网络经济的发展使我们的消费渠道早已不止于实体场景。来自于用户的线上评价,成为如今影响我们消费行为决策的重要因素。
背景
在网上购物时,即使你已经浏览了商家对于商品的描述,你还是不会立即决定购买它,因为你不确定这些描述是否准确。这时你会寻找其他购买过此商品的用户评论,这些评论可能才会最终说服你。
购买旅行类产品也是一样。每天都有大量用户在马蜂窝平台用“评论”的方式,记录和评价他们在旅行中的感受和体验。而基于对评论内容深度挖掘产生的标签,则用一种更为简洁、直观的方式汇总评论信息中的重要内容,展示给更多的用户作为参考依据。
因此,如何在保证标签内容准确性的同时,体现出更符合用户语言习惯、让用户更容易理解的标签含义,对于提升用户在马蜂窝平台的体验,做出更符合自身需求的旅行决策,以及提升平台转化率、更好地监管商家服务品质等方面,都有很大价值。
从评价中提取标签的方式有很多,但在实际应用中存在一些问题,比如:
1. 预设标签
-
做法:预先定义好一些固定标签,由用户在发表点评时自主选择。
-
不足:固定标签数量受限,无法覆盖用户全部需求,并且标签和用户内容可能不匹配。
2. 句法分析
-
做法:对用户发布的点评内容进行解构,提取主题词和描述词组合后作为标签。
-
不足:在评价量非常大的时候,这种方法会产生大量标签,对计算性能要求高,并且维护不便。
3.多层级标签定义
-
做法:预先定义标签大类,在逐级细分,最后产生具体标签。
-
不足:产生大量维护工作。并且定义的层级灵活性欠佳,而且匹配的标签是关键词加指标词,不能很好地表达用户的言语习惯。
为了解决以上问题,马蜂窝推荐和搜索研发团队提出了一种通过匹配预设句式的模式,灵活、动态提取用户评论标签的方式,将每个预设句式归宿到固定标签分类,在分类显示中动态地采用最大数标签作为整个分类标签的显示方式,极大减少了固定标签的数量,并且每个句式是任意的多个词组联合组成,使最终提取的标签内容在更符合用户语言习惯的同时,更好地体现了不同评论内容标签的个性化和差异化。
基于匹配预设句式模板动态提取用户评价标签
首先和大家解释几个关键的概念。
-
标签:标签可以理解成对一个给定信息进行的具体描述。比如“离望京地铁站近”、“步行到大望路地铁站 1 分钟”等;
-
句式:这里,我们可以先简单理解成是对同一类型标签的集合,可以理解成“评价方式”,比如上句关于标签的举例,都是对“离地铁站近”的评价;
-
标签类别:同样,我们先简单理解成是对同一类句式,也就是一类“评价”的集合,比如上述句式包含在“交通方便”这类评价里。
三者关系可以描述为,一个标签类别包含了 m 个句式;一个句式会产生 n 个标签,所以一个标签类别最多会对应 m*n 个标签。
标签系统总体结构
系统主要有两部分内容:标签句式的定义和自动化的句式生成。今天主要介绍第一部分关于如何定义句式和产生标签。
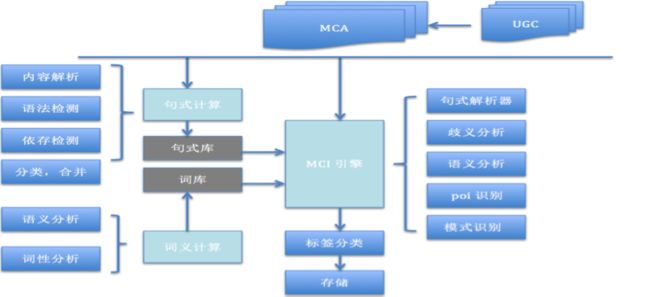
图1 - 标签系统结构
具体做法和实施步骤
一、建立句式库
顾名思义,句式库是对所有预设句式的集合。接下来我们会具体讲解如何定义句式和产生标签。

图2 - 句式库示意
1. 建立词库
词库是由词组以及其包含的词语组成的。每个词组和词语分别具有唯一标识;词组是对其包含的词语的概括和汇总;词语为表示该词组的近义词、俗语、舶来词、英语、缩写等。例如:
• 词组:表示“班车”的名称集合
• 词语:班车,摆渡车,接泊车,shuttlebus 等是词组中的词语
词组也可以表示一类描述信息,比如:
-
词组:表示“距离近”的集合
-
词语:近,不远,很近,走路 1 分钟等

图3 - 词库示意

图4 - 词组示意
另外还会建立排除词库。排除词库中,以后不对这些词进行处理,排除词库大部分是无具体意义词,比如“我们”,“他们”之类的代词、“呀”“耶”“哦”之类的语气助词,“之后”“然后”“所以”这样没有转折意义的连词等等。
2.对句式分类,得到标签类别
标签类别为用户点评信息的概括和归类,将同一类型的句式归类为一个标签类别,每个标签类别代表了一类相近评价内容。
比如“服务好”类,代表所有描述服务好的评价信息,该标签类别由多个句式组成,例如“{老板}{热情}”,“{前台}{专业}”,表示的都是关于酒店和民宿服务这一类评价的句式,则这些句式产生的标签都会归属到相同的类型上,但不同业务的 UGC 产生的具体标签会各具特色。
![]()

图5 - 句式分类示意
3.基于词组进行句式组合
每个句式表示一种逻辑语义,通过词组之间的组合定义句式,表达不同内容,并具有唯一标识。
每个句式的词组中用具体的词语组合得到的结果定义为其产生的标签,如“距离牡丹园地铁站近”“离牡丹园地铁站很近”等均为{离}{地铁站}{近}句式产生的标签。
参与句式组合的词组分为四类,分别是普通词组、独立词组、POI、固定文字。构建句式时,并列关系的词组之间用 OR 表示,可减少句式的定义数量。例如:
-
句式:{提供}[{地铁站}OR{码头}OR{公交站}OR{火车站}OR{机场}OR{市中心}]{班车}
-
普通词组:“提供”、“班车”
-
独立词组:当匹配到该句式的独立性词组时,均需要单独显示,突出标签的特色性。即“地铁站”“码头”等。
当匹配到“提供-地铁站-班车”以及“提供-码头-班车”时,其表示的是不同含义或者特别含义,虽然都在提供班车同一个标签分类下,但需要单独显示。同理匹配到POI(感兴趣点,为目的地下的一些景点、地点等,如故宫、泰山、火车站、公交站、医院等)中的任意一条记录,则该标签均需要单独显示。
二.句式匹配,生成标签
1. 生成标签
从 UGC 内容中提取一条评价文本,按照常用标点符号加用户常用符号为拆分依据,得到若干子句。![]()

图6 - UGC 评价原文
1). 依次匹配
标签类别库中的每个句式从第一个词组开始,用词组中的每个词语按长度排序后依次与子句进行匹配。
如果某一个句式中的词语与子句中的相匹配,则记录该词语及这个词语在子句中的位置,之后按句式的词组顺序,继续匹配下一个词组中的词语,且匹配的开始位置是上次匹配词语的结束位置的后一位,继续逐个匹配词组中的词语信息,依此类推,不断循环这个过程,直到这个句式的每个词组中的一个词语匹配成功,则记录的每个词组中的匹配词语组合就是这个句式匹配的标签。
比如句式{服务}{好},第一个词语 {服务}匹配到的词语是词组中的“酒店服务”,第二个词组{好}匹配到的词语是“不错”,则生成标签“酒店服务不错”。在另外一个子句中可能匹配到的标签是“酒店服务好”。虽然他们表现形式为不同的标签,但都是由一个句式产生的同一类型的标签。
2). 顺序匹配
比如“机场有班车去酒店”,和“酒店有班车去机场”虽然包含的汉字完全一样,但表达的却是不同含义。
3). 词距阈值
在匹配的过程中,如果相邻两个词组距离大于一定的阈值,则认为不匹配。
例如句式是“{房间}{大}”,评价子句是“酒店房间里有一幅画着蓝天和大海的油画”。如果没有词距的判断,则该评价子句将匹配到“{房间}{大}”的参考句式,但是该评价子句的意思与“房间大”这一标签表达的意思明显不同。假设将第二预定阈值设置为三个字的词距,评价子句中“房间”与“大”之间的词距超过了三个字,就可以判断参考句式与评价子句不相匹配,避免了错误匹配。
由于句式中的词语之间可能有一定的位置相关性,通过判断匹配词之间的距离是否符合阈值,剔除那些子句中成功匹配到的词语但是并不表示符合句式含义的内容。
4).一“否”即否
当一个句式匹配到一个标签时,则判断该句子和句式是否存在否定关系,如果有则认为不匹配。比如饭菜不好吃,则匹配不到{包含饭菜的词组}{包含好吃的词组}这样的句式上。
正确匹配之后,记录这个子句和标签的对应关系,并找到该句式在标签类别库中对应的标签类别号,建立被匹配的子句与所属的标签类别之间的关系。如果子句没有成功匹配到对应的句式,则保存到未匹配的子句存储中,之后用来继续挖掘可用标签信息。
关于匹配方式这里,有一些经验和大家分享:
对于容易混淆的词语,应首先建立好一个混淆词语库,比如“好”这个词语,对应的混淆库的词语有“好像”,“好似”等等。在匹配到一个词语时发现它是易混淆词,则查看该词语对应的混淆词是否在这个词语的位置上,如果成立则认为不匹配,比如饭菜好像是之前的。则匹配不到{包含饭菜的词组}{包含好吃的词组}这样的句式上。
对于一些繁体字的点评先转成简体汉字,之后进行匹配。
之前,我们对一些其他匹配方式也进行了调研。比如子句先分词,之后用每个词去发现句式中的词语是否存在,这样的效率是比较高,因为用哈希方式查找。
但这样要依赖分词的准确性,也无法满足用户个性化的需求,尤其在评价语句中,有大量的不符合语法的,口语化的表达和网络词语使用,所以分词很难做到非常准确,最后得到的标签匹配效果也不理想。
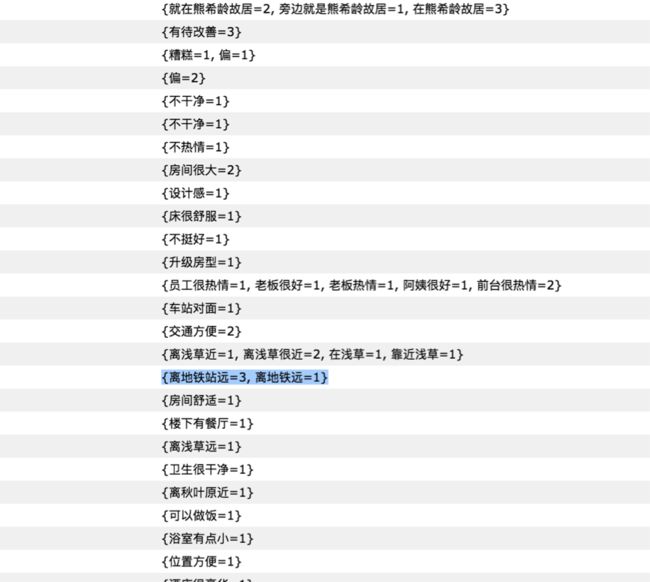
图7 - 产生的标签
2. 确定显示标签
在不同的目标下,会有不同评价方式,展示出来的标签也应该体现出相应的个性化和差异化。我们根据该目标所有评论对应的标签类别号,统计每个标签类别中所有句式产生的标签出现频次,将出现频次最高的标签作为该标签类别的显示名称。
例如标签类别“性价比好”有三个句式{性价比}{很好},{性价比}{高},{价格}{便宜},在某个目标下的评价统计中标签“性价比不错”“性价比高”“价格实惠”分别出现了 5 次,10 次,7 次,那么关于这个标签类别显示的标签为“性价比高”。
这里有一种特殊情况:如果在同一个标签类别下一个句式定义中,有需要独立显示的标签,则该句式产生的标签不会和其他句式标签合并,而是独立显示该句式中频次最高的标签。
比如句式{提供}{去}[{火车站}OR{飞机场}]{班车},其中设定{火车站}和{飞机场}是需要独立显示的标签,则最后这两个词语对应产生的频次最高的标签的结果是“提供去车站班车”和“提供到机场的班车”,这两个标签不会和该类别(提供班车)下的其他频次最高标签合并,比如“去车站方便”,而是作为两个标签独立显示。
再如,标签类别“位置好”中包含了两个句式,{离}{POI}{近}和{POI}{步行}{3}{分钟},因为POI是被设定需要独立显示的类别,若产生的标签“离故宫近”的频次为 10,“离景山近”的频次是 15,“故宫步行 3 分钟”的频次是 17,则在“位置好”标签类别下,分别显示标签“故宫步行 3 分钟”和“离景山近”。
3. 对未匹配子句分词处理
对于未被匹配的子句进行自动产生句式处理,使用内容分类,句法分析,依存分析,词义分析等方法自动产生标签分类和每个分类下的句式,用户可以对这些标签句式审核和调整。并可对已有词组推荐近义词等,丰富词组的词语数量。
4.定位子句
因为之前已经保存了标签和被匹配子句之间的关系,当点击标签时,会高亮显示对应的子句。
小结
本文介绍的关于预设句式模板定义,通过灵活的词组的组合方式,可以动态的匹配大量标签,很好的解决了标签定义量大的问题。
由于句式的定义符合用户对目标的评价习惯,所以能覆盖更多的用户点评,提高了召回率,且模板产生的标签更符合评价语言的表达方式。
由于文章篇幅所限,后期我们会再介绍自动的句式生产。大家可以订阅马蜂窝技术公众号持续关注。谢谢。
本文作者:乔志军,马蜂窝搜索与推荐研发团队内容挖掘工程师。
关注马蜂窝技术(微信ID:mfwtech),找到更多你想要的内容。
