分类变量的深度嵌入(Cat2Vec)

本文为 AI 研习社编译的技术博客,原标题 :
Deep embedding’s for categorical variables (Cat2Vec)
作者 | Prajwal Shreyas
翻译 | JoccKouisFung 编辑 | 酱番梨、Pita
原文链接:
https://towardsdatascience.com/deep-embeddings-for-categorical-variables-cat2vec-b05c8ab63ac0
在这篇博客中,我将会向你介绍如何在keras的基础上,使用深度学习网络为分类变量创建嵌入。这一概念最初由Jeremy Howard在他的fastai课程上提出。更多详情请查看链接。
传统嵌入
对于大多数我们处理的数据源变量,主要分为两种:
- 连续变量:这种变量通常是整数或十进制数字,它们都有无限个可能的值。例如计算机的内存单元(即1GB,2GB等等)。
- 分类变量:根据一定的特征,这些离散的变量可以对数据进行分类。例如计算机内存的种类(即RAM内存、内置硬盘和外置硬盘等等)。
当我们在建立一个机器学习模型的时候,大多数情况下,我们要做的不仅仅只是对分类变量进行变换并应用到算法中。变换的使用对于模型性能有着很大的影响,尤其是当数据拥有大量高基数的分类特征时。一些常见的转换例子包括:
One-hot编码:我们把每一个分类的值,转换成一个纵列,然后为这个纵列中的值分配0或1。
二元编码:通过在列中保留一些特殊值,这种方式比one-hot编码创建更少的特征。它在高维正交数据中所表现出的性能比one-hot更好。
然而这些常见的转换方式并不能体现出分类变量之间的联系。请浏览以下链接以获取更多不同编码方式的信息。
数据
我们以Kaggle上面的共享自行车数据作为例子来展示一下深度嵌入的应用。同样地,链接在这里。

自行车共享数据
正如我们所看到,数据表格中有很多纵列。我们只用到date_dt, cnt和mnth来辅助我们说明这一概念。
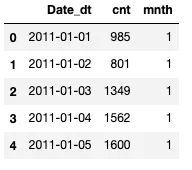
选定的列
使用传统的one-hot编码会生成12列数据,每个月一列。但是这种嵌入方式,对于每个星期的每一天都给予了相同的重视程度,并且这种嵌入下,每个月的数据之间并没有联系。
每个月的一列编码
我们可以从下图中观察到每个月其数据的季节性特征。4到9月是高峰月,而0,1,10,11是自行车呈现低需求的月份。
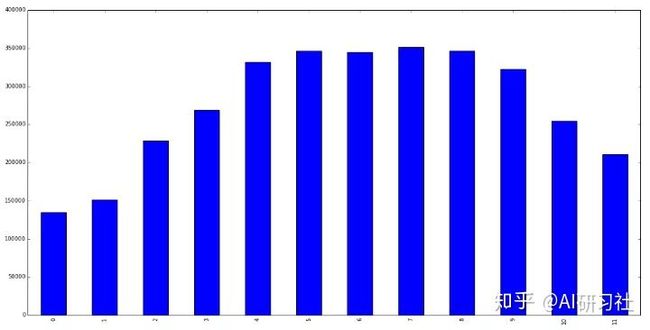
每月季节性
另外,当我们用不同颜色描绘出各个月份中,自行车每日的使用情况时,我们又发现了每个月里各个星期的特征。
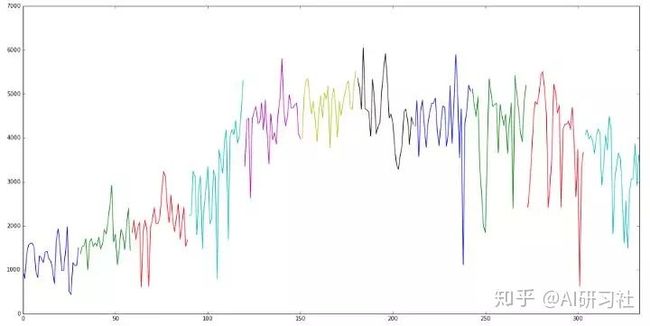
每月使用趋势
理想状况下,我们都希望使用嵌入来捕捉到这些关系。在下一节我们将会测试一下这类基于keras建立的深度网络所产生的嵌入结果。
深度编码
代码如下所示。我们用密集的层与“relu”激活函数,建立起感知网络。
网络的输入即变量x,表示月份的数字。由于这是一年里各个月份的数字化表示,并且它们是从0到11的数字。因此输入维度input-dim设为12。
网络的输出即变量y,是cnt缩小比例的列。但是y可以被扩展,以包括其它连续变量。由于我们使用到单一的连续变量,所以输出层的最后一个数字设为1。我们用这个模型训练迭代50次。
embedding_size = 3
model = models.Sequential()
model.add(Embedding(input_dim = 12, output_dim = embedding_size, input_length = 1, name="embedding"))
model.add(Flatten())
model.add(Dense(50, activation="relu"))
model.add(Dense(15, activation="relu"))
model.add(Dense(1))
model.compile(loss = "mse", optimizer = "adam", metrics=["accuracy"])
model.fit(x = data_small_df['mnth'].as_matrix(), y=data_small_df['cnt_Scaled'].as_matrix() , epochs = 50, batch_size = 4)网络参数

模型摘要
嵌入层:对于分类变量,我们对于嵌入层的大小进行分类。在本次实验中我设为了3,如果我们增加其大小,它将会捕捉到分类变量之间关系的更多细节。Jeremy Howard建议的嵌入大小如下所示:
# m is the no of categories per feature
embedding_size = max(50, m+1/ 2)我们使用到亚当优化算法配合均方错误损失函数。由于亚当优化算法速度其学习率的适应性,其比随机梯度下降算法更受欢迎。你可以通过原文找到不同优化算法的详情。
结果
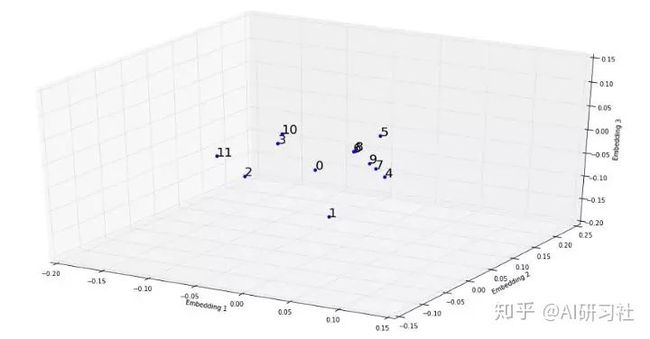
每个月最终的侵入结果如下所示。其中0表示一月,1表示十二月。
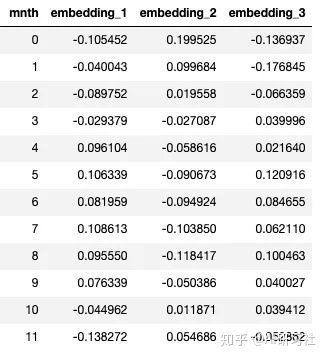
使用3D图像模拟这些数据时,我们可以看见月份之间清晰的联系。相似cnt下的月份被分类至更近。例如,4月和9月之间很相似。
总结
总的来说,我们可以看到,在使用Cat2Vec后,我们可以用低纬度嵌入表示高基数的分类变量的同时,也保留了每个分类之间的联系。
在下一篇博客中,我们将会探索,如何使用这些嵌入去建立拥有更好性能的监督和无监督机器学习模型。
想要继续查看该篇文章相关链接和参考文献?
点击【分类变量的深度嵌入(Cat2Vec) 】即可访问:
社长今日推荐:AI入门、大数据、机器学习免费教程
35本世界顶级原本教程限时开放,这类书单由知名数据科学网站 KDnuggets 的副主编,同时也是资深的数据科学家、深度学习技术爱好者的Matthew Mayo推荐,他在机器学习和数据科学领域具有丰富的科研和从业经验。
点击链接即可获取:AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。