Python冷门知识
本文搜集整理网上和自己遇到的Python冷门知识。持续更新
内容整理自程序猿、Python编程时光
1、省略号也是对象
… 这是省略号,在Python中,一切皆对象。它也不例外。在 Python 中,它叫做 Ellipsis 。在 Python 3 中你可以直接写…来得到这玩意。
>>> ...
Ellipsis
>>> type(...)
<class 'ellipsis'>
而在 Python2 中没有…这个语法,只能直接写Ellipsis来获取。
>>> Ellipsis
Ellipsis
>>> type(Ellipsis)
<type 'ellipsis'>
它转为布尔值时为真
>>> bool(...)
True
最后,这东西是一个单例。
>>> id(...)
4362672336
>>> id(...)
4362672336
这东西有啥用呢?据说它是Numpy的语法糖,不玩 Numpy 的人,可以说是没啥用的。
在网上只看到这个 用 … 代替 pass ,稍微有点用,但又不是必须使用的。
try:
1/0
except ZeroDivisionError:
...
2、增量赋值的性能更好
诸如 += 和 *= 这些运算符,叫做 增量赋值运算符。这里使用用 += 举例,以下两种写法,在效果上是等价的。
# 第一种
a = 1 ; a += 1
# 第二种
a = 1; a = a + 1
+= 其背后使用的魔法方法是 iadd,如果没有实现这个方法则会退而求其次,使用 add 。
这两种写法有什么区别呢?
用列表举例 a += b,使用 add 的话就像是使用了a.extend(b),如果使用 add 的话,则是 a = a+b,前者是直接在原列表上进行扩展,而后者是先从原列表中取出值,在一个新的列表中进行扩展,然后再将新的列表对象返回给变量,显然后者的消耗要大些。
所以在能使用增量赋值的时候尽量使用它。
3、and 和or 的取值顺序
and 和 or 是我们再熟悉不过的两个逻辑运算符。而我们通常只用它来做判断,很少用它来取值。
如果一个or表达式中所有值都为真,Python会选择第一个值,而and表达式则会选择第二个。
>>>(2 or 3) * (5 and 7)
14 # 2*7
4、修改解释器提示符
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>>
>>> sys.ps2 = '---------------- '
>>> sys.ps1 = 'Python编程时光>>>'
Python编程时光>>>for i in range(2):
---------------- print (i)
----------------
0
1
5、默认参数最好不为可变对象
函数的参数分三种
- 可变参数
- 默认参数
- 关键字参数
今天要说的是,传递默认参数时,新手很容易踩雷的一个坑。
先来看一个示例:
def func(item, item_list=[]):
item_list.append(item)
print(item_list)
func('iphone')
func('xiaomi', item_list=['oppo','vivo'])
func('huawei')
在这里,你可以暂停一下,思考一下会输出什么?
思考过后,你的答案是否和下面的一致呢
['iphone']
['oppo', 'vivo', 'xiaomi']
['iphone', 'huawei']
如果是,那你可以跳过这部分内容,如果不是,请接着往下看,这里来分析一下。
Python 中的 def 语句在每次执行的时候都初始化一个函数对象,这个函数对象就是我们要调用的函数,可以把它当成一个一般的对象,只不过这个对象拥有一个可执行的方法和部分属性。
对于参数中提供了初始值的参数,由于 Python 中的函数参数传递的是对象,也可以认为是传地址,在第一次初始化 def 的时候,会先生成这个可变对象的内存地址,然后将这个默认参数 item_list 会与这个内存地址绑定。在后面的函数调用中,如果调用方指定了新的默认值,就会将原来的默认值覆盖。如果调用方没有指定新的默认值,那就会使用原来的默认值。

6、访问类中的私有方法
大家都知道,类中可供直接调用的方法,只有公有方法(protected类型的方法也可以,但是不建议)。也就是说,类的私有方法是无法直接调用的。
这里先看一下例子
class Kls():
def public(self):
print('Hello public world!')
def __private(self):
print('Hello private world!')
def call_private(self):
self.__private()
ins = Kls()
# 调用公有方法,没问题
ins.public()
# 直接调用私有方法,不行
ins.__private()
# 但你可以通过内部公有方法,进行代理
ins.call_private()
既然都是方法,那我们真的没有方法可以直接调用吗?
当然有啦,只是建议你千万不要这样弄,这里只是普及,让你了解一下。
# 调用私有方法,以下两种等价
ins._Kls__private()
ins.call_private()
7、时有时无的切片异常
这是个简单例子
my_list = [1, 2, 3, 4, 5]
print(my_list[5])
Traceback (most recent call last):
File "F:/Python Script/test.py", line 2, in <module>
print(my_list[5])
IndexError: list index out of range
来看看,如下这种写法就不会报索引异常,执行my_list[5:],会返回一个新list:[]。
my_list = [1, 2, 3]
print(my_list[5:])
8、for 死循环
for 循环可以说是 基础得不能再基础的知识点了。但是如果让你用 for 写一个死循环,你会写吗?(问题来自群友 陈**)
这是个开放性的问题,在往下看之前,建议你先尝试自己思考,你会如何解答。
好了,如果你还没有思路,那就来看一下 一个海外 MIT 群友的回答:
for i in iter(int, 1):pass
是不是懵逼了。iter 还有这种用法?这为啥是个死循环?
这真的是个冷知识,关于这个知识点,你如果看中文网站,可能找不到相关资料。
还好你可以通过 IDE 看py源码里的注释内容,介绍了很详细的使用方法。
原来iter有两种使用方法,通常我们的认知是第一种,将一个列表转化为一个迭代器。
而第二种方法,他接收一个 callable对象,和一个sentinel 参数。第一个对象会一直运行,直到它返回 sentinel 值才结束。
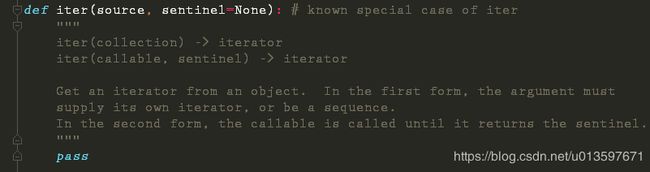
那int 呢,这又是一个知识点,int 是一个内建方法。通过看注释,可以看出它是有默认值0的。你可以在终端上输入 int() 看看是不是返回0。

由于int() 永远返回0,永远返回不了1,所以这个 for 循环会没有终点。一直运行下去。
9、奇怪的字符串
字符串类型作为 Python 中最常用的数据类型之一,Python解释器为了提高字符串使用的效率和使用性能,做了很多优化。
例如:Python 解释器中使用了 intern(字符串驻留)的技术来提高字符串效率。
什么是 intern 机制?就是同样的字符串对象仅仅会保存一份,放在一个字符串储蓄池中,是共用的,当然,肯定不能改变,这也决定了字符串必须是不可变对象。
示例一
# Python2.7
>>> a = "Hello_Python"
>>> id(a)
32045616
>>> id("Hello" + "_" + "Python")
32045616
# Python3.7
>>> a = "Hello_Python"
>>> id(a)
38764272
>>> id("Hello" + "_" + "Python")
32045616
示例二
>>> a = "MING"
>>> b = "MING"
>>> a is b
True
# Python2.7
>>> a, b = "MING!", "MING!"
>>> a is b
True
# Python3.7
>>> a, b = "MING!", "MING!"
>>> a is b
False
示例三
# Python2.7
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False
# Python3.7
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
True
示例四
>>> s1="hello"
>>> s2="hello"
>>> s1 is s2
True
# 如果有空格,默认不启用intern机制
>>> s1="hell o"
>>> s2="hell o"
>>> s1 is s2
False
# 如果一个字符串长度超过20个字符,不启动intern机制
>>> s1 = "a" * 20
>>> s2 = "a" * 20
>>> s1 is s2
True
>>> s1 = "a" * 21
>>> s2 = "a" * 21
>>> s1 is s2
False
>>> s1 = "ab" * 10
>>> s2 = "ab" * 10
>>> s1 is s2
True
>>> s1 = "ab" * 11
>>> s2 = "ab" * 11
>>> s1 is s2
False
10、两次return
我们都知道,try…finally… 语句的用法,不管 try 里面是正常执行还是报异常,最终都能保证finally能够执行。
同时,我们又知道,一个函数里只要遇到 return 函数就会立马结束。
基于以上这两点,我们来看看这个例子,到底运行过程是怎么样的?
>>> def func():
... try:
... return 'try'
... finally:
... return 'finally'
...
>>> func()
'finally'
惊奇的发现,在try里的return居然不起作用。
原因是,在try…finally…语句中,try中的return会被直接忽视,因为要保证finally能够执行。
11、小整数池
>>> a = -6
>>> b = -6
>>> a is b
False
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
>>> a = 257; b = 257
>>> a is b
True
为避免整数频繁申请和销毁内存空间,Python 定义了一个小整数池 [-5, 256] 这些整数对象是提前建立好的,不会被垃圾回收。
以上代码请在 终端Python环境下测试,如果你是在IDE中测试,并不是这样的效果。
那最后一个示例,为啥又是True?
因为当你在同一行里,同时给两个变量赋同一值时,解释器知道这个对象已经生成,那么它就会引用到同一个对象。如果分成两成的话,解释器并不知道这个对象已经存在了,就会重新申请内存存放这个对象。
12、交互式“_”操作符
对于 _ ,我想很多人都非常熟悉。
给变量取名好艰难,用 _;
懒得长长的变量名,用 _;
无用的垃圾变量,用 _;
以上,我们都很熟悉了,今天要介绍的是他在交互式中使用。
>>> 3 + 4
7
>>> _
7
>>> name='ming'
>>> name
'ming'
>>> _
'ming'
>>> 3 + 4
7
>>> _
7
>>> print("ming")
ming
>>> _
7
print函数打印出来的就不行了。用__repr__输出的内容可以被获取到的。
# ming.py
class mytest():
def __str__(self):
return "hello"
def __repr__(self):
return "world"
然后在这个目录下进入交互式环境。
>>> import ming
>>> mt=ming.mytest()
>>> mt
world
>>> print(mt)
hello
>>> _
world
13、优雅的反转字符串/列表
反转序列并不难,但是如何做到最优雅呢?
最简单的方法是使用列表自带的reverse()方法。
>>> ml = [1,2,3,4,5]
>>> ml.reverse()
>>> ml
[5, 4, 3, 2, 1]
>>>mstr1 = 'abc'
>>>ml1 = list(mstr1)
>>>ml1.reverse()
>>>mstr2 = str(ml1)
在这里,介绍一种最优雅的反转方式,使用切片,不管你是字符串,还是列表,简直通杀。
>>> mstr = 'abc'
>>> ml = [1,2,3]
>>> mstr[::-1]
'cba'
>>> ml[::-1]
[3, 2, 1]
14、改变递归次限制
上面才提到递归,大家都知道使用递归是有风险的,递归深度过深容易导致堆栈的溢出。如果你这字符串太长啦,使用递归方式反转,就会出现问题。
那到底,默认递归次数限制是多少呢?
可以使用sys这个库来查看
>>> import sys
>>> sys.getrecursionlimit()
1000
可以查,当然也可以自定义修改次数,退出即失效。不过友情提醒,这玩意还是不要轻易去碰,万一导致系统崩溃了小明可不背锅。
>>> sys.setrecursionlimit(2000)
>>> sys.getrecursionlimit()
2000
15、一行代码实现FTP服务器
如不指定端口,则默认是8000端口。
# python2
python -m SimpleHTTPServer 8888
# python3
python3 -m http.server 8888
SimpleHTTPServer有一个特性,如果待共享的目录下有index.html,那么index.html文件会被视为默认主页;如果不存在index.html文件,那么就会显示整个目录列表。
16、让你晕头转向的 else 用法
先来说说,for else
def check_item(source_list, target):
for item in source_list:
if item == target:
print("Exists!")
break
else:
print("Does not exist")
在往下看之前,你可以思考一下,什么情况下才会走 else。是循环被 break,还是没有break?
给几个例子,你体会一下。
check_item(["apple", "huawei", "oppo"], "oppo")
# Exists!
check_item(["apple", "huawei", "oppo"], "vivo")
# Does not exist
可以看出,没有被 break 的程序才会正常走else流程。
再来看看,try else 用法。
def test_try_else(attr1 = None):
try:
if attr1:
pass
else:
raise
except:
print("Exception occurred...")
else:
print("No Exception occurred...")
同样来几个例子。当不传参数时,就抛出异常。
test_try_else()
# Exception occurred...
test_try_else("ming")
# No Exception occurred...
可以看出,没有 try 里面的代码块没有抛出异常的,会正常走else。
总结一下,for else 和 try else 相同,只要代码正常走下去,不被 break,不抛出异常,就可以走else。
17、空字符串计数
求一个字符串里,某子字符(串)出现的次数。在Python中使用 count() 函数,就可以轻松实现。
比如下面几个常规例子
>>> "aabb".count("a")
2
>>> "aabb".count("b")
2
>>> "aabb".count("ab")
1
但是如果使用空字符串呢,你可能想不到会是这样的结果。
>>> "aabb".count("")
5
>>> "" in ""
True
>>> "" in "ab"
True
18、负负得正
>>> 5-3
2
>>> 5--3
8
>>> 5+-3
2
>>> 5++3
8
>>> 5---3
2
19、数值与字符串比较
在 Python2 中,数字可以与字符串直接比较。结果是数值永远比字符串小。
>>> 100000000 < ""
True
>>> 100000000 < "ming"
True
但在 Python3 中,却不行。
>>> 100000000 < ""
TypeError: '<' not supported between instances of 'int' and 'str'
20、循环中的局部变量泄露
在Python 2中x的值在一个循环执行之后被改变了。
# Python2
>>> x = 1
>>> [x for x in range(5)]
[0, 1, 2, 3, 4]
>>> x
4
不过在Python3 中这个问题已经得到解决了。
# Python3
>>> x = 1
>>> [x for x in range(5)]
[0, 1, 2, 3, 4]
>>> x
1
21、字典可排序
字典不可排序的思想,似乎已经根深蒂固。
# Python2.7.10
>>> mydict = {str(i):i for i in range(5)}
>>> mydict
{'1': 1, '0': 0, '3': 3, '2': 2, '4': 4}
在 Python3 中字典已经是有序的。
# Python3.6.7
>>> mydict = {str(i):i for i in range(5)}
>>> mydict
{'0': 0, '1': 1, '2': 2, '3': 3, '4': 4}
22、链式比较
>>> False == False == True
False
>>> if 18 < age < 60:
print("young man")
young man
>>> False == False and False == True
False
23、+Counter
由于Counter的机制,+ 用于两个 Counter 实例相加,而相加的结果如果元素的个数<= 0,就会被丢弃。
>>> from collections import Counter
>>> ct = Counter('abcdbcaa')
>>> ct
Counter({'a': 3, 'b': 2, 'c': 2, 'd': 1})
>>> ct['c'] = 0
>>> ct['d'] = -2
>>>
>>> ct
Counter({'a': 3, 'b': 2, 'c': 0, 'd': -2})
>>>
>>> +ct
Counter({'a': 3, 'b': 2})
参考:
1、https://www.cnblogs.com/wongbingming/p/10392853.html