搞懂闭包
闭包这个概念是前端工程师必须要深刻理解的,但是网上确实有一些文章会让初学者觉得晦涩难懂,而且闭包的文章描述不一。
本文面向初级的程序员,聊一聊我对闭包的理解。当然如果你看到闭包联想不到作用域链与垃圾回收也不妨看一眼,希望读了它之后你不再对闭包蒙圈。
先体验一下闭包
这里有个需求,即写一个计数器的函数,每调用一次计数器返回值加一:
counter() // 1
counter() // 2
counter() // 3
......
要想函数每次执行的返回不一样,怎么搞呢? 先简单的写一下:
var index = 1;
function counter() {
return index ++;
}
这样做的确每次返回一个递增的数。但是,它有以下三个问题:
- 这个index放在全局,其他代码可能会对他进行修改
- 如果我需要同时用两个计数器,但这种写法只能满足一个使用,另一个还想用的话就要再写个counter2函数,再定义一个index2的全局变量。
- 计数器是一个功能,我只希望我的代码里有个 counter函数就好,其他的最好不要出现。这是稍微有点代码洁癖的都会觉得不爽的。
三个痛点,让闭包来一次性优雅解决:
function counterCreator() {
var index = 1;
function counter() {
return index ++;
}
return counter;
}
// test
var counterA = counterCreator();
var counterB = counterCreator();
counterA(); // 1
counterA(); // 2
counterB(); // 1
counterB(); // 2
我的counterCreator函数只是把上面的几行代码包起来,然后返回了里面的 counter 函数而已。却能同时解决这么多问题,这就是闭包的魅力! 6不6啊?

铺垫知识
铺垫一些知识点,不展开讲。
执行上下文
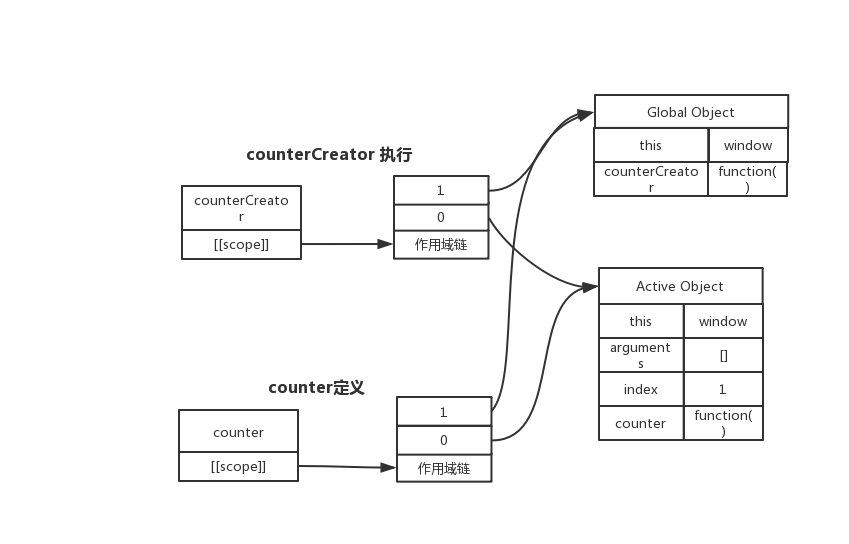
函数每次执行,都会生成一个会创建一个称为执行上下文的内部对象(AO对象,可理解为函数作用域),这个AO对象会保存这个函数中所有的变量值和该函数内部定义的函数的引用。函数每次执行时对应的执行上下文都是独一无二的,正常情况下函数执行完毕执行上下文就会被销毁。
作用域链
在函数定义的时候,他还获得[[scope]]。这个是里面包含该函数的作用域链,初始值为引用着上一层作用域链里面所有的作用域,后面执行的时候还会将AO对象添加进去 。作用域链就是执行上下文对象的集合,这个集合是链条状的。
function a () {
// (1)创建 a函数的AO对象:{ x: undfind, b: function(){...} , 作用域链上层:window的AO对象}
var x = 1;
function b () {
// (3)创建 b函数的AO对象:{ y: undfind , 作用域链上层:a函数AO对象}
var y = 2;
// (4)b函数的AO对象:{ y: 3 , 作用域链上层:a函数AO对象}
console.log(x, y); // 在 b函数的AO对象中没有找到x, 会到a函数AO对象中查找
}
//(2)此时 a函数的AO对象:{ x: 1, b: function(){...} , 作用域链上层:window的AO对象}
b();
}
a();
正常情况函数每次执行后AO对象都被销毁,且每次执行时都是生成新的AO对象。我们得出这个结论: 只要是这个函数每次调用的结果不一样,那么这个函数内部一定是使用了函数外部的变量。
垃圾回收
如何确定哪些内存需要回收,哪些内存不需要回收,这依赖于活对象这个概念。我们可以这样假定:一个对象为活对象当且仅当它被一个根对象 或另一个活对象指向。根对象永远是活对象。
function a () {
var x = 1;
function b () {
var y = 2;
// b函数执行完了,b函数AO被销毁,y 被回收
}
b();
//a 函数执行完了,a函数AO被销毁, x 和 b 都被回收
}
a();
// 这里是在全局下,window中的 a 直到页面关闭才被回收。
分析闭包结构
// 生成闭包的函数
function counterCreator() {
// 被返回函数所依赖的变量
var index = 1;
// 被返回的函数
function counter() {
return index ++;
}
return counter;
}
// 被赋值为闭包函数
var counterA = counterCreator();
// 使用
counterA();
闭包的创造函数必定包含两部分:
- 一些闭包函数执行时依赖的变量,每次执行闭包函数时都能访问和修改
- 返回的函数,这个函数中必定使用到上面所说的那些变量
// 被赋值的闭包函数
var counterA = counterCreator();
var counterB = counterCreator();
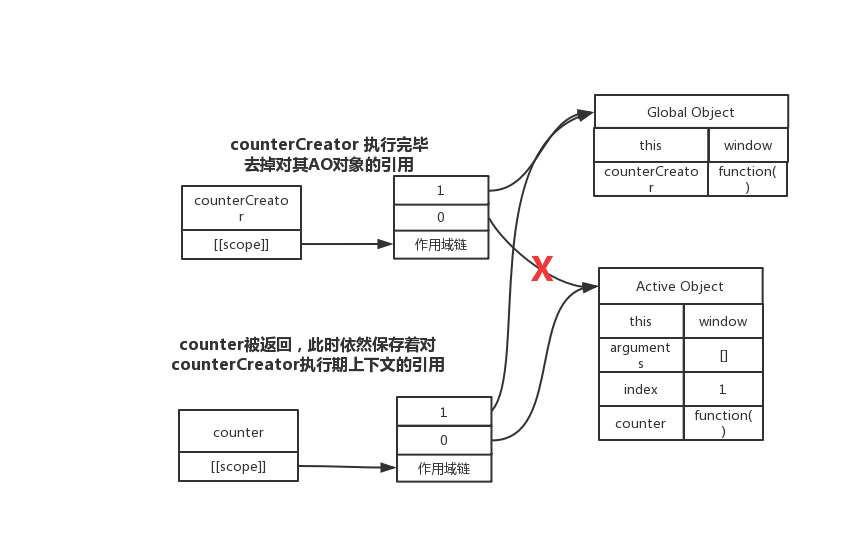
而上面这两句代码很重要,它其实是把闭包函数赋值给了一个变量,这个变量是一个活对象,这活对象引用了闭包函数,闭包函数又引用了AO对象,所以这个时候AO对象也是一个活对象。此时闭包函数的作用域链得以保存,不会被垃圾回收机制所回收。
当我们想重新创建一个新的计数器时,只需要重新再调用一次 counterCreator, 他会新生成了一个新的执行期上下文,所以counterB与counterA是互不干扰的。
counterCreator 执行
counterCreator 执行完毕,返回counter
总结
闭包的原理,就是把闭包函数的作用域链保存了下来。
使用闭包
带你手写一个简单的防抖函数,趁热打铁。
第一步,先把闭包的架子搭起来,因为我们已经分析了闭包生成函数内部一定有的两部分内容。
function debunce(func, timeout) {
// 闭包函数执行时依赖的变量,每次执行闭包函数时都能访问和修改
return function() {
// 这个函数最终会被赋值给一个变量
}
}
第二步: 把闭包第一次执行的情况写出来
function debunce(func, timeout) {
timeout = timeout || 300;
return function(...args) {
var _this = this;
setTimeout(function () {
func.apply(_this, args);
}, timeout);
}
}
第三步: 加上一些判断条件。就像我们最开始写计数器的index一样,不过这一次你不是把变量写在全局下,而是写在闭包生成器的内部。
function debunce(func, timeout) {
timeout = timeout || 300;
var timer = null; // 被闭包函数使用
return function(...args) {
var _this = this;
clearTimeout(timer); // 做一些逻辑让每次执行效果可不一致
timer = setTimeout(function () {
func.apply(_this, args);
}, timeout);
}
}
// 测试:
function log(...args) {
console.log('log: ', args);
}
var d_log = debunce(log, 1000);
d_log(1); // 预期:不输出
d_log(2); // 预期:1s后输出
setTimeout( function () {
d_log(3); // 预期:不输出
d_log(4); // 预期:1s后输出
}, 1500)
闭包运用
闭包用到的真的是太多了,再举几个例子再来巩固一下:
模块化
例NodeJS模块化原理:
NodeJS 会给每个文件包上这样一层函数,引入模块使用require,导出使用exports,而那些文件中定义的变量也将留在这个闭包中,不会污染到其他地方。
(funciton(exports, require, module, __filename, __dirname) {
/* 自己写的代码 */
})();
高阶函数
一些使用闭包的经典例子:
- 节流函数
- 柯里化(Currying)
- 组合(Composing)
- bind的实现
最后,如果你对闭包有更好的理解或者我文章里写的不好的地方,还请指教。