Hadoop生态圈重要组件整理
Hadoop生态圈重要组件的概论与简述
初学hadoop的朋友们一定知道,Hadoop是由Apache开发的分布式系统基础架构,类似于自然界中的生态系统。这个系统中包含多个组件,共同完成分布式框架处理的任务。这里为大家整理了如下:
HDFS:分布式文件系统
Yarn:资源调度系统
MapReduce:分布式运算程序开发框架
HIVE:SQL数据仓库工具
HBASE:基于Hadoop的分布式海量数据库
Zookeeper:分布式协调服务基础组件
另外还有
Sqoop:数据迁移工具
Flume:日志数据采集框架
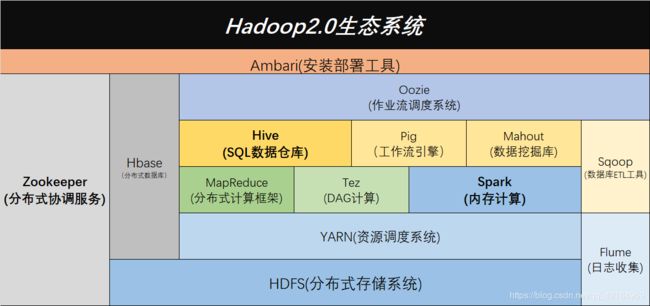
下面是这些组件的简述:
1. HDFS
HDFS(Hadoop分布式文件系统)被设计为一个适合运行在通用硬件上的分布式文件系统,和其他的分布式文件系统有着很多共同点,但比之还是有诸多优点。
(1)HDFS是一个高度容错性的系统,适合部署在廉价的机器上。
(2)HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
(3)HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
作为一个主从结构,HDFS主要含有NameNode(老大)、DataNode(小弟)、SecondaryNameNode(助理)节点。以下是关于节点的主要底层原理:
(1)NameNode是HDFS的管理节点,负责DataNode的管理和元数据管理(元数据即hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置);
SecondaryNameNode是NameNode的一个助理,帮助NameNode管理元数据,防止元数据丢失;
(2)NameNode记录整个文件的数据信息(数据块数量、长度、分别在哪个DataNode上),存在内存中,也会定期将元数据序列化到磁盘上。
(3)Namenode元数据存在内存hdpdata下(定期序列化到磁盘上 ,并将更新元数据的信息记录在fsimage文件中)。
元数据实时更新,磁盘文件通过edits日志文件记录操作 (引起元数据变化的客户端操作)。
DataNode负责数据存储。
(4)DataNode存储数据块时是存储在服务器的本地磁盘中,每个DataNode存储多个、不同副本以防数据块丢失。
(5)DataNode上还会有一个.meta文件,用于校验数据块,如果遭遇非法恶意更改,可以保证恢复原始数据块的准确性。
(6)SecondaryNamenode会定期从Namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合)。整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给Namenode.
(SecondaryNamenode 复制Namenode的镜像,把fsimage和edits定期下载到磁盘,加载并反序列化到内存元数据对象。读日志文件,更新元数据,并定期上传合并到namenode上(比如一个小时合并一次)。
上述称为checkpoint机制。

关于Checkpoint,多说几句:
类似于Snapshot——对数据备份,Hadoop中的Checkpoint机制主要用于对NameNode
元数据的持久化。
NameNode上主要包含两个文件——edit和fsimage;
edit:HDFS操作的日志记录,每当修改HDFS,就会记录一条日志;
fsimage:存放HDFS中命名空间、数据块分布、文件属性等信息,相当于元数据的镜像文件。
fsimage只有在HDFS每次启动时将edit记录的操作向自己增加更新一次,并清空edit;
fsimage总是记录NameNode启动时的状态,edit每次启动后为空,只记录本次启动后的操作日志。
###Why Checkpoint?
1.在一次启动后,edit可能会增加很长,下次启动NameNode时会耗费很长时间;
2.NameNode发生故障,edit会丢失。
Checkpoint触发的两种时机——时间和空间,对应两个参数
时间,fs.checkpoint.period,设置两次Checkpoint的时间间隔,默认1小时;
空间,fs.checkpoint.size,设置edit文件的大小阈值,达到该值后强制执行Checkpoint,即使此时没有到period时间。默认大小64MB.
###Checkpoint过程
**Chekpoint主要干的事情是,**将Namenode中的edits和fsimage文件拷贝到Second Namenode上,然后将edits中的操作与fsimage文件merge以后形成一个新的fsimage,这样不仅完成了对现有Namenode数据的备份,而且还产生了持久化操作的fsimage。最后一步,Second Namenode需要把merge后的fsimage文件upload到Namenode上面,完成Namenode中fsimage的更新。
以上提到的文件都可以在hadoop系统的data目录下找到。
###关于Checkpoint导入:
当Namenode发生故障丢失元数据后,可以利用Second Namenode进行导入恢复,过程如下:
在Namenode的节点上面创建dfs.name.dir指定的目录;
指定配置文件中的 fs.checkpoint.dir(应该是hdfs-site.xml文件);
启动Namenode时带上选项 -importCheckpoint。
Namenode首先会将fs.checkpoint.dir中的文件拷贝到dfs.name.dir中,如果此时dfs.name.dir中已经包含了合法的fsimage文件(也就是Namenode没有发生元数据丢失却执行了导入操作),那么Namenode就会执行失败。否则,Namenode会检测导入的fsimage文件是否与文件系统中的数据一致,若一致则成功完成导入恢复。
HDFS的另一种数据备份方式Recovery只在本地存储元数据备份,避免文件损坏的影响,但对于节点故障来说没用,有一定局限性。
另外,关于hdfs的配置信息,本地文件上传至hdfs时,副本数、block大小等配置信息先读取hdfs-default.xml,再读取hdfs-site.xml,之后再读取用户代码中创建的对象configuration中的参数信息。如果在命令行中操作,需要调整配置信息,则要更改hdfs-site.xml。
hdfs不同进程的配置参数不一样,写在同一个文件中,但某个Datanode中更改参数后不会影响服务器的整体配置信息。
2. Yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统。
关于Yarn,这里不做过多赘述,只需要将Yarn上的两大核心角色,即两个"manager"的工作原理进行理解即可。
ResourceManager(老大)NodeManager(小组长)——创建容器,运行程序。
ResourceManager是YARN的管理节点,负责NodeManager的管理、任务调度等。接受用户提交的分布式计算程序,并为其划分资源。管理、监控各个NodeManager上的资源情况,以便于均衡负载。
NodeManager是YARN的节点管理器,负责向ResourceManager汇报当前节点的状态和启动计算任务进程(YarnChild)并监控YarnChild。管理它所在机器的运算资源(cpu + 内存)。负责接受Resource Manager分配的任务,创建容器、回收资源。
3. MapReduce
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架。
Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上。
Mapreduce作为一个编程框架,可根据实际需要实现不同功能。每个MapReduce都由两个阶段组成,即Map阶段和Reduce阶段。
Map阶段 --程序Maptask
需要几个maptask就启动几个maptask,一般每个数据切片为128M,a.txt(200M),b.txt(300M),就启4个maptask。
Maptask每读一行处理一次,怎样处理没有写死,交由用户编写。(某父类的子类、接口的实现类)
Reduce阶段 --程序Reducetask
每个maptask运行完会产生大量kv,交由reducetask处理,把相同key的kv数据给一个reducetask,可以把多种key给一个reducetask。(即shuffle)
两个阶段需要做的工作:
map阶段:对maptask读到的一行数据如何处理
reduce阶段:对reducetask拿到的一组相同key的kv数据如何处理。
两者间传递数据只要写到contex中即可。
PS:hadoop中的序列化接口是writable
作为最常见也最简单的MapReduce,这里将Wordcount程序的整体运行流程做一下简要总结:

map阶段: 将每一行文本数据变成<单词,1>这样的kv数据;
reduce阶段:将相同单词的一组kv数据进行聚合:累加所有的v。
另外,关于shuffle过程的优化
最常见的方式即是combiner合并,
在map阶段提前进行了一次合并,等同于提前执行了一次reduce操作,可以降低reduce的压力。
在map阶段的进行合并是 并行的(分布式的)。
job.setCombinerClass(WordCountReducer.class);
注意:并不是所有的程序都适合combiner:测试
设置combiner之和 和之后的结果要一致,不能因为性能优化导致结果不对
A + (B +C) = (A+B) + C
最后,MapReduce的四大组件:
Mapper、Reducer、Partitioner、Combiner
4. Hive
Hive是基于Hadoop的一个数据仓库,可以将结构化的数据文件映射为一张表,并提供类sql查询功能,Hive底层将sql语句转化为mapreduce任务运行。相对于用java代码编写mapreduce来说,Hive的优势明显:快速开发,人员成本低,可扩展性(自由扩展集群规模),延展性(支持自定义函数)。
简单来说,Hive的工作流程即是:
将数据映射成mysql表,解析sql语法,组装一个job(MapReduce或Spark),提交job到yarn上运行。
hadoop为Hive提供了客户端和服务端的接口,客户端有简单的交互界面,在客户端上执行命令排版较为整齐。
hive服务端:hiveserver2,bin/hiveserver2开启。默认端口号为10000。
hive客户端:beeline,同上开启,进入交互命令行连接服务端。
!connect jdbc:hive2://主机名:10000。
另外,关于Hive数据导入:本地文件导入表示复制操作,源文件保留;hdfs文件导入表是移动操作。
5. HBase(&Zookeeper)
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。
关于HBase,核心内容有以下四点:
1.分布式的,可扩展的,大数据存储的hadoop数据库。
2.当需要实时读写时,会提供百亿行*百亿列规模的数据库。
3.开源的,多版本的结构化数据库模型。
4.来源于谷歌三论文 HDFS,MapReduce,Bigtable
HBase有2个主要的进程。
和hdfs节点服务(Datanode、Namenode)类似,HBase内部有RegionServer和Master外部依赖于hdfs和zookeeper。
安装部署首先安装hdfs和zookeeper服务,再安装HBase内部服务。
RegionServer同Datanode一样,管理数据。每一个Region管理一个区的数据。
RegionServer会把自己的信息报告给Master,包括工作情况和健康状态。
每个Region done掉之后,Master会把其中数据调到其他Region中管理。
ZookKeeper得到的报告情况和Master是一样的。
在实际应用中,如果启用ZookKeeper,Master可以直接通过它管理RegionServer。
关于Zookeeper
分布式应用程序协调服务
1.可以为客户端管理少量数据kv
2.可以为客户端监听指定数据节点的状态并在数据节点发生变化时,通知客户端。
场景:服务器上下线动态感知;配置文件同步管理