独家 | 一文读懂LinkedIn个性化推荐模型及建模原理

原文标题:HowLinkedIn Makes Personalized Recommendations via Photon-ML Machine Learning tool
作者:Yiming Ma, Deepak Agarwal
翻译:张媛
校对:丁楠雅
本文长度为2500字,建议阅读8分钟
本文将重点关注个性化推荐模型,并解释建模原理以及如何通过Photon-ML来实现,使其能够惠及数亿用户。
简介
推荐系统是一种自动化的计算机应用程序,它可以根据不同的内容对用户进行匹配。这种系统的应用很普遍,并且已经成为我们日常生活中不可缺少的一部分。常见的例子像亚马逊给用户推荐产品,雅虎给访问网站的用户推荐内容,Netflix给用户推荐电影,LinkedIn给用户推荐工作等等。考虑到用户偏好存在明显的差异性,提供个性化推荐就成为这种系统成功的关键。
为了实现这个目标,通过机器学习模型从收集的反馈信息中估计用户偏好至关重要。这些模型是基于用户历史交互信息中获取的大量高频数据而构建的。本质上它们都是统计模型,需要克服序列决策过程、高维数据的交互建模,开发可伸缩的统计方法等诸多困难。在这个领域,新方法论的诞生需要各方面的紧密合作,包括计算机科学家、机器学习专家、统计学家、优化专家、系统专家、以及领域专家。这是大数据行业最令人兴奋的应用之一。

LinkedIn的许多产品都应用了推荐系统,这些系统的核心组件是一个灵活的机器学习库,叫Photon-ML,这是提升我们的生产力、敏捷性以及开发人员幸福感的关键。目前我们已经开源了Photon-ML使用的大部分算法。 在本文中,我们将重点关注个性化推荐模型,并解释建模原理以及如何通过Photon–ML来实现,使其惠及数亿用户。
Photon-ML的个性化模型构建
LinkedIn通过应用Photon-ML,显著提升了许多产品的用户参与度和业务指标。下面举例说明如何使用广义可加混合效应模型(GAME)进行个性化的工作推荐。在我们的在线对照实验中,该模型为求职者提供了比平时高出20%~40%的工作申请机会。
作为全球最大的职业社交网络,LinkedIn为其5亿多的用户提供了一个独特的价值定位,为他们的职业发展提供了各种各样的机会。我们提供的最重要的产品之一是“求职主页”,它是那些想要申请一份好工作的用户的服务中心。
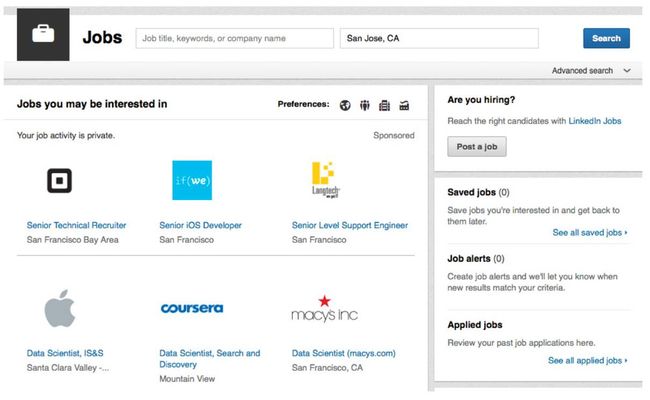
图1 LinkedIn求职主页的快照
图1页面的一个主要功能模块是“您可能感兴趣的工作”,这个页面会根据用户的公开资料和历史活动记录向他们推荐相关的工作简介。如果用户对推荐的工作感兴趣,他/她可以点击进入工作详情页面,进一步了解这个工作的职位、描述、职责、要求的技能和任职资格。工作详情页面也会提供“申请”按钮,可以让用户通过LinkedIn或者公司的招聘网站一键申请到这个工作。LinkedIn业务成功的关键指标之一就是工作申请的点击总量(即“申请”按钮的点击次数)。
我们模型的目标是准确预测一个用户申请系统推荐工作的概率。直观地来说,该模型由三个组件/子模型组成:
一个全局模型,用来捕获用户申请工作的常规行为;
一个特定用户模型,其参数(从数据中学习获得)针对特定用户,以捕获其偏离常规行为的个人行为;
一个特定职业模型,其参数(从数据中学习获得)针对特定职业,以捕获其偏离常规工作的独特行为。
与很多推荐系统应用程序一样,我们在大量的用户或者职业数据中观察到许多差异性。在求职网站上既有新用户加入(因此几乎没有相关数据),也有那些拥有很强求职意向并在过去多次申请工作的用户。同样的,对比不同类型的工作,既有受欢迎的,也有比较冷门的。对于拥有很多工作申请数据的用户,我们希望应用特定用户模型来计算,另一方面,如果用户没有很多历史数据,我们会选择全局模型来捕获用户常规行为。
接下来让我们深入研究一下这个广义可加混合效应模型(GAME)是如何基于上述情况实现个性化推荐的。
首先,用 ymjt 表示用户m在上下文t的条件下是否申请工作j的二进制结果,其中上下文内容通常包括工作时间和位置。我们用qm表示用户m的特征向量,其中包括从用户公开的资料中得到的特征信息,例如用户的工作岗位、工作职能、教育背景、所属行业等。我们用sj表示工作j的特征向量,其中包括工作的特征信息,例如职位名称、所需技能和工作经验等。
然后用xmjt表示三维变量(m, j, t)的整体特征向量,包括qm和sj特征的主要影响,qm和sj的外积用来表示用户、工作特征以及上下文的特征。其中xmjt不包含用户ID和项目ID,这些ID将会受到与常规特性不同的处理方法。利用逻辑回归法预测用户m申请工作j的可能性的GAME模型如下:
![]()
其中
![]()
是关联函数,b是全局系数向量(在统计学文献中也叫固定效应系数),αm和βj是特定于用户m和工作j的系数向量,也叫随机效应系数,用来表示用户m在不同项目上的偏好和工作j对不同用户的吸引力。对于一个在过去申请很多职位的用户,我们能够准确地估计他/她的个人系数向量αm并提供个性化的预测。另一方面,如果用户m过去没有申请记录,αm的后验平均值将会接近0,针对用户m的模型将会退回到全局固定效应x'mjtb,同样的道理也适用于工作系数向量βj。
Photon-ML:构建个性化推荐模型的可伸缩平台
为了在 Hadoop集群上使用大量数据对模型进行训练,我们在Apache Spark上层开发了Photon-ML。设计可伸缩算法的一个主要挑战是要从数据中学习海量的模型参数(例如数百亿),如果我们简单地利用标准机器学习方法来训练模型(比如 Spark 提供的 MLlib),那么更新大量参数带来的网络通信成本太高,在实际计算中不可行。其中大量参数主要来自于特定用户模型和特定职业模型,因此,使算法具有可伸缩性的关键是避免在上述模型中向集群传送或广播大量参数。
我们使用并行块坐标下降法(PBCD)来解决大规模的模型训练问题,在这个方法中,通过迭代法训练全局模型、特定用户模型以及特定职位模型最终达到收敛的状态。其中使用标准分布式梯度下降法对全局模型进行训练,对于特定用户模型和特定职业模型,我们设计了一个模型参数更新方案,这样上述模型中的参数不需要通过集群里的机器进行通信。但是,每个训练示例的部分评分是通过机器之间的通信完成的,这样大大降低了通信成本。同时PBCD也可以很容易地应用到拥有不同类型子模型的模型中。
结论和展望未来
在本文中,我们简要介绍了怎样使用 Photon-ML来实现个性化推荐,由于篇幅限制,很多有趣的优化和实施细节都被省略了,在此强烈推荐读者去查看Photon-ML开源源码。在LinkedIn, 我们致力于构建最先进的推荐系统,并且也为 Photon-ML制订了令人兴奋的计划,在不久的将来,我们计划在 Photon-ML中增加更多的建模功能,包括树状模型和不同的深度学习算法来构建非线性和更深层次的表示结构。
原文地址:
https://www.kdnuggets.com/2017/10/linkedin-personalized-recommendations-photon-ml.html
编辑:黄继彦

张媛,某云计算公司不务正业服务工程师一枚。喜欢下雨天,读闲书,缺乏技术细胞,欣赏并喜欢有态度有立场的人,爱浪漫,注重仪式感,喜欢记录。最近的愿望是拥有自己的小窝,给想念的人写一封信。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

点击“阅读原文”加入组织~