分布式存储系统HDFS(特详细)
Hadoop基础
Hadoop核心组件
1.分布式存储系统HDFS(Hadoop Distributed File System)分布式存储层
2.资源管理系统YARN(Yet Another Resource Negotiator)集群资源管理层
3.分布式计算框架MapReduce分布式计算层
模式分类
1.单机模式(Standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
2.伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。5个进程的介绍http://www.aboutyun.com/thread-7088-1-1.html
3.全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
评论:意思是说master上看到namenode,jobtracer,secondarynamenode可以安装在master节点,也可以单独安装。slave节点能看到datanode和nodeManage
HDFS的起源
源于Google的GFS论文 发表于2003年10月 HDFS是GFS的克隆版!
什么是GFS? http://www.cnblogs.com/999-/p/7120490.html
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
GFS 也就是 google File System,Google公司为了存储海量搜索数据而设计的专用文件系统。
HDFS
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统)是一个高度容错性的系统,适合部署在廉价的机器上。HDFS 能提供高吞吐量的数据访问,适合那些有着超大数据集(largedata set)的应用程序。
核心
NameNode
DataNode
SecondaryNameNode(NameNode的快照)
HDFS是一个主从结构,一个HDFS集群由一个名字节点(NameNode)和多个数据节点(DataNode)组成。
HDFS的优点(设计思想)
1.高容错性
HDFS 认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
数据自动保存多个节点;
备份丢失后,自动恢复。
2.海量数据的存储
非常适合上T 级别的大文件或者一堆大数据文件的存储
3.文件分块存储
HDFS 将一个完整的大文件平均分块(通常每块64M)存储到不同计算机上,这样读取文件可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得多。
4.移动计算
在数据存储的地方进行计算,而不是把数据拉取到计算的地方,降低了成本,提高了性能!
5.流式数据访问
一次写入,并行读取。不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
6.可构建在廉价的机器上
通过多副本提高可靠性,提供了容错和恢复机制。HDFS 可以应用在普通PC 机上,这种机制能够让一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
NameNode
作用
01.它是一个管理文件的命名空间
02.协调客户端对文件的访问
03.记录每个文件数据在各个DataNode上的位置和副本信息
文件解析
version :是一个properties文件,保存了HDFS的版本号
editlog :任何对文件系统数据产生的操作,都会被保存!
fsimage /.md5:文件系统元数据的一个永久性的检查点,包括数据块到文件的映射、文件的属性等
seen_txid :非常重要,是存放事务相关信息的文件
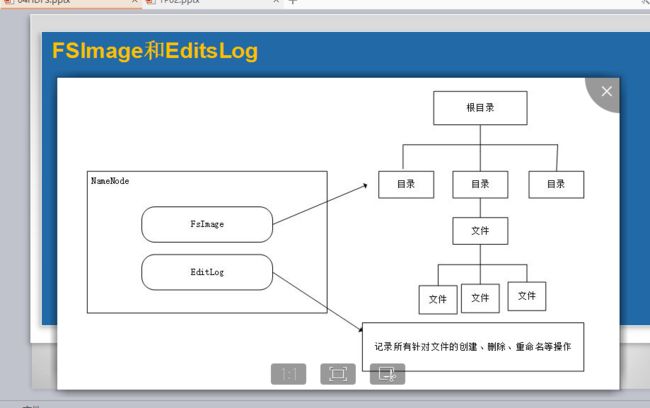
什么是FSImage和EditsLog
HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。
问题?
01.一个文件存储在哪些DataNode节点?
02.又存在DataNode节点的哪些位置?
这些描述了文件存储的节点,以及具体位置的信息(元数据信息(metadata))由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。
03.HDFS是如何及时更新这些metadata的呢?
FsImage和Editlog是HDFS的核心数据结构。这些文件的损坏会导致整个集群的失效。因此,名字节点可以配置成支持多个FsImage和EditLog的副本。任何FsImage和EditLog的更新都会同步到每一份副本中。
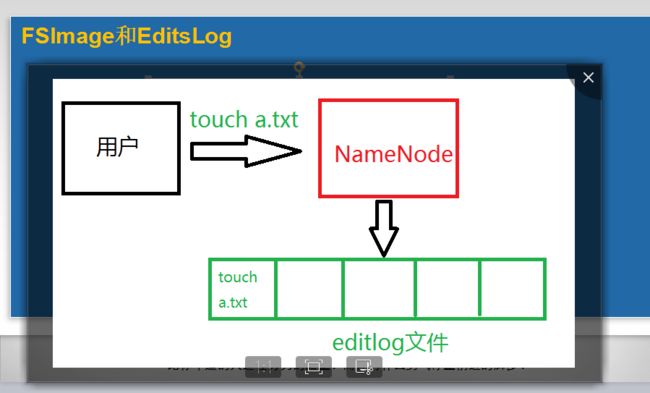
EditLog文件不断变大的问题
01.在名称节点运行期间,HDFS的所有更新操作都是直接到EditLog,一段时间之后,EditLog文件会变得很大
02.虽然这对名称节点运行时候没有什么明显影响,但是,当名称节点重启时候,名称节点需要先将FsImage里面的所有内容映象到内存,然后一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作会非常的慢
解决方案:使用secondaryNameNode
SecondaryNameNode
作用
01.Namenode的一个快照,周期性的备份Namenode
02.记录Namenode中的metadata及其它数据
03.可以用来恢复Namenode,并不能替代NameNode!
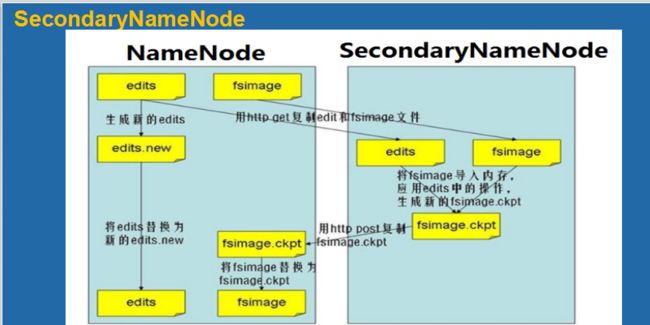
SecondaryNameNode
执行流程
01.SecondaryNameNode节点会定期和NameNode通信,请求其停止使用EditLog,暂时将新的写操作到一个新的文件edit.new上来,这个操作是瞬间完成的。
02.SecondaryNameNode 通过HTTP Get方式从NameNode上获取到FsImage和EditLog文件并下载到本地目录
03.将下载下来的FsImage 和EditLog加载到内存中这个过程就是FsImage和EditLog的合并(checkpoint)
04.合并成功之后,会通过post方式将新的FsImage文件发送NameNode上。
05.SecondaryNamenode 会将新接收到的FsImage替换掉旧的,同时将edit.new替换EditLog,这样EditLog就会变小。
DataNode
1.作用
01.真实数据的存储管理
02.一次写入,多次读取(不修改)
03.文件由数据块组成,Hadoop2.x的块大小默认是128MB
04.将数据块尽量散布到各个节点
2.文件解析
blk_
blk_
可以通过修改hdfs-site.xml的dfs.replication属性设置产生副本的个数!默认是3!
DataNode数据块
文件按大小被切分成若干个block,存储到不同的节点上
1.x的默认数据块大小64M
2.x的默认数据块大小128M
默认情况下每个block有三个备份
在我们启动服务之后我们关闭master的防火墙 然后在我们windows的浏览器上 进入 ip:50070 例如:192.168.1.10:50079
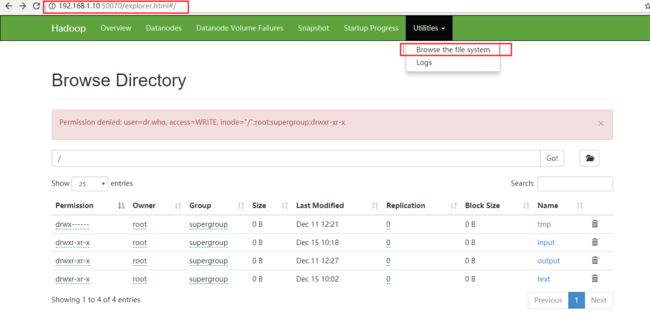
这里可以更直接显示 我们对文件的操作
例如增删改。。。
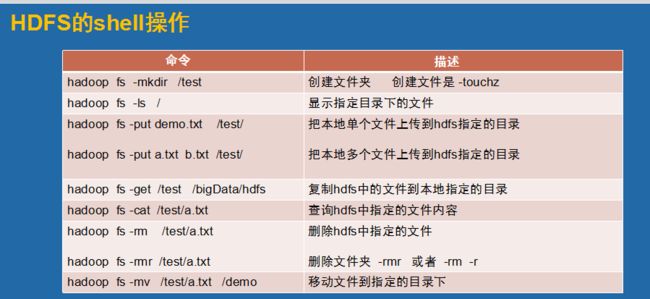
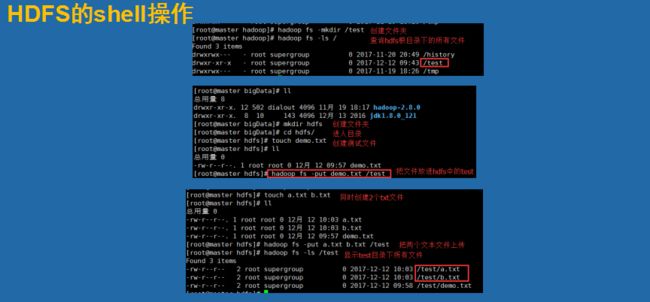
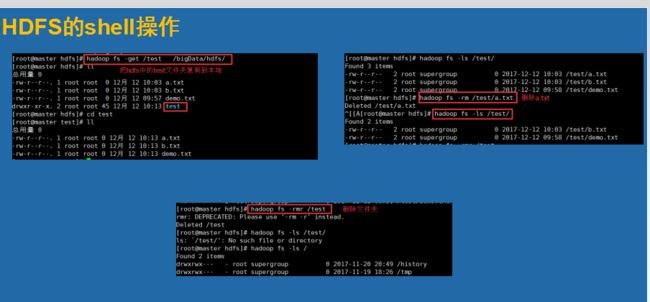
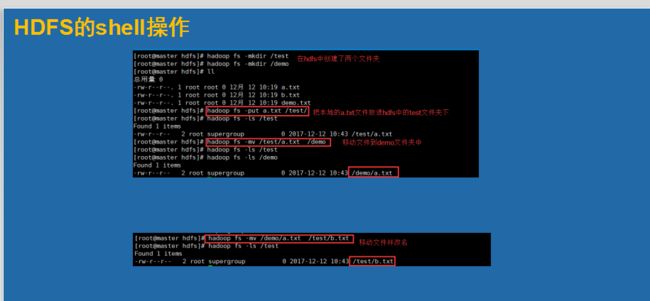
在shell上面我们除了一些常用的命令

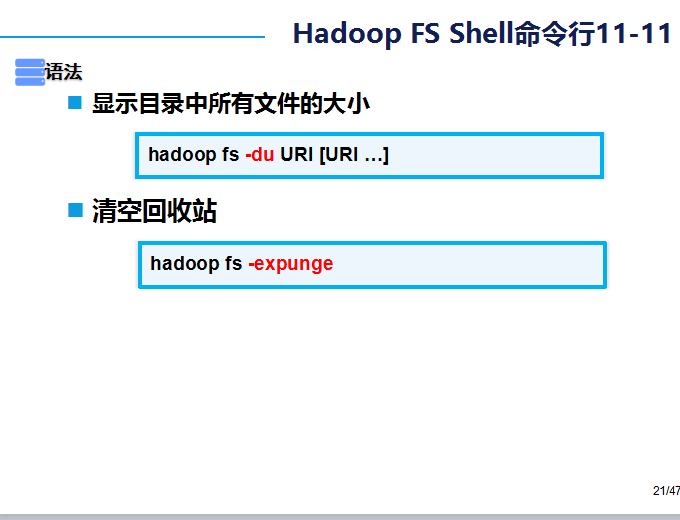
这里我们引入了一个 回收站的观点
这里我们需要配置东西
开启HDFS的回收站功能:
首先:执行stop-dfs.sh命令脚本关闭HDFS
只需在namenode节点上的core-site.xml文件中,添加如下两个属性:
fs.trash.interval
10080
Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.
fs.trash.checkpoint.interval
0
Number of minutes between trash checkpoints. Should be smaller or equal to fs.trash.interval. If zero, the value is set to the value of fs.trash.interval.
fs.trash.interval:丢进回收站中的文件多久后(准确的说是多少分钟后)会被系统永久删除;这里10080是7天;
fs.trash.checkpoint.interval:前后两次检查点的创建时间间隔(单位也是分钟);新的检查点被创建后,随之旧的检查点就会被系统永久删除;
重启HDFS,执行hadoop命令来删除HDFS上的某个文件或目录:hadoop fs -rm -r /data会提示/data被移动至:hdfs://yourcluster:9820/user/hadoop/.Trash/Current
如果你想直接删除某个文件,而不把其放在回收站,就要用到-skipTrash命令
例如:hadoop fs -rm -r -skipTrash /test
hadoop fs -expunge的命令是清空回收站
完成