用一个RNN对序列中的元素进行从左往右的压缩表示,另一个RNN对序列进行从右向左的压缩表示。两种表示被联合起来使用,作为最终序列的分布式表示。使用CNN结构的时候,一般使用多层的结构,来实现序列局部表示到全局表示的过程。使用RNN建模句子可以看做是一种时间序列的观点,使用CNN建模句子可以看做一种结构化的观点。使用RNN结构的序列到序列模型主要包括RNNSearch、GNMT等,使用CNN结构的序列到序列模型主要有ConvS2S等。
1.2 Transformer的优势
Transformer是一种建模序列的新方法,序列到序列的模型依然是沿用了上述经典的Encoder-Decoder结构,不同的是不再使用RNN或是CNN作为序列建模机制了,而是使用了self-attention机制。这种机制理论上的优势就是更容易捕获“长距离依赖信息(long distance dependency)
**为什么Transformer中的self-attention理论上能够更好的捕获这种长短距离的依赖知识呢?**我们直观的来看一下,基于RNN、CNN、self-attention的三种序列建模方法,任意两个词之间的交互距离上的区别。
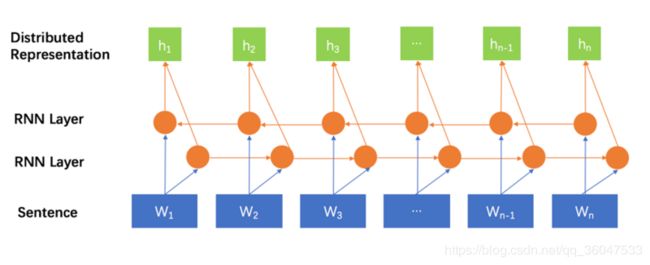
图2 使用双向RNN对序列进行建模
图2是一个使用双向RNN来对序列进行建模的方法。由于是对序列中的元素按顺序处理的,两个词之间的交互距离可以认为是他们之间的相对距离。W1和Wn之间的交互距离是n-1。带有门控(Gate)机制的RNN模型理论上可以对历史信息进行有选择的存储和遗忘,具有比纯RNN结构更好的表现,但是门控参数量一定的情况下,这种能力是一定的。随着句子的增长,相对距离的增大,存在明显的理论上限。

图3 使用多层CNN对序列进行建模
图3展示了使用多层CNN对序列进行建模的方法。第一层的CNN单元覆盖的语义环境范围较小,第二层覆盖的语义环境范围会变大,依次类推,越深层的CNN单元,覆盖的语义环境会越大。一个词首先会在底层CNN单元上与其近距离的词产生交互,然后在稍高层次的CNN单元上与其更远一些词产生交互。所以,多层的CNN结构体现的是一种从局部到全局的特征抽取过程。词之间的交互距离,与他们的相对距离成正比。距离较远的词只能在较高的CNN节点上相遇,才产生交互。这个过程可能会存在较多的信息丢失。

图4 使用self-attention对序列进行建模
图4展示的是基于self-attention机制的序列建模方法。注意,为了使图展示的更清晰,少画了一些连接线,图中“sentence”层中的每个词和第一层self-attention layer中的节点都是全连接的关系,第一层self-attention layer和第二层self-attention layer之间的节点也都是全连接的关系。我们可以看到在这种建模方法中,任意两个词之间的交互距离都是1,与词之间的相对距离不存在关系。这种方式下,每个词的语义的确定,都考虑了与整个句子中所有的词的关系。多层的self-attention机制,使得这种全局交互变的更加复杂,能够捕获到更多的信息。
综上,self-attention机制在建模序列问题时,能够捕获长距离依赖知识,具有更好的理论基础。
1.3 Transformer的框架原理
Transformer的整体结构如下图所示,在Encoder和Decoder中都使用了Self-attention, Point-wise和全连接层。Encoder和decoder的大致结构分别如下图的左半部分和右半部分所示。

图5 Transformer模型结构
图5中,左侧的Nx代表一层的Encoder,这一层中包含了两个子层(sub-layer),第一个子层是多头的self-attention layer,第二个子层是一个Feed Forward层。每个子层的输入和输出都存在着residual connection,这种方式理论上可以很好的回传梯度。Layer Normalization的使用可以加快模型的收敛速度。self-attention子层的计算,我们前面用了不少的篇幅讲过了,这里就不再赘述了。Feed Forward子层实现中有两次线性变换,一次Relu非线性激活,具体计算公式如下:
![]()
参考链接
以上内容来自以下链接,更深入的内容请看原链接
https://segmentfault.com/a/1190000015575985
https://www.tinymind.cn/articles/3834
2. BERT
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型。
BERT 的创新点在于它将双向 Transformer 用于语言模型,双向训练的语言模型对语境的理解会比单向的语言模型更深刻。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。

Bert代码结构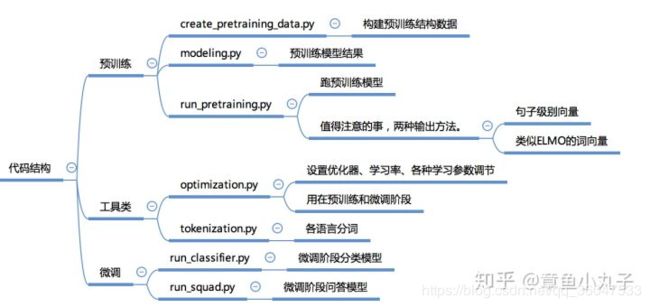
近期面试有点多,缓缓再补充内容,呜呜呜~~~~~
参考链接:
https://www.jianshu.com/p/d110d0c13063
https://zhuanlan.zhihu.com/p/58471554