Java多线程之线程池原理剖析,锁的深度化
目录
1 线程池
1.1 好处
1.2 作用
1.3 线程池创建方式
1.4 原理分析
1.5 线程池合理配置
2 锁的深度化
2.1 悲观锁
2.2 乐观锁
2.3 重入锁
2.4 读写锁
2.5 CAS无锁机制
2.6 自旋锁
2.7 分布式锁
1 线程池
1.1 好处
1)降低资源消耗,重复利用已经创建好的线程,降低线程创建和销毁造成的消耗
2)提高响应速度,当任务到达时,任务可以不需要等到线程创建就可以立即执行
3)提高线程的可管理性,线程是稀缺资源,如果无限制的创建,不仅消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
1.2 作用
为了突然大量爆发的线程设计的,通过有限的几个固定线程为大量的的操作服务,减少了创建和销毁线程所需时间,从而提高效率。如果一个线程的时间非常长,就没必要用线程池了(不是不能作长时间操作,而是不宜。),况且我们还不能控制线程池中线程的开始、挂起、和中止。
1.3 线程池创建方式
线程池核心走ThreadPoolExecutor构造函数,但是我们大多数情况下使用Executor封装好的四中线程池创建方式。
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
public class Test {
public static void main(String[] args) {
//可缓存的线程池 重复利用已经创建的线程
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
int temp=i;
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("threadName:"+Thread.currentThread().getName()+",i:"+temp);
}
});
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
threadName:pool-1-thread-1,i:0
threadName:pool-1-thread-2,i:1
threadName:pool-1-thread-2,i:2
threadName:pool-1-thread-2,i:3
threadName:pool-1-thread-1,i:5
threadName:pool-1-thread-2,i:4
threadName:pool-1-thread-2,i:6
threadName:pool-1-thread-2,i:7
threadName:pool-1-thread-2,i:8
threadName:pool-1-thread-2,i:9
仅仅创建了两个线程,说明重复利用已经创建好的线程......newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
1.4 原理分析
ThreadPoolExecutor构造函数参数:
corePoolSize: 核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中
maximumPoolSize: 线程池最大线程数,它表示在线程池中最多能创建多少个线程;
keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。
unit: 参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
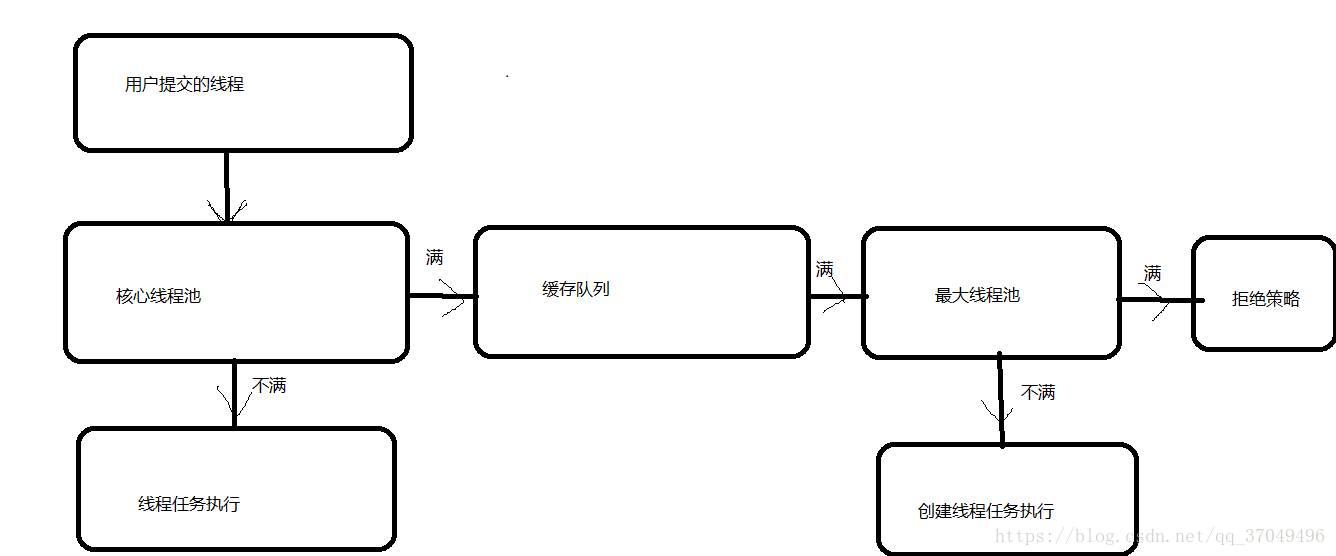
提交一个任务到线程池中,线程池的处理流程如下:
1)判断核心线程池是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建也就是没有达到核心线程大小),则创建一个新的工作线来执行任务。如果核心线程都在执行任务,则进入下个流程。
2)判断线程池的缓存队列是否已满,如果没满,则将新提交的任务存储在这个工作队列中,否则进入下个流程。
3)判断最大线程池里的线程是否都处于工作状态也就是是否达到了最大线程池个数,如果没有,则创建一个新的工作线程来执行任务,如果已经满了,则交给饱和策略来处理这个任务。
1.5 线程池合理配置
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
一般总结哦,有其他更好的方式,希望各位留言,谢谢。
CPU密集型时,任务可以少配置线程数,大概和机器的cpu核数相当,这样可以使得每个线程都在执行任务
IO密集型时,大部分线程都阻塞,故需要多配置线程数,2*cpu核数
操作系统之名称解释:
某些进程花费了绝大多数时间在计算上,而其他则在等待I/O上花费了大多是时间,
前者称为计算密集型(CPU密集型)computer-bound,后者称为I/O密集型,I/O-bound。
2 锁的深度化
2.1 悲观锁
悲观锁认为每次查询数据数据都会造成数据的更新或者丢失问题,所以每次查询都会加上排它锁。

如图所示:当有两个jdbc连接同时操作以上sql时,会产生数据脏读导致总金额为真实的两倍。使用悲观锁则通过在其后加for update后,仅允许一个连接查询数据也就是只要一个连接获得锁后,其他连接则只能等待该锁的释放。
缺点:每次只有一个连接操作,效率极低,适合查询量下的情况
2.2 乐观锁
乐观锁认为每次查询都不会造成数据更新丢失,使用版本字段控制。
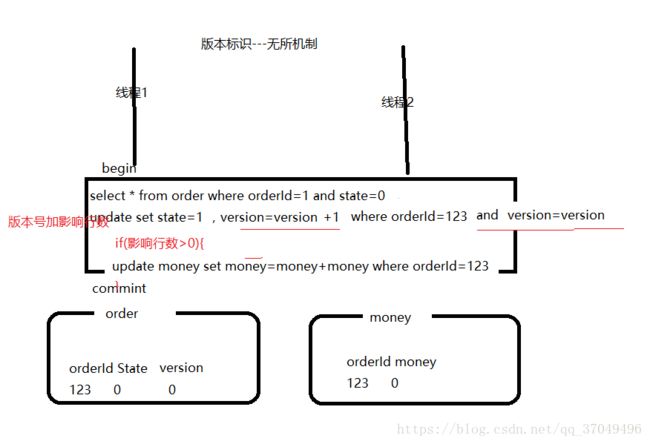
如图所示,当两个线程同时操作时,如果线程1执行到第一个update语句,它将会将version值设置为原来的加1,此时线程2就无法通过version来获取该条已经修改过的记录,从而保证了数据重复读、写。通过第二句的影响行数是否大于0来判断金额的更新问题。优点可并发运行,效率较高。缺点需要加个version字段而且有可能发生查不到的情况
2.3 重入锁
重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。
非重入锁进行以上操作的话就会产生死锁。
public class Test02 extends Thread {
ReentrantLock lock = new ReentrantLock();
public void get() {
lock.lock();
System.out.println(Thread.currentThread().getId());
set();
lock.unlock();
}
public void set() {
lock.lock();
System.out.println(Thread.currentThread().getId());
lock.unlock();
}
@Override
public void run() {
get();
}
public static void main(String[] args) {
Test ss = new Test();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
}
}
2.4 读写锁
假设你的程序中涉及到对一些共享资源的读和写操作,且写操作没有读操作那么频繁。在没有写操作的时候,两个线程同时读一个资源没有任何问题,所以应该允许多个线程能在同时读取共享资源。但是如果有一个线程想去写这些共享资源,就不应该再有其它线程对该资源进行读或写(译者注:也就是说:读-读能共存,读-写不能共存,写-写不能共存)。这就需要一个读/写锁来解决这个问题。常用语缓存设计。
public class Cache {
private static volatile Map map=new HashMap<>();
private static ReentrantReadWriteLock reentrantReadWriteLock=new ReentrantReadWriteLock();
private static Lock r=reentrantReadWriteLock.readLock();
private static Lock w=reentrantReadWriteLock.writeLock();
/**
* 写
* @param key
* @param object
*/
public static void put(String key,Object object){
try{
// w.lock();
System.out.println("正在写入key:"+key+",value:"+object+"开始。。");
Thread.sleep(100);
Object obj=map.put(key,object);
System.out.println("写入key:"+key+",value:"+object+"结束。。");
} catch (Exception e) {
e.printStackTrace();
} finally {
// w.unlock();
}
}
/**
* 读
* @param key
* @return
*/
public static Object get(String key){
try{
// r.lock();
System.out.println("正在读取key:"+key+"开始。。");
Thread.sleep(100);
Object obj=map.get(key);
System.out.println("读取key:"+key+",value:"+obj+"结束。。");
return obj;
} catch (Exception e) {
e.printStackTrace();
} finally {
// r.unlock();
}
return null;
}
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
Cache.put(i+"",i+"");
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Cache.get(i+""));
}
}
}).start();
}
}
输出如下:
正在写入key:0,value:0开始。。
正在读取key:0开始。。
读取key:0,value:null结束。。
写入key:0,value:0结束。。
正在写入key:1,value:1开始。。
null
正在读取key:1开始。。
读取key:1,value:null结束。。
null
写入key:1,value:1结束。。
正在写入key:2,value:2开始。。
正在读取key:2开始。。
写入key:2,value:2结束。。
读取key:2,value:null结束。。
null
正在写入key:3,value:3开始。。
正在读取key:3开始。。
写入key:3,value:3结束。。
读取key:3,value:null结束。。
null
正在读取key:4开始。。
正在写入key:4,value:4开始。。
写入key:4,value:4结束。。
读取key:4,value:4结束。。
4
正在写入key:5,value:5开始。。
正在读取key:5开始。。
读取key:5,value:null结束。。
null
正在读取key:6开始。。
写入key:5,value:5结束。。
正在写入key:6,value:6开始。。
写入key:6,value:6结束。。
正在写入key:7,value:7开始。。
读取key:6,value:6结束。。
6
正在读取key:7开始。。
读取key:7,value:null结束。。
null
正在读取key:8开始。。
写入key:7,value:7结束。。
正在写入key:8,value:8开始。。
写入key:8,value:8结束。。
正在写入key:9,value:9开始。。
读取key:8,value:8结束。。
8
正在读取key:9开始。。
写入key:9,value:9结束。。
读取key:9,value:9结束。。
9 可以看到写入数据的时候发生了读取数据,所以导致数据安全问题。通过去掉注释后可避免此种情况,读写分离。。。
2.5 CAS无锁机制
原子类底层使用CAS无锁机制实现保证线程安全,CAS无锁机制效率比有锁机制高。
(1)与锁相比,使用比较交换(下文简称CAS)会使程序看起来更加复杂一些。但由于其非阻塞性,它对死锁问题天生免疫,并且,线程间的相互影响也远远比基于锁的方式要小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
(2)无锁的好处:
第一,在高并发的情况下,它比有锁的程序拥有更好的性能;
第二,它天生就是死锁免疫的。
就凭借这两个优势,就值得我们冒险尝试使用无锁的并发。
(3)CAS算法的过程是这样:它包含三个参数CAS(V,E,N): V表示要更新的变量,E表示预期值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。
(4)CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
(5)简单地说,CAS需要你额外给出一个期望值,也就是你认为这个变量现在应该是什么样子的。如果变量不是你想象的那样,那说明它已经被别人修改过了。你就重新读取,再次尝试修改就好了。
(6)在硬件层面,大部分的现代处理器都已经支持原子化的CAS指令。在JDK 5.0以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且,这种操作在虚拟机中可以说是无处不在。

2.6 自旋锁
自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时 才能进入临界区。
class SpinLock{
private AtomicReference sign=new AtomicReference<>();
public void lock(){
Thread thread=Thread.currentThread();
while(!sign.compareAndSet(null,thread)){
}
}
public void unlock(){
Thread thread=Thread.currentThread();
sign.compareAndSet(thread,null);
}
}
public class Test implements Runnable{
static int sum;
private SpinLock lock;
public Test(SpinLock lock){
this.lock=lock;
}
public static void main(String[] args) throws InterruptedException {
SpinLock spinLock=new SpinLock();
for (int i = 0; i < 100; i++) {
Test test=new Test(spinLock);
Thread thread=new Thread(test);
thread.start();
}
Thread.sleep(1000);
System.out.println(sum);
}
@Override
public void run() {
this.lock.lock();
this.lock.lock();
sum++;
this.lock.unlock();
this.lock.unlock();
}
}
当一个线程 调用这个不可重入的自旋锁去加锁的时候没问题,当再次调用lock()的时候,因为自旋锁的持有引用已经不为空了,该线程对象会误认为是别人的线程持有了自旋锁
使用了CAS原子操作,lock函数将owner设置为当前线程,并且预测原来的值为空。unlock函数将owner设置为null,并且预测值为当前线程。
当有第二个线程调用lock操作时由于owner值不为空,导致循环一直被执行,直至第一个线程调用unlock函数将owner设置为null,第二个线程才能进入临界区。
由于自旋锁只是将当前线程不停地执行循环体,不进行线程状态的改变,所以响应速度更快。但当线程数不停增加时,性能下降明显,因为每个线程都需要执行,占用CPU时间。如果线程竞争不激烈,并且保持锁的时间段。适合使用自旋锁。
2.7 分布式锁
如果想在不同的jvm中保证数据同步,使用分布式锁技术。
有数据库实现、缓存实现、Zookeeper分布式锁