- 内存分配器类型
- 面向数据的设计方法
- 采用面向对象设计的系统的优化方法
- Entity Compoenent System
概要

游戏的性能优化是从哪儿出发的?其实它是从内存的使用效率上出发的,

为什么内存如此重要呢?

FC的硬件配置
- 6502 8-bit processor @ 1.79 MHz
- 16-bit mem address bus(65kb)
- Custom PPU wit 2kb of video RAM w/48 colors
- Display 256 pixels x 240 pixels
- Custom APU
- 10NES Lockout chip
FC的计算模型
The simplest compute model. Evenything can be mapped to "memory address".
所有的外部资源全部被映射到内存空间上,包括游戏的ROM,从800开始的ROM,从协处理器PPU Audio和控制器的访问端口
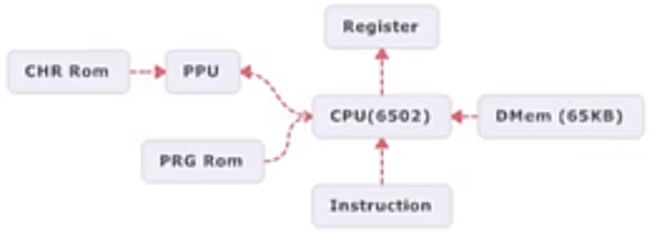
PC的指令类型(Instructions)
- Load:LDX
- Store: STA
- Compare:CPX
内存的执行效率和指令执行效率之间只有4倍之差。
MemoryAccess:4x memory
30年后
在同样的时间点内,内存的访问速度是没有增加的。
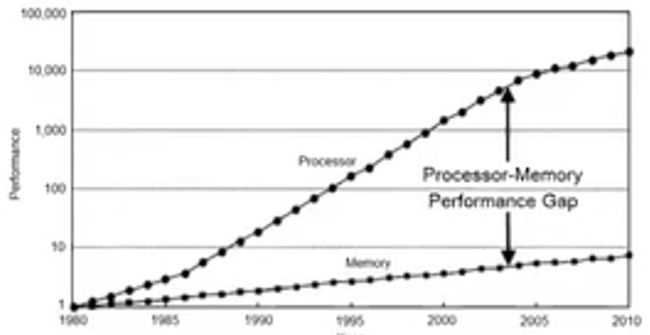
内存访问延迟

如何高效的申请内存 (内存分配器)
游戏领域常用内存分配器有:
- Malloc/Free
- Linear,Stack Allocator
- Freelist Allocator
- Buddy Allocator
- Handle Based Allocation
Malloc/Free
- 支持任意尺寸内存分配
- Free开销远远大于申请开销 DLMalloc
- 绝大多数的实现依赖 Glocal Mutex(JeMalloc)
- 容易造成内存碎片
它在Free的时候,还要去处理内存尺寸的合并,以及处理这个Free是否要回退给系统的内存,所以说它的Free开销是远大于申请开销的。也就是说,如果你高频的使用Malloc/Free的话,会发现性能效率是非常低的。
如果你有一个多线程的程序,又频繁地申请释放内存的话,会发现性能很有可能会变成一个线程的性能。而并没有随着多核而scale。
对于游戏来说,32位的系统最高的空间数大约支持到3.5G左右, 因为500M要求给系统。在这3.5G中需要放足够多的资源如贴图、地图、数据...,所以它的申请和释放时非常容易形成内存碎片的。
尤其MMO游戏,由于MMO游戏特性是非常动态的,因为是sreaming地图,地图要动态地加载,这个时候就有非常多的申请和释放。 你的角色进入你的视野也需要动态地加载。这些申请和释放都非常容易形成内存碎片。
内存碎片也就是不停地申请释放一堆小内存, 在小内存释放之后会造成了它的空间,也就是小内存之间间隔的尺寸,没办法形成一个更大内存的分配。例如你不停地申请释放10K的内存,结果你申请到的每个10K中间都间隔10K,这样的话,中间间隔的10K是没有办法形成一块大的内存的。在你下次申请的时候虽然发现还有1M的空间,为什么不能使用啊。就是因为这个内存被它隔开了,也就没法申请出来这1M的内存。 在复杂游戏引擎设计的时候,内存碎片是必须要考虑的一个问题。
C++的new其实底层也是走的类似malloc/free的流程。
对于游戏来说,基本上是应该严格禁止使用malloc/free的。就是不要使用系统提供给你的内存分配器。一般会自己去写一套自己的内存分配器去帮助它分配和释放内存。
线性分配器(Linear Alloctor)
- 申请 = 线程增长
- 释放 = do nothing
- 特定时间重叠
- 典型应用场景
- 每帧生成的渲染状态数据
- 每帧发送给GPU的骨骼动画数据
- 好处
- 非常容易支持 lockfree
- 效率极高只需要一个index递增操作
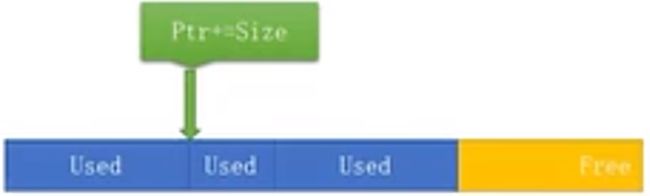
线性分配器是游戏中最常用的内存分配器, 也是最简单的内存分配器。 线性分配器的特征是申请等于线性增长。例如有一个指针首先会从系统申请出一块比较大的内存,当别人从你申请的内存中申请内存时,这个指针每次只增长而不释放。 在特定的时间重置,当你不需要整块内存的时候,会将指针revert到自己内存最开始的位置。
简单来说,申请的时候指针自增,释放的时候指针revert 0。这个效率也就是两条指令的执行效率,所以非常高。
线性分配器的应用场景,例如在天刀的引擎中每帧会生成一套渲染的数据,也就是每帧所要绘制的画面。这种操作在天刀引擎中大概是数万级别的,如此大的量如果是使用malloc/free来申请释放内存的话,一帧里面就是万级别,跑一秒就几百万的级别了,内存也早就撑不住了。在这种情况下,直接使用加加、减减两个指令操作就申请出内存,因为每帧申请的渲染数据非常符合线性分配器在特定时间重置的特点。
基本上渲染线程的重要操作都是使用线性分配器完成的。
栈分配器(Stack Allocator)
- 实现类似线性分配器
- LIFO by maked positions
- 典型应用场景:关卡资源加载
- 好处
- 性能类似线性分配器
- 可以按需进行释放
- 可以作为其他内存分配器的后端分配器(back allocator)
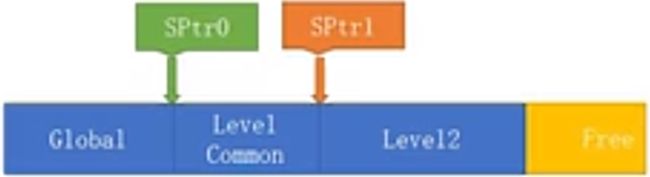
栈分配器(stack allocator)的工作原理和实现其实和线性分配器(linear allocator)非常类似。它是一个典型的LIFO(Last-In-First-Out,后进先出)方式,相当于在线性分配器上做了一个位置(position) 。
典型应用场景就是关卡加载,例如当关卡刚开始加载的时候,可以把数据种类分为global全局数据 ,此时申请内存后指针就打到全局数据结束的位置,并记下当时指针的状态,指针的状态可以记录为加载全局数据的时间点。这个时候,可能要加载关卡了,可以把多个关卡共享的数据继续放入内存,然后再记录下关卡comment的数据。接下来在加载特定的第一关,依次操作。当第一关要卸载掉的时候,我的操作时pop到sptr1的位置上。和线性分配器一样,只要指证(pointer)的位置回来就行了。
空闲列表内存分配器(Freelist Allocator)
- 用链表方式管理的连续内存
- 申请和释放的复杂度为O(1)
- 缺点是连续申请返回的内存不连续而且通常是固定尺寸
- 典型应用场景是粒子特效缓冲池
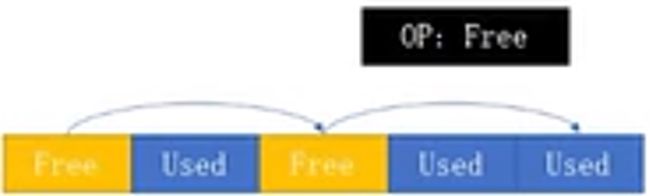
空闲列表内存分配器可以认为是仅次于线性内存分配器的最常用的内存分配器。
空闲列表内存分配器是使用链表的方式管理连续内存,如果现在需要申请一次,直接返回当前头上的这个位置,然后将头置为第二个释放的位置。 它的操作也只是一个链表赋值的操作。当要释放一个使用过的内存时,只需要回退并将重新设置链表的指向。
在天刀的一个分配器中有一个小内存分配池,因为它是一个链表所以可以做到比较好的lock free的结构。 在小内存缓冲池中会对不同的内存尺寸,从256byte到4k的尺寸,为它预留了这样一长串的内存。当外面有一个内存分配进来时,例如它说我想分配一个132byte的尺寸,那我就向上递256byte到内部的小内存分配的bucket上面。每个小内存的bucket都是这种freelist allocator的。所以它的效率是非常高的。
只要是符合尺寸固定,申请和释放都可以通过freelist allocator来实现。
Buddy Allocator
- 支持2^n大小的内存
- 自动合并相邻的内存
- 典型应用场景是可能会持续多帧、GPU上的内存管理..
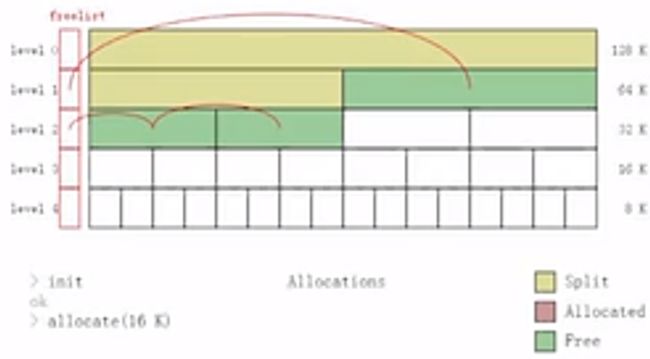
Buddy Allocator的含义跟它的样式是非常像的。首先你拿到一块大小为2^n的内存块,每次释放时它会一直看旁边的那块内存,由于它是分不同的level的,例如level4的级别上是1k、1k...的,那到level3上面就是2k、2k...的,以此递增。释放时先回去找旁边相邻的这块内存是否也被释放了,如果旁边相邻的内存也被释放了的话,就会把它mark并向上继续寻找,同时告诉系统“我这儿有一个连续的2k的内存”。
Buddy Allocator适用于可能会持续多帧,也就是它可以由多帧的数据。 另外适合GPU上的内存管理,因为它的算法比较简单,可以写在GPU中。 另外一种情况是,在CPU上一些固定尺寸且为2^n如贴图,贴图的加载其实占了游戏引擎加载中最大的一部分,由于游戏安装包中80%以上的数据都有可能是贴图,所以贴图的加载管理也是非常有必要的。
Handle Based Allocation
- 申请后不直接返回
void* - 返回一个代表这个对象的
handle - 好处
- 可以被随便拷贝
- 杜绝由于上层错误访问
- 降低耦合关系
- 典型应用场景
- Windows Object handle
- Entity's GraphicState hanle
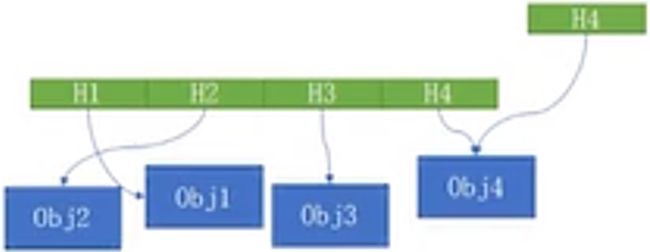
Handle Base Allocation严格意义上讲不是一个分配器,而是内存结构上一层的一种抽象。它的好处是申请后不直接返回void*,而是返回一个代表对象的handle,handle常见的是u64或u32。handle一般会将u64分为两部分,一部分可能分出一个index,另外一部分可能会分配出一个类似于状态标记位置的东西。 它最重要的好处是可以随便被拷贝。
在设计系统时有时会碰到非常复杂的情况,例如主线程想要用一个对象,但这个对象可能是在渲染线程使用的。这种情况下,主线程和渲染线程会分两个view来去访问这个对象。 如果主线程拿到的是一个对象的指针,那主线程和渲染线程之间就形成了访问冲突。但如果是使用它的handle,对主线程而言,访问的就是对象的一个主线程上的实例。在同步的时候会把主线程和渲染线程两个对象进行一次双buffer一样的交换,这样就避免了两个线程访问的时候的访问冲突。同时程序员在处理时就不需要考虑对象是否处于一个安全的状态。这样就降低了整体的耦合关系。对于上层程序员编写代码时就可以简化思维模式,不用考虑那么多东西。
如何高效地访问内存(面向数据的设计方法)
面向对象的设计的弊端
案例:典型的树状结构的场景表示,约55000个box,每个黄色的box相当于一个根节点,红色的box的transform依赖于黄色box的transform,粉色的又依赖于红色,白色的又依赖于粉色的。
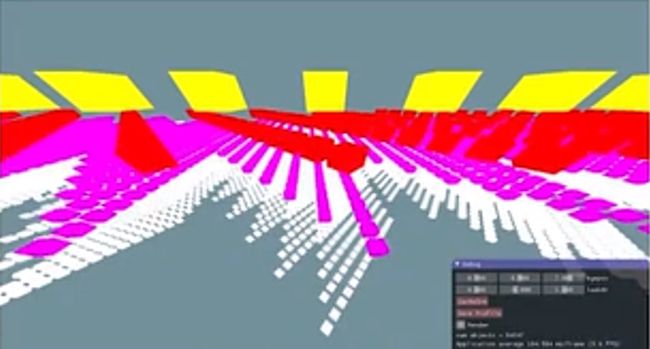
在使用面向对象的设计时,每个box都有一个渲染函数和更新函数,可以去修改box的transform、获取box的binding等等。
节点对象的布局使得所有可以用来加速数学计算的对象上的内存都不是被分到cache land上。也就是说,布局中所有节点都不是和内存贴合紧密的。
对象的内存地址
- 内存分配不连续
- 遍历时会产生
cache miss

观察发现,内存的读取是跳变的,所以在遍历的时候会产生非常大的cache miss。如果一块内存没有在`cache·中,系统就会跑到主存中去读,也就是说要产生100倍左右的读取时间浪费。
面向数据的设计
- 改用连续内存分配器
面向数据的设计首先要求内存分配器分配是要连续的,当CPU在读取数据的时候,会有一些技术帮助做prefetch。也就是说当在读取数据时,下面一段数据就已经帮你准备好了。当线性访问的时候,效率会非常高。虽然这些都不需要你来做,但前提条件是你的访问必须是线性的,而且处理的对象是在内存上的。
https://gameinstitute.qq.com/course/detail/10119