微博爬虫高级篇——自动获取微博cookie(无须账号、每日百万量级)
一、前言
事先说明,博主今年刚毕业,计算机应用技术,专科。没错,语文很差的那种。这是第一次干这种文章编辑,再加上年纪小,什么语法、错别字之类,前后语句不通顺啊什么的都无视吧。如果有什么问题可以找贴吧找我吧,我一般在java吧混,贴吧账号:ZSsanguosha
二、想说的话
现在市面有很多大数据或者做舆情分析的公司。这些公司难免都要用到爬虫,被爬得最多的,大概也是就微博了。虽然微博有自己的商业接口可以提供数据,但是里面有很多限制,比如:频次,字段缺失不满足需求。尤其 是频次,我之前的公司里就几个商业接口,大家共用,频次限制死死的,采集量大的时候完全用不过来。
所以,这时候就需要爬虫了,但是微博反爬机制是真的秀,所有内容都是FW.view()填充,动态cookie加密,验证码、封IP等等,尤其是搞了一个Sina Visitor System(新浪访客系统)。如果没有微博的cookie,爬虫取回来的页面全部变成Sina Visitor System了。微博cookie,必须登录后才能获取,而且你爬取过多,账号就会被冻结。
用cookie爬,容易被冻结账号,而且也实现不了自动化;不用cookie,就是Sina Visitor System页面,根本爬不到内容。博主这边就研究了如何跳过这个系统
三、致敬大佬
之前我接手公司某个需求,需要爬微博页面,数据量级大致在二千万左右。光用商业接口是根本来不及的。还好,有万能的搜索引擎告诉我有这么一篇文章
我很想放大佬原贴地址,但是有太多盗贴,分辨不了。原贴中具体的实现方式由于微博的更新,已经不可用了,但是还有一帮人盗贴,实在是看不下去, 所以,我打算发这篇博客纠正一下
四、基本原理
Sina Visitor System(新浪访客系统),在请求微博页面判断有没有微博cookie?有,就跳转,没有且不是爬虫,就创造一个游客cookie,以便访问。
博主用微博的“发现-找人-领域页”(https://d.weibo.com/1087030002_2975_2017_0)来举例,“1087030002_2975_2017_0”是这个页面的路径名,第一次是302重定向,然后经过一系列的请求跳转,最后变成200。

稍微比较一下两个“1087030002_2975_2017_0”请求的区别,请求头信息都差不多。最大的不同是,第一次请求是set-cookie,也就是没有cookie的值,第二次多了cookie,里面有三个值YF-Page-G0、SUB、SUBP。也就是说,这个cookie就是我们需要获取的游客cookie。
另外,以谷歌浏览器为例,想看到这些请求,先清空缓存(主要是cookie),F12打开开发者模式,在Network下面勾选 Preserve log,最后ctrl+R 重新加载


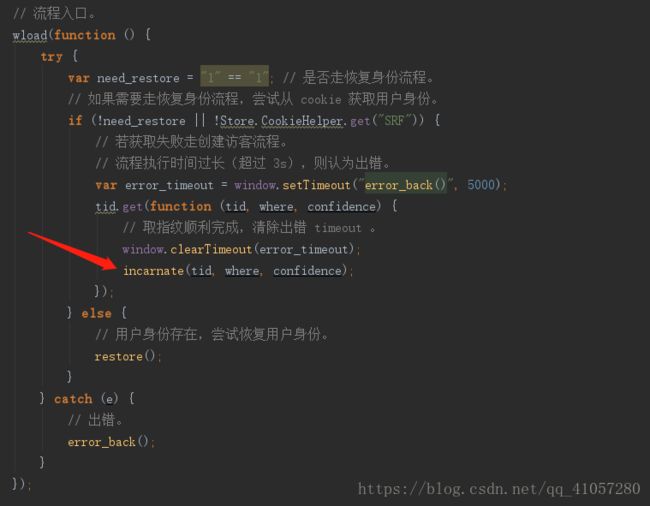
接下来,我们具体讨论下,他是怎么设置cookie的。先将第二个请求复制出来,在Postman中SEND一下。你会发现这个就是Sina Visitor System(新浪访客系统)。而且他还用中文注释,这是赤果果的挑衅(ノ`⊿´)ノ。另外它在body标签中,导入了一个js文件,也就是我们的第三个请求
![]()
我们一下看到,incarnate()方法是给用户赋予访客身份的。它发送了一个get请求,一对比,发现这是上面的第6个请求。也就是说,我们能成功发送第6个请求,就能成功获取cookie。
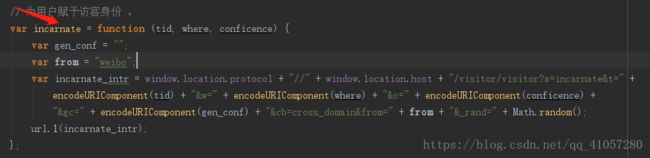
通过js我们可以知道,发送第6个请求,以下几个参数:
a、t、w、c、gc、cb、from、_rand。 其中a、cb、from是定值,_rand是随机数。
以下是第6个请求的详情,gc是空的,也就是说,我们只需要知道t(tid)、w(where)、c(conficence)三个参数就可以了
博主测试过,发送请求时gc填不填无所谓,一样能成功

这三个参数这里是没有,只能通过mini_original.js(第三个请求)去找。1984行的源码。上面有三个关键词,用tid一搜,就找到了。
如图:w(where) -> recover,看来w(where)在这里等价于recover

接下来,就是整理源码。往下翻一下,我们可以找到这个方法,这个明显就是获取tid的方法。跟Network里的请求比对一下,发现这就是第5个请求。
这是一个POST请求,传了两个值,一个是cp,定值为:gen_callback;另一个是fp,他是通过 getFp()方法生成,博主看了下,大致是获取浏览器类型,窗口大小,字体之类的常量。应该是为了判断是否为爬虫设置的。也就是说,只要不改浏览器配置,这些值不会变的。测试的时候,直接复制进去就可以了
为了方便截图,博主改变了js代码的部分位置,但具体实现是不变的


然后,我们用postman发送模拟请求 https://passport.weibo.com/visitor/genvisitor(第五个请求),他的返回值为
{
"retcode": 20000000,
"msg": "succ",
"data": {
"tid": "O8DdOkekzzLgrDM2e0HhvBRePB8ZVty6FeowFyc7IR0=",
"new_tid": true
}
}tid就找到了,只剩w(where)和c(conficence),我们继续看源码,发现他在后面回调的时候进行了处理。w(where) 在"new_tid"为true的时候是3,false的时候是2。
c(conficence) 可能有,可能没有,没有默认为100
虽然我这里没有,但是 data下面有几率出现一个叫 “conficence”的字段,我测试的时候他的值都是95

至此,我们找到了发送第6个请求(https://passport.weibo.com/visitor/visitor?a=incarnate&xxxxxxxx)的全部参数,模拟发下请求。得到结果。ok,sub和subp就全部得到。
window.cross_domain && cross_domain({
"retcode": 20000000,
"msg": "succ",
"data": {
"sub": "_2AkMsBM0Wf8NxqwJRmfgQzm_laoR-yg3EieKaWDzNJRMxHRl-yT83qn04tRB6B4Tj-ZvOcFzfsmjrLJjxv39RkzOyvMzE",
"subp": "0033WrSXqPxfM72-Ws9jqgMF55529P9D9Whhkx2zn2ycSbRz3ZvmBTfm"
}
});把这两个参数,加上最开始的YF-Page-G0,就可以得到完整的游客cookie。将这个cookie填入请求头,再次发起https://d.weibo.com/1087030002_2975_2017_0。完美成功
这里,博主测试的时候,cookie中不加入YF-Page-G0,无法获取到值。但大佬的文章表示不需要这个值。请自行斟酌;elipse的console是有输出限制,所以只能显示最后几行。另外,微博的页面内容都是用FM.view()填充的。
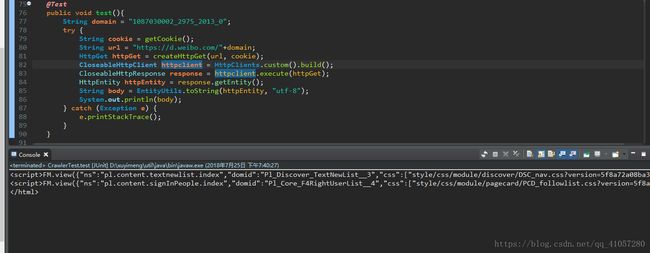

五、java实现
上面的实现是面向所有语言的,因此,上面并没有放代码。下面给大家放一个java的实现版本。博主会java,还有python。爬虫一般用Python比较合适,但这次选用java。没有什么理由,就是懒。java版本的之前完成需求的时候就已经写好了,ctrl cv 就够了。python还得从头开始写,太懒了~~
接下来的代码,都是从原有项目里拆分的,我稍微改造了下,有些冗余我就不优化了。不用照抄,有些实现完全就是无用 的
ok,第一步,maven依赖导入jar包。博主使用的连接工具用httpclient,解析html页面用jsoup,各位自行选用合适的就好。具体依赖如下
org.jsoup
jsoup
1.10.1
org.apache.httpcomponents
httpclient
4.5.5
第二步,连接工具类
博主这边加入了ssl校验、代理IP、cookie,一些连接配置,显得有些复杂了
/**
* @Title: generateClient
* @Description: TODO(增加代理)
* @param httpHost
* @return
* CloseableHttpClient 返回类型
*/
public static CloseableHttpClient generateClient(HttpHost httpHost,CookieStore cookieStore) {
SSLContext sslcontext = SSLContexts.createSystemDefault();
Registry socketFactoryRegistry = RegistryBuilder.create()
.register("http", PlainConnectionSocketFactory.INSTANCE)
.register("https", new SSLConnectionSocketFactory(sslcontext)).build();
// http连接池管理,服务于多个执行进程的连接请求
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager(
socketFactoryRegistry);
connectionManager.setMaxTotal(200);
connectionManager.setDefaultMaxPerRoute(20);
RequestConfig requestConfig = RequestConfig.custom().setProxy(httpHost).build();
HttpClientBuilder httpClientBuilder = HttpClients.custom().setUserAgent(randomUserAgent())
.setConnectionManager(connectionManager).setDefaultRequestConfig(requestConfig).setDefaultCookieStore(cookieStore);
return httpClientBuilder.build();
} 第三步,获取t、w、c三个参数的值
private JSONObject getTidAndC() throws IOException
{
String url = "https://passport.weibo.com/visitor/genvisitor";
HttpPost httpPost = createHttpPost(url);
CloseableHttpResponse response = httpclient.execute(httpPost);
HttpEntity entity = response.getEntity();
if (entity != null) {
//按指定编码转换结果实体为String类型
String body = EntityUtils.toString(entity, "utf-8");
body = body.replaceAll("window.gen_callback && gen_callback\\(", "");
body = body.replaceAll("\\);", "");
JSONObject json = JSONObject.fromObject(body).getJSONObject("data");
System.out.println(body);
return json;
}
return null;
}第四步获取cookie
public String getCookie() throws IOException {
JSONObject json = getTidAndC();
String t = "";
String w = "";
String c = json.containsKey("confidence") ? json.getString("confidence") : "100";
if (json.containsKey("new_tid"))
{
w = json.getBoolean("new_tid") ? "3" : "2";
}
if (json.containsKey("tid"))
{
t = json.getString("tid");
}
System.out.println(c);
String url = "https://passport.weibo.com/visitor/visitor?a=incarnate&t="+t+"&w="+w+"&c=0"+c+"&gc=&cb=cross_domain&from=weibo&_rand="+Math.random();
HttpGet httpGet = createCookieGet(url, "tid="+t+"__"+c);
CloseableHttpResponse response = httpclient.execute(httpGet);
HttpEntity httpEntity = response.getEntity();
String body = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(body);
body = body.replaceAll("window.cross_domain && cross_domain\\(", "");
body = body.replaceAll("\\);", "");
JSONObject obj = JSONObject.fromObject(body).getJSONObject("data");
System.out.println(obj.toString());
String cookie = "YF-Page-G0="+getYF()+"; SUB="+obj.getString("sub")+"; SUBP="+obj.getString("subp");
System.out.println("cookie: "+cookie);
httpclient.close();
return cookie;
}YF-Page-G0 的参数,通过发送请求,获取set_cookie的值得到的。这样就获得完整的游客cookie,
应该是把url加入参数列表比较合理,值也不应该写死
public String getYF() throws IOException {
String domain = "1087030002_2975_5012_0";
String url = "https://d.weibo.com/"+domain;
HttpGet httpGet = createHttpGet(url, null);
CloseableHttpResponse response = httpclient.execute(httpGet);
List cookies = cookieStore.getCookies();
String str = "";
for (Cookie cookie : cookies)
{
str = cookie.getValue();
}
return str;
} 最后,就是调用了。
只要调用getCookie(),就能获取完整的游客cookie。然后,就能获取页面数据
我想你们已经发现了,这几个方法都是博主以前做测试留下的测试文件,实在懒得改就随意了。下列代码的运行结果,上面已经发了,就不再发了。
@Test
public void test(){
String domain = "1087030002_2975_2013_0";
try {
//获取cookie
String cookie = getCookie();
//将cookie传入请求头,生成get请求
String url = "https://d.weibo.com/"+domain;
HttpGet httpGet = createHttpGet(url, cookie);
//获取响应结果,输出
CloseableHttpClient httpclient = HttpClients.custom().build();
CloseableHttpResponse response = httpclient.execute(httpGet);
HttpEntity httpEntity = response.getEntity();
String body = EntityUtils.toString(httpEntity, "utf-8");
//html
System.out.println(body);
} catch (Exception e) {
e.printStackTrace();
}
}六、注意事项
微博的大部分页面都可以用这个方法爬到,搜索和评论没办法拿到全部数据。上限好像是20页?
该方法极其容易被封ip,大规模使用时必须要设置代理ip
同一个ip,获取cookie,每5次 可能会失败一次,自行做好判断
截止 2019年10月14日17点32分32秒,方法并未失效,之后我就不知道了
七、多线程自动化微博爬虫
这个具体实现代码不能说太多,公司项目已经上线,保密协议生效中,博主也就不给自己找麻烦。大抵的思路,就是设置多个线程,提供不同的代理ip,做个错误提醒,异常处理,设置合理的频次让IP存活更久之类的常规操作。
博主曾经开过8个线程,一天大致能爬200w左右的数据量。以后可能会发几篇微博爬虫的基本操作,这方面的话,等什么时候保密协议过了,再继续更新吧
八、结尾
转贴,留个全尸就可以了,标明出处和作者,,其余随意
有什么问题可以联系我,或者有什么错误。欢迎斧正。最后,csdn不一定能联系到我,楼主一般出没在java吧,贴吧ID:ZSsanguosha。