NLP系列 2.特征提取
1. 基本文本处理技能
1.1 中英文字符串处理
1.1.1 删除不相关的字符
去除字符串两端字符串:
s=' ,,,abc,,, '
print(s.strip())# 删除两边空字符
print(s.lstrip())# 删除左边空字符
print(s.rstrip())# 删除右边空字符
print(s.strip().strip(','))# 删除指定字符
,,,abc,,,
,,,abc,,,
,,,abc,,,
abc
replace替换
s1='123abc456'
print(s1.replace('123',''))
正则表达式去除字符
import re
s2='123abc456'
print(re.sub('\d+','.',s2))
正则表达式的用法可以参考 https://www.liaoxuefeng.com/wiki/1016959663602400/1017639890281664
常用辅助网站
https://regex101.com
1.1.2 去除停用词
之前写爬虫做词云用到过停用词.
停用词在主要指一些常用的虚词, 出现频率高, 但是又没有实际意义, 所以在许多进行文本分析的场景下需要去掉.
常与jieba分词共同使用.
这一部分不多叙述, 参见下面分词部分.
1.2 分词
jieba分词是一个常用的开源分词工具. 官方链接: https://github.com/fxsjy/jieba
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;cut_all=False
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;cut_all=True
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。jieba.cut_for_search()
1.2.1 安装
pip install jieba
1.2.2 简单使用
import jieba
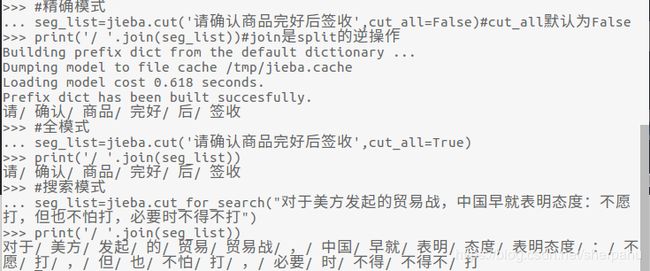
#精确模式
seg_list=jieba.cut('请确认商品完好后签收',cut_all=False)#cut_all默认为False
print('/ '.join(seg_list))#join是split的逆操作
#全模式
seg_list=jieba.cut('请确认商品完好后签收',cut_all=True)
print('/ '.join(seg_list))
#搜索模式
seg_list=jieba.cut_for_search("对于美方发起的贸易战,中国早就表明态度:不愿打,但也不怕打,必要时不得不打")
print('/ '.join(seg_list))
在这里我犯了一个很智障的错误, 不能把python文件命名为jieba, https://github.com/fxsjy/jieba/issues/219
1.2.3 停用词
import jieba
# jieba.load_userdict('userdict.txt')
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('stopwords.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
inputs = open('cnews.val.txt', 'r', encoding='utf-8')
outputs = open('output.txt', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close()
这里用上次的THUCNews中的cnews.val.txt作为输出数据, stopwords.txt是我大一的时候做爬虫时下载的, 已经不知道出处了.
这两个文件都放在当前目录下, 运行得如下结果.

原本的cnews.val.txt如下:

对比可以发现"中","对于"这些虚词已经被去掉了.
1.3 词、字符频率统计
1.3.1 最简单的方法
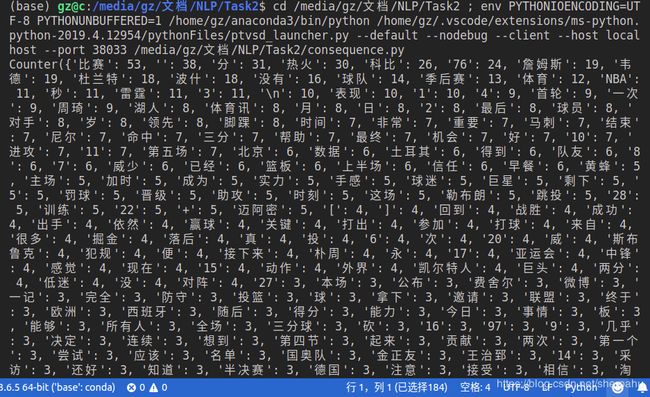
import collections
import os
f=open('output.txt',"r")
news=[]
for i in range(10):
string=f.readline()
string=string.split(' ')
news+=string
print(collections.Counter(news))
结果如下:
利用jieba分词进行关键词提取
jieba实现了TF-IDF和TextRank这两种关键词提取算法, 这里也会使用到jieba自带的前缀词典和IDF权重词典。
import jieba.analyse
import os
f=open('output.txt',"r")
news=''
for i in range(10):
string=f.readline()
news+=string
# 第一个参数:待提取关键词的文本
# 第二个参数:返回关键词的数量,重要性从高到低排序
# 第三个参数:是否同时返回每个关键词的权重
# 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
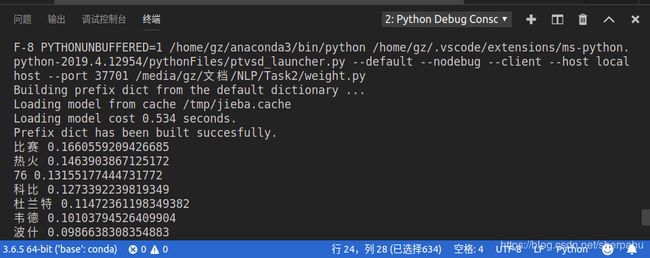
keywords = jieba.analyse.extract_tags(news, topK=20, withWeight=True, allowPOS=())
# 访问提取结果
for item in keywords:
# 分别为关键词和相应的权重
print(item[0], item[1])
# 同样是四个参数,但allowPOS默认为('ns', 'n', 'vn', 'v')
# 即仅提取地名、名词、动名词、动词
keywords = jieba.analyse.textrank(news, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))
# 访问提取结果
for item in keywords:
# 分别为关键词和相应的权重
print(item[0], item[1])
结果如下:
2. 语言模型
2.1 定义
统计语言模型是一个单词序列上的概率分布,对于一个给定长度为m的序列,它可以为整个序列产生一个概率 P(w_1,w_2,…,w_m) 。其实就是想办法找到一个概率分布,它可以表示任意一个句子或序列出现的概率。
下面介绍一下n-gram模型方法.
2.2 n-gram模型
n-gram模型:unigram、bigram、trigram
为了解决自由参数数目过多的问题,引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的n个词有关。基于上述假设的统计语言模型被称为N-gram语言模型。
当n取1、2、3时,n-gram模型分别称为unigram、bigram、trigram语言模型
- unigram 一元分词,把句子分成一个一个的汉字
- bigram 二元分词,把句子从头到尾每两个字组成一个词语,也叫一阶马尔科夫链
- trigram 三元分词,把句子从头到尾每三个字组成一个词语,也叫二阶马尔科夫链
转自 https://blog.csdn.net/u012736685/article/details/88206485
这部分我目前还不是很懂, 这几天加深一下理解再补充.
3. 参考链接
https://blog.csdn.net/u012052268/article/details/77825981#python_0
https://github.com/fxsjy/jieba
https://zhuanlan.zhihu.com/p/52061158
https://blog.csdn.net/u012736685/article/details/88206485