用户建模
一. User 模型
实现用户注册功能的第一步是,创建一个数据结构,用于存取用户的信息。
在 Rails 中,数据模型的默认数据结构叫模型(model,MVC 中的 M)。Rails 为解决数据持久化提供的默认解决方案是,使用数据库存储需要长期使用的数据。与数据库交互默认使用的是 ActiveRecord。Active Record 提供了一系列方法,无需使用关系数据库所用的结构化查询语言(Structured QueryLanguage,简称 SQL),就能创建、保存和查询数据对象。Rails 还支持迁移(migration)功能,允许我们使用纯 Ruby 代码定义数据结构,而不用学习 SQL 数据定义语言(Data Definition Language,简称 DDL)。最终的结果是,Active Record 把你和数据库完全隔开了。咱们开发的应用在本地使用 SQLite,部署后使用PostgreSQL。这就引出了一个更深层的话题——在不同的环境中,即便使用不同类型的数据库,我们也无需关心 Rails 是如何存储数据的。
1.数据库迁移
回顾一下前面的内容, 我们在自己创建的 User 类中为用户对象定义了 name 和 email 两个属性。那是个很有用的例子, 但没有实现持久化存储最关键的要求: 在 Rails 控制台中创建的用户对象, 退出控制台后就会消失。这次的目的是为用户创建一个模型, 让用户数据不会这么轻易消失。
与前面定义的 User 类一样, 我们先为 User 模型创建两个属性, 分别为 name 和 email 。我们会把 email 属性用作唯一的用户名。 (下面也会添加一个属性, 用于存储密码。)在前面的代码中,我们使用 Ruby的 attr_accessor 方法创建了这两个属性:
class User attr_accessor :name, :email ... end
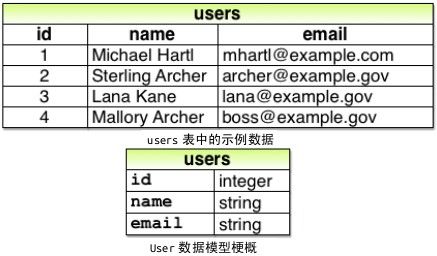
不过, 在 Rails 中不用这样定义属性。前面提到过,Rails 默认使用关系数据库存储数据, 数据库中的表由数据行(row)组成, 每一行都有相应的列(column), 对应于数据属性。例如, 为了存储用户的名字和电子邮件地址, 我们要创建 users 表, 表中有两个列, name 和 email , 这样每一行就表示一个用户, 如下图所
示, 对应的数据模型如下图所示。(下图只是梗概, 完整的数据模型请往下看。)把列命名为 name 和 email 后, Active Record 会自动把它们识别为用户对象的属性。
注:你可能还记得, 在上面的代码中, 我们使用下面的命令生成了 Users 控制器和 new 动作$ rails generate controller Users new
创建模型有个类似的命令 —— generate model 。我们可以使用这个命令生成 User 模型, 以及 name 和 email 属性, 如下代码所示。
(1).生成 User 模型

注:控制器名是复数, 模型名是单数: 控制器是 Users , 而模型是 User 。我们指定了可选的参数 name:string 和 email:string , 告诉 Rails 我们需要的两个属性是什么, 以及各自的类型(两个都是字符串)。
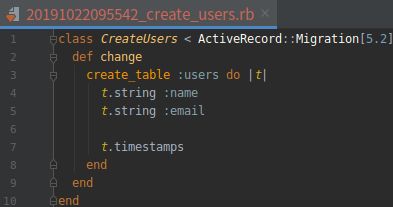
执行上述 generate 命令之后, 会生成一个迁移文件。迁移是一种递进修改数据库结构的方式, 可以根据需求修改数据模型。执行上述 generate 命令后会自动为 User 模型创建迁移, 这个迁移的作用是创建一个 users 表, 以及 name 和 email 两个列, 如下代码所示:
(2).User 模型的迁移文件(创建 users 表)
打开文件:db/migrate/[timestamp]_create_users.rb
注:迁移文件名前面有个时间戳(timestamp),指明创建的时间。早期, 迁移文件名的前缀是递增的数字, 在团队协作中, 如果多人生成了序号相同的迁移文件就可能会发生冲突。除非两个迁移文件在同一秒钟生成这种小概率事件发生了, 否则使用时间戳基本可以避免冲突。
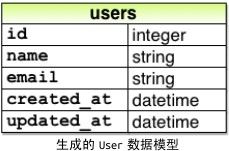
迁移文件中有一个名为 change 的方法,定义要对数据库做什么操作。在上图代码中, change 方法使用 Rails 提供的 create_table 方法在数据库中新建一个表,用于存储用户。create_table 方法可以接受一个块,有一个块变量 t (“table”)。在块中, create_table 方法通过 t 对象在数据库中创建 name 和 email 两个列,二者均为 string 类型。表名是复数形式( users ),不过模型名是单数形式( User ),这是 Rails 在用词上的一个约定:模型表示单个用户,而数据库表中存储了很多用户。块中最后一行 t.timestamps 是个特殊的方法,它会自动创建 created_at 和 updated_at 两个列,分别记录创建用户的时间戳和更新用户的时间戳。(前面有使用这两个列的例子。)这个迁移文件表示的完整数据模型如下图所示。
我们可以使用如下的 db:migrate 命令执行这个迁移(这叫“向上迁移”):
$ rails db:migrate

注:大多数迁移, 都是可逆的, 也就是说可以使用一个简单的命令“向下迁移”, 撤销之前的操作。这个命令是 db:rollback :
$ rails db:rollback
2.模型文件
(1).刚创建的 User 模型
打开文件:app/models/user.rb
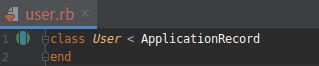
注:前面说过, class User < ApplicationRecord 的意思是 User 类继承自 ApplicationRecord 类(而它继承自 ActiveRecord::Base 类), 所以 User 模型自动获得了 ActiveRecord::Base 的所有功能。
3. 创建用户对象
探索数据模型使用的工具是 Rails 控制台。因为我们(还)不想修改数据库中的数据, 所以要在沙盒(sandbox)模式中启动控制台:
$ rails console --sandbox
注:如提示消息所说, “Any modifications you make will be rolled back on exit”, 在沙盒模式下使用控制台, 退出当前会话后, 对数据库做的所有改动都会回归到原来的状态(即撤销)。
在前面的控制台会话中, 我们要引入必要的代码才能使用 User.new 创建用户对象。对模型来说, 情况有所不同。你可能还记得前面说过, Rails 控制台会自动加载 Rails 环境, 这其中就包括模型。也就是说, 现在无需加载任何代码就可以直接创建用户对象:
![]()
注:上述代码显示了用户对象在控制台中的默认表述
如果不为 User.new 指定参数, 对象的所有属性值都是 nil 。前面, 我们自己编写的 User 类可以接受一个散列参数, 指定用于初始化对象的属性。这种方式是受 Active Record 启发的, 在 Active Record 中也可以使用相同的方式指定初始值:
![]()
注:我们看到 name 和 email 属性的值都已经按预期设定了。
数据的有效性(validity)对理解 Active Record 模型对象很重要, 我们会在以后深入探讨。不过注意, 现在这个 user 对象是有效的, 我们可以在这个对象上调用 valid? 方法确认:
![]()
目前为止, 我们都没有修改数据库: User.new 只在内存中创建一个对象, user.valid? 只是检查对象是否有效。如果想把用户对象保存到数据库中, 要在 user 变量上调用 save 方法:
![]()
注:如果保存成功, save 方法返回 true , 否则返回 false 。(现在所有保存操作都会成功, 因为还没有数据验证; 等到了下面的内容就会看到一些失败的例子。) Rails 还会在控制台中显示 user.save 对应的 SQL 语句( INSERT INTO "users"... ), 以供参考。我们几乎不会使用原始的 SQL, 所以此后我会省略 SQL。不过, 从 Active Record各种操作生成的 SQL 中可以学到很多东西。
与以前定义的 User 类一样, User 模型的实例也可以使用点号获取属性:
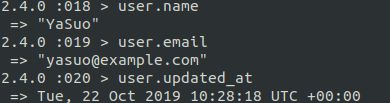
等以后会介绍, 虽然一般习惯把创建和保存分成如上所示的两步完成, 不过 Active Record 也允许我们使用User.create 方法把这两步合成一步:
![]()
![]()
注:User.create 的返回值不是 true 或 false , 而是创建的用户对象, 可以直接赋值给变量(例如上面第二个命令中的 foo 变量)
create 的逆操作是 destroy :
![]()
奇怪的是, destroy 和 create 一样, 返回值是对象。我不觉得什么地方会用到 destroy 的返回值。更奇怪的是, 销毁的对象还在内存中:
![]()
注:那么我们怎么知道对象是否真被销毁了呢? 对于已经保存而没有销毁的对象, 怎样从数据库中读取呢? 要回答这些问题, 我们要先学习如何使用 Active Record 查找用户对象。
4.查找用户对象
Active Record 提供了好几种查找对象的方法。下面我们使用这些方法查找前面创建的第一个用户, 同时也验证一下第三个用户( foo )是否被销毁了。先看一下还存在的用户:
![]()
注:我们把用户的 ID 传给 User.find 方法, Active Record 会返回 ID 为 1 的用户对象。
下面来看一下 ID 为 3 的用户是否还在数据库中:
![]()
注:因为我们在前面销毁了第三个用户, 所以 Active Record 无法在数据库中找到这个用户, 从而抛出一个异常(exception), 这说明在查找过程中出现了问题。因为 ID 不存在, 所以 find 方法抛出 ActiveRe-cord::RecordNotFound 异常。
除了这种查找方式之外, Active Record 还支持通过属性查找用户(find_by):
![]()
注:我们将使用电子邮件地址做用户名, 在学习如何让用户登录网站时会用到这种 find 方法(后面的内容)。你可能会担心如果用户数量过多, 使用 find_by 的效率不高。事实的确如此, 我们会在下面说明这个问题, 以及如何使用数据库索引解决。
再介绍几个常用的查找方法。首先是 first 方法:
![]()
很明显, first 会返回数据库中的第一个用户。还有 all 方法:
![]()
从控制台的输出可以看出, User.all 方法返回一个 ActiveRecord::Relation 实例, 其实这是一个数组, 包含数据库中的所有用户。
5.更新用户对象
创建对象后, 一般都会进行更新操作。更新有两种基本方式, 其一, 可以分别为各个属性赋值, 在前面的内容中就是这么做的:

注:如果想把改动写入数据库, 必须执行最后一个方法。
我们可以执行 reload 命令来看一下没保存的话是什么情况。 reload 方法会使用数据库中的数据重新加载对象:

现在我们已经更新了用户数据,如前面所说,现在自动创建的那两个时间戳属性不一样了:

更新数据的第二种常用方式是使用 update_attributes 方法:

update_attributes 方法接受一个指定对象属性的散列作为参数, 如果操作成功, 会执行更新和保存两个操作(保存成功时返回 true )。
注:如果任何一个数据验证失败了, 例如存储记录时需要密码, update_attributes 操作就会失败。
如果只需要更新单个属性, 可以使用 update_attribute 方法, 跳过验证:

二. 验证用户数据
创建的 User 模型现在已经有了可以使用的 name 和 email 属性, 不过功能还很简单:任何字符串(包括空字符串)都可以使用。名字和电子邮件地址的格式显然要复杂一些。例如, name 不应该是空的, email 应该符合特定的格式。而且, 我们将把电子邮件地址当成用户名用来登录, 那么在数据库中就不能重复。
1.有效性测试
前面说过, TDD 并不适用所有情况, 但是模型验证是使用 TDD 的绝佳时机。如果不先编写失败测试, 再想办法让它通过, 我们很难确定验证是否实现了我们希望实现的功能。
我们采用的方法是, 先得到一个有效的模型对象, 然后把属性改为无效值, 以此确认这个对象是无效的。以防万一, 我们先编写一个测试, 确认模型对象一开始是有效的。这样, 如果验证测试失败了, 我们才知道的确事出有因(而不是因为一开始对象是无效的)。
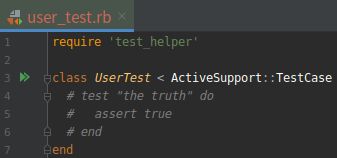
前面代码中的命令生成了一个用于测试 User 模型的测试文件, 现在这个文件中还没什么内容, 如下图所示:
(1).还没什么内容的 User 模型测试文件
打开文件:test/models/user_test.rb
为了测试有效的对象,我们要在特殊的 setup 方法中创建一个有效的用户对象 @user 。前面有提到过, setup 方法会在每个测试方法运行前执行。因为 @user 是实例变量, 所以自动可在所有测试方法中使用, 而且我们可以使用 valid? 方法检查它是否有效。
测试如下图所示:
(2).测试用户对象一开始是有效的 GREEN
打开文件:test/models/user_test.rb
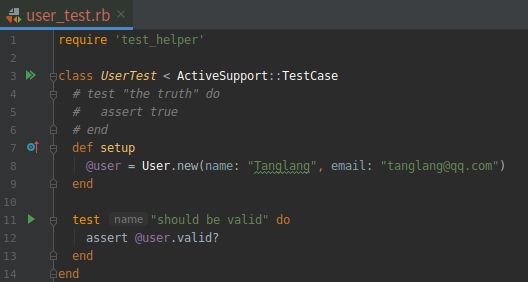
上图中使用简单的 assert 方法, 如果 @user.valid? 返回 true , 测试就能通过:返回 false , 测试则会失败。
因为 User 模型现在还没有任何验证,所有这个测试可以通过:

注:这里, 我们使用 rails test:models 命令, 只运行模型测试(与前面的 rails test:integration 对比一下)。
2.存在性验证
存在性验证算是最基本的验证了, 只是检查指定的属性是否存在。现在我们会确保用户存入数据库之前, name 和 email 字段都有值。以后会介绍如何把这个限制应用到创建用户的注册表单中。
我们要先在前面写好的测试文件的基础上再编写一个测试, 检查 name 属性是否存在。如下图所示, 我们只需把 @user 变量的 name 属性设为空字符串(包含几个空格的字符串), 然后使用 assert_not 方法确认得到的用户对象是无效的。
(1).测试 name 属性的验证 RED
打开文件:test/models/user_test.rb
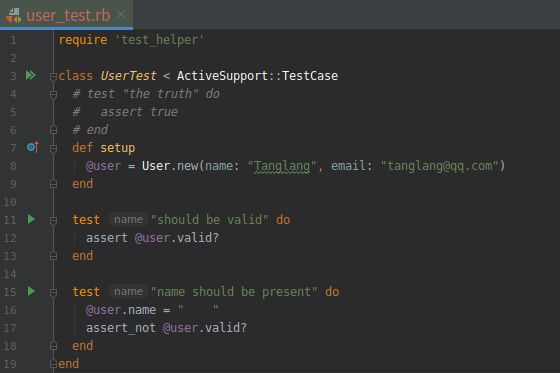
现在,模型测试应该失败:

我们在前面应该见过, name 属性的存在性验证使用 validates 方法,而且其参数为 presence: true , 如下图所示。 presence: true 是只有一个元素的可选散列参数; 前面说过, 如果方法的最后一个参数是散列, 可以省略花括号。(前面曾说过,Rails 经常使用散列做参数。)
(2).为 name 属性添加存在性验证 GREEN
打开文件:app/models/user.rb
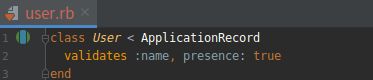
上图中的代码看起来可能有点儿神奇, 其实 validates 就是个方法。加入括号后, 可以写成:
打开控制台, 看一下在 User 模型中加入验证后有什么效果:

这里我们使用 valid? 方法检查 user 变量的有效性, 如果有一个或多个验证失败, 返回值为 false ; 如果所有验证都能通过, 返回 true 。现在只有一个验证, 所以我们知道是哪一个失败, 不过看一下失败时生成的 er-rors 对象还是很有用的:
![]()
因为用户无效, 如果尝试把它保存到数据库中, 操作会失败:

加入验证后, 测试应该可以通过了:

(3).测试 email 属性的验证 RED
打开文件:test/models/user_test.rb
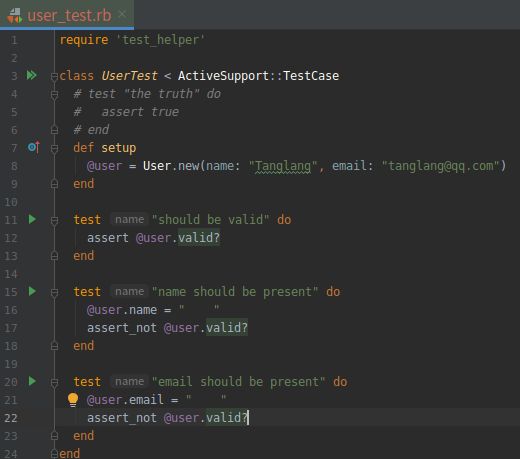
(4).为 email 属性添加存在性验证 GREEN
打开文件:app/models/user.rb
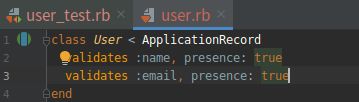
现在,存在性验证都添加了,测试组件应该可以通过了:

3.长度验证
我们已经对 User 模型可接受的数据做了一些限制, 现在必须为用户提供一个名字, 不过我们应该做进一步限制, 因为用户的名字会在演示应用中显示, 所以最好限制它的长度(name:50为上限, email:244为上限)
(1).测试 name 属性的长度验证 RED
打开文件:test/models/user_test.rb
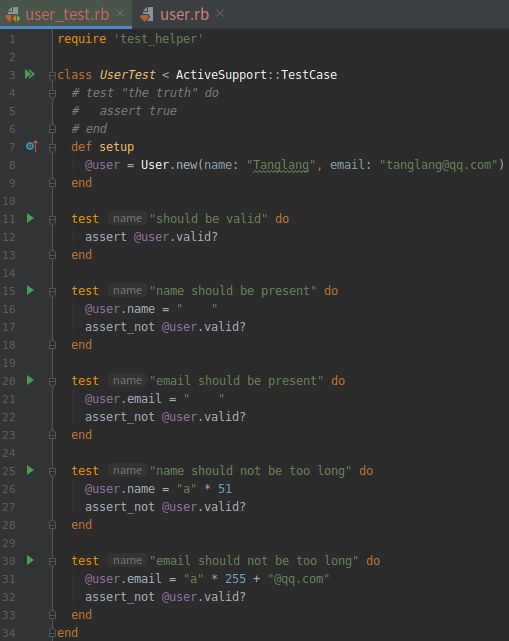
现在测试, 应该是失败的:

为了让测试通过, 我们要使用验证参数限制长度, 即 length , 以及限制上线的 maximum 参数, 如下图所示:
(2).为 name 属性添加长度验证 GREEN
现在测试应该可以通过了:

4.格式验证
电子邮件地址格式验证有点棘手, 而且容易出错, 所以我们会先编写检查有效电子邮件地址的测试, 这些测试应该能通过, 以此捕获验证可能出现的错误。也就是说, 添加验证后, 不仅要拒绝无效的电子邮件地址, 例如 user@163,com,还得接受有效的电子邮件地址, 例如 [email protected]。(显然目前会接受所有电子邮件地址, 因为只要不为空值都能通过验证。)检查有效电子邮件地址的测试如下图所示:
(1).测试有效的电子邮件地址格式 GREEN
打开文件:test/models/user_test.rb
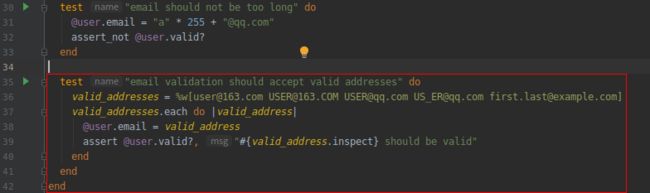
注意,我们为 assert 方法指定了可选的第二个参数, 用于定制错误消息, 识别是哪个地址导致测试失败的:
assert @user.valid?, "#{valid_address.inspect} should be valid"
这行代码在字符串插值中使用了前面介绍的 inspect 方法。像这种使用 each 方法的测试, 最好能知道是哪个地址导致失败的, 因为不管哪个地址导致测试失败, 都无法看到行号, 很难查出问题的根源。
接下来, 我们要测试几个无效的电子邮件, 确认它们无法通过验证, 例如 user@example,com(点号变成了逗号)和 user_at_foo.qq.com(没有“@”符号)。与上图一样, 下图也指定了错误消息参数, 识别是哪个地址导致测试失败的。
(2).测试电子邮件地址格式验证 RED
打开文件:test/models/user_test.rb
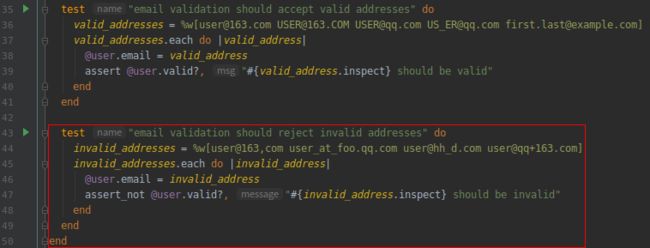
现在, 测试应该失败:

电子邮件地址格式验证使用 format 参数, 用法如下:
validates :email, format: { with: // }
它使用指定的正则表达式(regular expression, 简称 regex)验证属性。正则表达式很强大, 使用模式匹配字符串, 但往往晦涩难懂。我们要编写一个正则表达式, 匹配有效的电子邮件地址, 但不匹配无效的地址。在官方标准中其实有一个正则表达式, 可以匹配全部有效的电子邮件地址, 但没必要使用这么复杂的正则表达式。我们使用一个更务实的正则表达式, 能很好地满足实际需求, 如下所示:
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
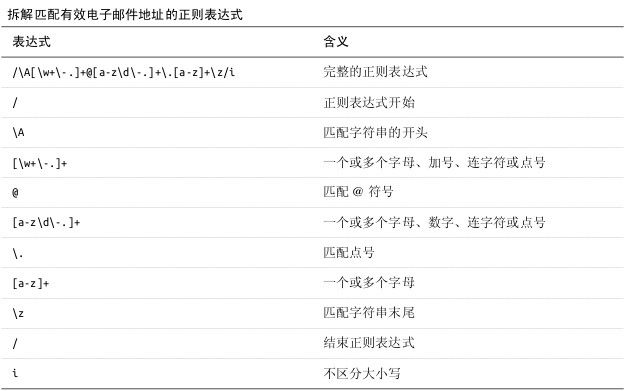
(3).使用正则表达式验证电子邮件地址的格式 GREEN
打开文件:app/models/user.rb

其中, VALID_EMAIL_REGEX 是一个常量(constant)。在 Ruby 中常量的首字母为大写。下面这段代码:
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: {maximum: 255}, format: {with: VALID_EMAIL_REGEX}
注:确保只有匹配正则表达式的电子邮件地址才是有效的。这个正则表达式有一个缺陷:能匹配 [email protected] 这种有连续点号的地址。修正这个瑕疵需要一个更复杂的正则表达式, 这里我就懒得弄了, 你到网上粘一个下来就可以了
现在测试应该可以通过了:

那么, 现在就只剩一个限制要实现了:确保电子邮件地址的唯一性。
5.唯一性验证
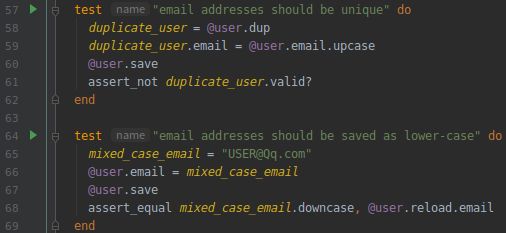
我们要先编写一些简短的测试。之前的模型测试, 只是使用 User.new 在内存中创建一个 Ruby 对象, 但是测试唯一性时要把数据存入数据库。对重复电子邮件地址的测试如下图所示:
(1).拒绝重复电子邮件地址的测试 RED
打开文件:test/models/user_test.rb
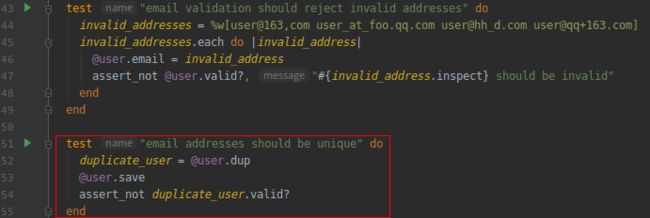
我们使用 @user.dup 方法创建一个和 @user 的电子邮件地址一样的用户对象,然后保存 @user , 因为数据库中的 @user 已经占用了这个电子邮件地址, 所以 duplicate_user 对象无效。
在 email 属性的验证中加入 uniqueness: true 可以让上图中的测试通过, 如下图所示:
(2).电子邮件地址唯一性验证 GREEN
打开文件:app/models/user.rb

这还不行,一般来说电子邮件地址不区分大小写,也就说 [email protected] 和 [email protected] 或 [email protected] 是同一个地址, 所以验证时也要考虑这种情况。
因此, 还要测试不区分大小写, 如下图所示:
(3).测试电子邮件地址的唯一性验证不区分大小写 RED
打开文件:test/models/user_test.rb
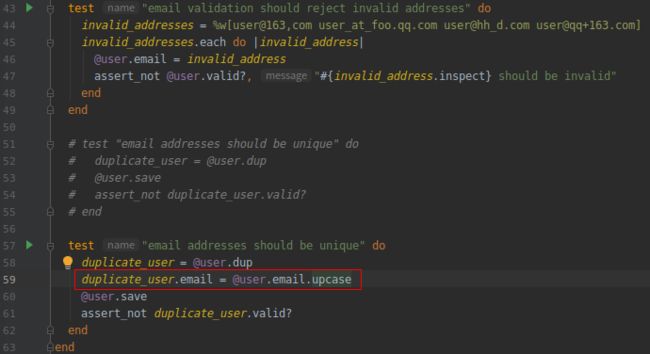
上面的代码, 在字符串上调用 upcase 方法。这个测试和前面对重复电子邮件的测试作用一样, 只是把地址转换成全部大写字母的形式。如果你觉得太抽象, 那就在控制台中实操一下吧:

当然, 现在 duplicate_user.valid? 的返回值是 true , 因为唯一性验证还区分大小写。我们希望得到的结果是 false 。幸好 :uniqueness 可以指定 :case_sensitive 选项, 正好可以解决这个问题, 如下图所示:
(3).电子邮件地址唯一性验证,不区分大小写 GREEN
打开文件:app/models/user.rb

注:我们直接把 true 换成了 case_sensitive: false , Rails 会自动指定 :uniqueness 的值为 true 。
至此, 我们的应用虽然还有不足, 但基本可以保证电子邮件地址的唯一性了, 测试组件应该可以通过了:

现在还有一个小问题——Active Record 中的唯一性验证无法保证数据库层也能实现唯一性。我来解释一下:
1. 我使用 [email protected] 在演示应用中注册; 2. 不小心按了两次提交按钮,连续发送了两次请求; 3. 然后就会发生这种事情:请求 1 在内存中新建了一个用户对象,能通过验证;请求 2 也一样。请求 1 创建的用户存入了数据库,请求 2 创建的用户也存入了数据库。 4. 结果是,尽管有唯一性验证,数据库中还是有两条用户记录的电子邮件地址是一样的。
注:上面这种难以置信的情况可能发生, 只要有一定的访问量, 在任何 Rails 网站中都可能发生(这是我从教训中学到的经验)。幸好解决的方法很简单, 只需在数据库层也加上唯一性限制。我们要做的是在数据库中为 email 列建立索引,然后为索引加上唯一性约束。
在数据库中创建列时要考虑是否需要通过这个列查找记录。以前面代码中的迁移创建的 email 属性为例,等以后实现登录功能后,我们将根据提交的电子邮件地址查找对应的用户记录。可是,在这个简单的数据模型中通过电子邮件地址查找用户只有一种方法——检查数据库中的所有用户记录,比较记录中的 email 属性和指定的电子邮件地址。也就是说,可能要检查每一条记录(毕竟用户可能是数据库中的最后一条记录)。在数据库领域,这叫全表扫描(full-table scan)。如果网站中有几千个用户,这可不是一件轻松的事。 为 email 列加上索引可以解决这个问题。我们可以把数据库索引看成书籍的索引。如果要在一本书中找出某个字符串(例如 "foobar" )出现的所有位置,需要翻看书中的每一页。但是如果有索引的话,只需在索引中找到 "foobar" 条目,就能看到所有包含 "foobar" 的页码。数据库索引基本上也是这种原理。
为 email 列建立索引要改变数据模型, 在 Rails 中可以通过迁移实现。在前面我们知道了, 生成 User 模型时会自动创建一个迁移文件。现在我们是要改变已经存在的模型结构, 那么使用 migration 命令直接创建迁移文件就可以了:
$ rails generate migration add_index_to_users_email
与 User 模型的迁移不同, 实现电子邮件地址唯一性的操作没有事先定义好的模板可用, 所以我们要自己动手编写, 如下图所示:
(4).添加电子邮件唯一性约束的迁移
打开文件:db/migrate/[timestamp]_add_index_to_users_email.rb
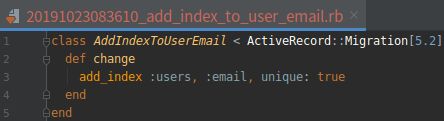
注:上述代码调用了 Rails 中的 add_index 方法, 为 users 表中的 email 列建立索引。索引本身并不能保证唯一性, 所以还要指定 unique: true 。
最后, 执行数据库迁移:
$ rails db:migrate
注:如果迁移失败的话,退出所有打开的沙盒模式控制台会话试试。这些会话可能会锁定数据库,拒绝迁移操作。
现在测试组件应该无法通过, 因为固件(fixture)中的数据违背了唯一性约束。固件的作用是为测试数据库提供示例数据。执行创建数据库的命令时会自动生成用户固件, 如下图所示, 电子邮件地址有重复。(电子邮件地址也无效, 但固件中的数据不会应用验证规则。)
(5).默认生成的用户固件 RED
打开文件:test/fixtures/users.yml
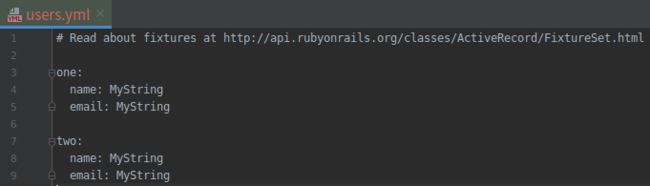
我们现在还用不到固件, 现在暂且把其中的数据删除, 只留下一个空文件, 如代码清单 6.31 所示:

为了保证电子邮件地址的唯一性, 还要做些修改。有些数据库适配器的索引区分大小写, 会把“[email protected]”和“[email protected]”视作不同的字符串, 但我们的应用会把它们看做同一个地址。为了避免不兼容, 我们要统一使用小写形式的地址, 存入数据库前, 把“[email protected]”转换成“[email protected]”。为此, 我们要使用回调(callback), 在 Active Record 对象生命周期的特定时刻调用。这里, 我们要使用的回调是 before_save , 在用户对象存入数据库之前把电子邮件地址转换成全小写字母形式, 如下图所示。(这只是初步实现方式, 以会再次完善这个东西, 届时会使用常用的“方法引用”定义回调。)
(6).把 email 属性的值转换为小写形式,确保电子邮件地址的唯一性 GREEN
打开文件:app/models/user.rb
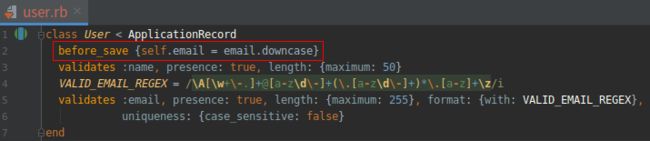
注:before_save 后有一个块,块中的代码调用字符串的 downcase 方法,把用户的电子邮件地址转换成小写形式。
在上图中,我们可以把赋值语句写成: self.email = self.email.downcase 其中 self 表示当前用户。但是在 User 模型中,右侧的 self 关键字是可选的,我们在 palindrome? 方法中调用 reverse 方法时说过: self.email = email.downcase 注意,左侧的 self 不能省略,所以写成 email = email.downcase 是不对的。 现在,前面遇到的问题解决了,数据库会存储请求 1 创建的用户,不会存储请求 2 创建的用户,因为后者违反了唯一性约束。(在 Rails 的日志中会显示一个错误,不过并无大碍。)为 email 列建立索引同时也解决了:为 email 列添加索引之后,使用电子邮件地址查找用户时不会进行全表扫描,从而解决了潜在的效率问题。
(7).上图中把电子邮件地址转换成小写形式的测试 GREEN
打开文件:test/models/user_test.rb
(8). before_save 回调的另一种实现方式 GREEN
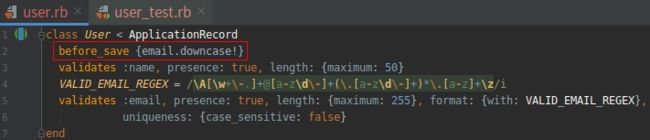
。。。
累了,累了,歇会