tensorflow学习笔记五——过拟合与欠拟合
编程环境:ubuntu14.04LTS+tensorflow1.8.0
我的机器处理imdb数据集太慢。极限模型的一个epoch都要20s,所以这里直接贴上官网的处理结果。
代码中要注意换行,python中不能直接换行,需要使用'\'
1.简介
在前两篇教程:分类影评和预测房价中,我们发现模型的准确度在验证集上随着训练轮数的增加,先达到峰值,然后开始下降。也就是说,训练模型可能过拟合。尽管模型在训练集上有高的准确度,
但是我们的目的时希望在测试集(也就是模型从未处理过的数据)上获得高的准确度,也就是有好
的泛化能力。与之相反的是欠拟合,也就是模型在测试集上的表现仍有提升空间,如果继续训练下去,
模型在测试集上的准确度会提高,也就是模型没有完全学习训练集的数据结构。
训练轮数过多会使得模型过拟合训练数据,从而不能泛化测试数据(一个极端的例子是模型完全复制
训练数据,这样在训练数据上的准确度为1,然而在测试集上会表现很差,因为模型学习的是训练集的
特征,而不是训练集数据的泛化特征)。
因此需要在模型训练过程中找到一个平衡点,使得模型从训练集上学习的特征可以很好的泛化测试集
数据。为防止过拟合,最好的方法是使用更多的训练数据,更多的训练数据,模型更好地学习数据的特
征,因此泛化能力更好。但是更多的训练数据会增加计算代价,或者训练数据很少,也就是当增加训练数
据不可取时,可以采用其他的技巧,如正则化。这些技巧会限制模型可以包含的关于信息的数量和类型,
如果一个模型只能储存少数几个特征,那么优化过程将会更多的关注最明显的特征,从而提升模型的泛化
能力。
这篇教程将会探索权重正则化和丢弃这两种方法,在imdb数据集上测试其效果。
#coding=utf8
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
#载入imdb数据集
NUM_WORDS=10000
(train_data,train_labels),(test_data,test_labels)=keras.datasets.imdb.load_data(num_words=NUM_WORDS)
#使用0-1编码处理数据
#每个数据的域为0-10000整数对应的单词,因此将每个数据
#由[k0,k1,...,kn]ki属于[0-10000],每个数据的n(长度)不同
#转化为[0,1,0,...,1]10000维的向量,若某个单词出现则为1,
#否则为0
def multi_hot_sequences(sequences,dimension):
#创建sequences个维度为dimension的向量
results=np.zeros((len(sequences),dimension))
for i,word_indices in enumerate(sequences):
results[i,word_indices]=1.0
return results
#打印train_data0 长度
print("Original Trian_data0 length:")
print(len(train_data[0]))
#打印train_data0 数据
print("Original Train_data0:")
print(train_data[0])
#multi-hot编码处理train_data和test_data
train_data=multi_hot_sequences(train_data,dimension=NUM_WORDS)
test_data=multi_hot_sequences(test_data,dimension=NUM_WORDS)
#打印multi-hot 处理后的train_data0长度
print("Multi-hot Train_data0 length:")
print(len(train_data[0]))
#打印multi-hot处理后的train_data0
print("Multi-hot Train_data0:")
print(train_data[0])
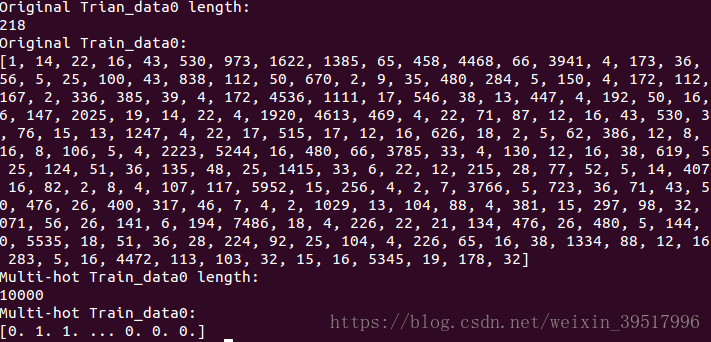
可以看出数据长度由218变为了10000,数据由原来的1-10000的整形数字变为了0-1
二进制数字。
#绘制train_data0的直方图
plt.plot(train_data[0])
#显示
plt.show()
2.过拟合
在深度学习中,模型中可学习的参数通常代表了模型的容纳能力。一个有着更多可学习参数的模型有更多
的储存能力(储存更多的可学习参数),因此可以完美的映射训练数据与标签的对应关系,但是这个映射
没有任何的泛化能力,不能用来预测未见过的数据(测试集)。
需要注意的是,深度学习往往能很好的拟合训练集,但是我们的目的和实际的挑战是泛化而不是拟合。
另一方面,如果模型的储存能力受限,那么它将不能简单的学习训练集与标签的映射。为了最小化损失
,模型会学习压缩表示(理解为高级特征),从而有更好的预测能力。同时,如果模型过小,那么模型将不能
拟合训练数据。
单元,直到模型在验证集上的损失增大。
baseline_model=keras.Sequential([
keras.layers.Dense(16,activation=tf.nn.relu,input_shape=(NUM_WORDS,)),
keras.layers.Dense(16,activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
baseline_model.summary()
baseline_history=baseline_model.fit(train_data,train_labels,epochs=20,
batch_size=512,validation_data=(test_data,test_labels),verbose=2)

#小模型
smaller_model=keras.Sequential([
keras.layers.Dense(4,activation=tf.nn.relu,input_shape=(NUM_WORDS,)),
keras.layers.Dense(4,activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
smaller_model.summary()
smaller_history=smaller_model.fit(train_data,train_labels,epochs=20,
batch_size=512,validation_data=(test_data,test_labels),verbose=2)

#大模型
bigger_model=keras.Sequential([
keras.layers.Dense(512,activation=tf.nn.relu,input_shape=(NUM_WORDS,)),
keras.layers.Dense(512,activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
bigger_history=bigger_model.fit(train_data,train_labels,epochs=20,batch_size=512,validation_data=(test_data,test_labels),verbose=2)
#定义绘图函数
def plot_history(histories,key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name,history in histories:
val=plt.plot(history.epoch,history.history['val'+key],'--',label=name.title()+'Val')
plt.plot(history.epoch,history.history[key],color=val[0].get_color(),label=name.title()+'Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(hsitory.epoch)])
#绘制图像
plot_history([('baseline',baseline_history),('smaller',smaller_history),('bigger',bigger_history)])
注意到大模型刚过了第一轮就过拟合了,并且随着训练轮数增加,过拟合情况越来越严重。
模型的尺寸越大,它对训练数据建模的速度也就越快(导致训练损失很小),也就越容易
过拟合(训练集和验证集上的损失差异大)。
3.过拟合的解决策略
3.1 权重正则化
你一定听说过奥卡姆剃刀:对同一事物的两种解释,越简单的那个越可能是正确的,因为
它基于更少的假设。这个理论同样适用于神经网络的学习过程,对于同一个训练集和标签,
有不同权重和结构的网络都能解释,但是更简单的模型相比与复杂模型往往泛化能力更好
(更少的过拟合训练数据)
更简单的模型这这里指的是参数分布的熵更小(或者模型的参数更少),因此通常防止过拟合
的方法是通过限制权重只能取很小的值来限制网络的复杂程度,使得权重的值更加正则化。这叫做
权重正则化,通过向损失函数中增加一个反映模型复杂程度的代价,这个代价主要有两种:
L1正则化:权重绝对值的线性组合,也叫作权重的L1范数
L2正则化:权重值平方的线性组合,也叫作权重的L2范数。L2正则化在神经网络的语境中也被叫做
权重衰减。
在keras模块中,使用正则化的方法是在指定网络模型时,使用带有正则化参数。
#使用L2正则化建立神经网络模型
#输入层L2正则化,隐藏层使用L2正则化
l2_model=keras.models.Sequential([keras.layers.Dense(16,kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu,input_shape(10000,)),
keras.layers.Dense(16,kernel_regularizer=keras.regularizers.l2(0.001),activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)])
l2_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy','binary_crossentropy'])
l2_model_history=l2_model.fit(train_data,train_labels,epochs=20,batch_size=512,
validation_data=(test_data,test_labels))
plot_history([('baseline',baseline_history),('l2',l2_model_history)])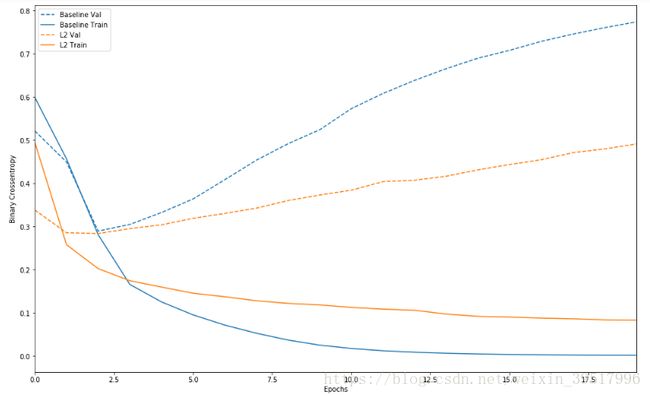
3.2 丢弃
丢弃是一种最常用和最有效的正则化方法,丢弃应用到盛神经网络的一层时,意味指定这一层
的随机丢弃率,也就是在学习过程中,随机丢弃掉学习的特征。假如神经网络的一层对于指定的
输入会输出向量[k1,k2,k3,k4,k5],使用丢弃方法后,输出向量会随机将输出参数按照丢弃率将某
几个设为0,如[0,k2,0,k4,k5]。丢弃率是特征提取中选定设为0的部分占总的特征提取的比率。
#使用随机丢弃训练神经网络
drop_model=keras.Sequantial([keras.layers.Dense(16,activation=tf.nn.relu,input_shape=(10000,)),
keras.layers.Dropout(0.5),keras.layers.Dense(16,activation=tf.nn.relu),keras.layers.Dropout(0.5),
keras.Dense(1,activation=tf.nn.sigmoid)])
drop_model.compile(optimizer='adam',loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
drop_model_history=drop_model.fit(train_data,train_labels,epochs=20,batch_size=512,
validation=(test_data,test_labels),verbose=2)
plot_history([('baseline',baseline_history),('drop',drop_model_history)])