机器学习笔试题精选(一)
https://blog.csdn.net/red_stone1/article/details/80982149
机器学习是一门理论性和实战性都比较强的技术学科。在应聘机器学习相关工作岗位时,我们常常会遇到各种各样的机器学习问题和知识点。为了帮助大家对这些知识点进行梳理和理解,以便能够更好地应对机器学习笔试包括面试。红色石头准备在公众号连载一些机器学习笔试题系列文章,希望能够对大家有所帮助!
Q1. 在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(over-fitting)中影响最大?
A. 多项式阶数
B. 更新权重 w 时,使用的是矩阵求逆还是梯度下降
C. 使用常数项
答案:A
解析:选择合适的多项式阶数非常重要。如果阶数过大,模型就会更加复杂,容易发生过拟合;如果阶数较小,模型就会过于简单,容易发生欠拟合。如果有对过拟合和欠拟合概念不清楚的,见下图所示:

Q2. 假设你有以下数据:输入和输出都只有一个变量。使用线性回归模型(y=wx+b)来拟合数据。那么使用留一法(Leave-One Out)交叉验证得到的均方误差是多少?

A. 10/27
B. 39/27
C. 49/27
D. 55/27
答案:C
解析:留一法,简单来说就是假设有 N 个样本,将每一个样本作为测试样本,其它 N-1 个样本作为训练样本。这样得到 N 个分类器,N 个测试结果。用这 N个结果的平均值来衡量模型的性能。
对于该题,我们先画出 3 个样本点的坐标:

使用两个点进行线性拟合,分成三种情况,如下图所示:
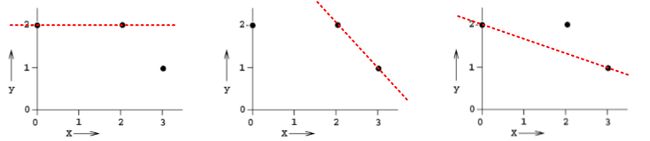
第一种情况下,回归模型是 y = 2,误差 E1 = 1。
第二种情况下,回归模型是 y = -x + 4,误差 E2 = 2。
第三种情况下,回归模型是 y = -1/3x + 2,误差 E3 = 2/3。
则总的均方误差为:
MSE=13 (E 2 1 +E 2 2 +E 2 3 )=13 (1 2 +2 2 +(23 ) 2 )=4927 MSE=13(E12+E22+E32)=13(12+22+(23)2)=4927
Q3. 下列关于极大似然估计(Maximum Likelihood Estimate,MLE),说法正确的是(多选)?
A. MLE 可能并不存在
B. MLE 总是存在
C. 如果 MLE 存在,那么它的解可能不是唯一的
D. 如果 MLE 存在,那么它的解一定是唯一的
答案:AC
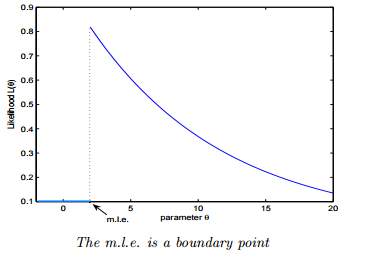
解析:如果极大似然函数 L(θ) 在极大值处不连续,一阶导数不存在,则 MLE 不存在,如下图所示:
 另一种情况是 MLE 并不唯一,极大值对应两个 θ。如下图所示: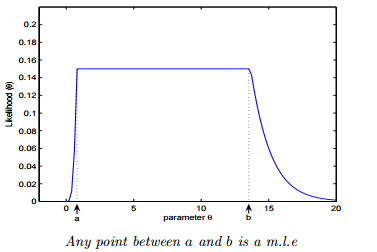 **Q4. 如果我们说“线性回归”模型完美地拟合了训练样本(训练样本误差为零),则下面哪个说法是正确的?** A. 测试样本误差始终为零 B. 测试样本误差不可能为零 C. 以上答案都不对 **答案**:C **解析**:根据训练样本误差为零,无法推断测试样本误差是否为零。值得一提是,如果测试样本样本很大,则很可能发生过拟合,模型不具备很好的泛化能力! **Q5. 在一个线性回归问题中,我们使用 R 平方(R-Squared)来判断拟合度。此时,如果增加一个特征,模型不变,则下面说法正确的是?** A. 如果 R-Squared 增加,则这个特征有意义 B. 如果R-Squared 减小,则这个特征没有意义 C. 仅看 R-Squared 单一变量,无法确定这个特征是否有意义。 D. 以上说法都不对 **答案**:C **解析**:线性回归问题中,R-Squared 是用来衡量回归方程与真实样本输出之间的相似程度。其表达式如下所示: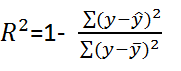 上式中,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。根据 R-Squared 的取值,来判断模型的好坏:如果结果是 0,说明模型拟合效果很差;如果结果是 1,说明模型无错误。一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着样本数量的增加,R-Square必然增加,无法真正定量说明准确程度,只能大概定量。 对于本题来说,单独看 R-Squared,并不能推断出增加的特征是否有意义。通常来说,增加一个特征,R-Squared 可能变大也可能保持不变,两者不一定呈正相关。 如果使用校正决定系数(Adjusted R-Square):
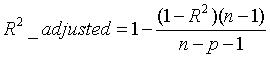 其中,n 是样本数量,p 是特征数量。Adjusted R-Square 抵消样本数量对 R-Square的影响,做到了真正的 0~1,越大越好。 **Q6. 下列关于线性回归分析中的残差(Residuals)说法正确的是?** A. 残差均值总是为零 B. 残差均值总是小于零 C. 残差均值总是大于零 D. 以上说法都不对 **答案**:A **解析**:线性回归分析中,目标是残差最小化。残差平方和是关于参数的函数,为了求残差极小值,令残差关于参数的偏导数为零,会得到残差和为零,即残差均值为零。 **Q7. 下列关于异方差(Heteroskedasticity)说法正确的是?** A. 线性回归具有不同的误差项 B. 线性回归具有相同的误差项 C. 线性回归误差项为零 D. 以上说法都不对 **答案**:A **解析**:异方差性是相对于同方差(Homoskedasticity)而言的。所谓同方差,是为了保证回归参数估计量具有良好的统计性质,经典线性回归模型的一个重要假定:总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,即:随机误差项具有不同的方差,则称线性回归模型存在异方差性。 通常来说,奇异值的出现会导致异方差性增大。 **Q8. 下列哪一项能反映出 X 和 Y 之间的强相关性?** A. 相关系数为 0.9 B. 对于无效假设 β=0 的 p 值为 0.0001 C. 对于无效假设 β=0 的 t 值为 30 D. 以上说法都不对 **答案**:A **解析**:相关系数的概念我们很熟悉,它反映了不同变量之间线性相关程度,一般用 r 表示。
r(X,Y)=Cov(X,Y)Var[X]Var[Y] − − − − − − − − − − − − √ r(X,Y)=Cov(X,Y)Var[X]Var[Y]
其中,Cov(X,Y) 为 X 与 Y 的协方差,Var[X] 为 X 的方差,Var[Y] 为 Y 的方差。r 取值范围在 [-1,1] 之间,r 越大表示相关程度越高。A 选项中,r=0.9 表示 X 和 Y 之间有较强的相关性。
而 p 和 t 的数值大小没有统计意义,只是将其与某一个阈值进行比对,以得到二选一的结论。例如,有两个假设:
-
无效假设(null hypothesis)H0:两参量间不存在“线性”相关。
-
备择假设(alternative hypothesis)H1:两参量间存在“线性”相关。
如果阈值是 0.05,计算出的 p 值很小,比如为 0.001,则可以说“有非常显著的证据拒绝 H0 假设,相信 H1 假设。即两参量间存在“线性”相关。p 值只用于二值化判断,因此不能说 p=0.06 一定比 p=0.07 更好。
Q9. 下列哪些假设是我们推导线性回归参数时遵循的(多选)?
A. X 与 Y 有线性关系(多项式关系)
B. 模型误差在统计学上是独立的
C. 误差一般服从 0 均值和固定标准差的正态分布
D. X 是非随机且测量没有误差的
答案:ABCD
解析:在进行线性回归推导和分析时,我们已经默认上述四个条件是成立的。
Q10. 为了观察测试 Y 与 X 之间的线性关系,X 是连续变量,使用下列哪种图形比较适合?
A. 散点图
B. 柱形图
C. 直方图
D. 以上都不对
答案:A
解析:散点图反映了两个变量之间的相互关系,在测试 Y 与 X 之间的线性关系时,使用散点图最为直观。
Q11. 一般来说,下列哪种方法常用来预测连续独立变量?
A. 线性回归
B. 逻辑回顾
C. 线性回归和逻辑回归都行
D. 以上说法都不对
答案:A
解析:线性回归一般用于实数预测,逻辑回归一般用于分类问题。
Q12. 个人健康和年龄的相关系数是 -1.09。根据这个你可以告诉医生哪个结论?
A. 年龄是健康程度很好的预测器
B. 年龄是健康程度很糟的预测器
C. 以上说法都不对
答案:C
解析:因为相关系数的范围是 [-1,1] 之间,所以,-1.09 不可能存在。
Q13. 下列哪一种偏移,是我们在最小二乘直线拟合的情况下使用的?图中横坐标是输入 X,纵坐标是输出 Y。

A. 垂直偏移(vertical offsets)
B. 垂向偏移(perpendicular offsets)
C. 两种偏移都可以
D. 以上说法都不对
答案:A
解析:线性回归模型计算损失函数,例如均方差损失函数时,使用的都是 vertical offsets。perpendicular offsets 一般用于主成分分析(PCA)中。
Q14. 假如我们利用 Y 是 X 的 3 阶多项式产生一些数据(3 阶多项式能很好地拟合数据)。那么,下列说法正确的是(多选)?
A. 简单的线性回归容易造成高偏差(bias)、低方差(variance)
B. 简单的线性回归容易造成低偏差(bias)、高方差(variance)
C. 3 阶多项式拟合会造成低偏差(bias)、高方差(variance)
D. 3 阶多项式拟合具备低偏差(bias)、低方差(variance)
答案:AD
解析:偏差和方差是两个相对的概念,就像欠拟合和过拟合一样。如果模型过于简单,通常会造成欠拟合,伴随着高偏差、低方差;如果模型过于复杂,通常会造成过拟合,伴随着低偏差、高方差。
用一张图来形象地表示偏差与方差的关系:

图片来源:https://www.zhihu.com/question/27068705
偏差(bias)可以看成模型预测与真实样本的差距,想要得到 low bias,就得复杂化模型,但是容易造成过拟合。方差(variance)可以看成模型在测试集上的表现,想要得到 low variance,就得简化模型,但是容易造成欠拟合。实际应用中,偏差和方差是需要权衡的。若模型在训练样本和测试集上都表现的不错,偏差和方差都会比较小,这也是模型比较理想的情况。
Q15. 假如你在训练一个线性回归模型,有下面两句话:
1. 如果数据量较少,容易发生过拟合。
2. 如果假设空间较小,容易发生过拟合。
关于这两句话,下列说法正确的是?
A. 1 和 2 都错误
B. 1 正确,2 错误
C. 1 错误,2 正确
D. 1 和 2 都正确
答案:B
解析:先来看第 1 句话,如果数据量较少,容易在假设空间找到一个模型对训练样本的拟合度很好,容易造成过拟合,该模型不具备良好的泛化能力。
再来看第 2 句话,如果假设空间较小,包含的可能的模型就比较少,也就不太可能找到一个模型能够对样本拟合得很好,容易造成高偏差、低方差,即欠拟合。
参考文献:
https://www.analyticsvidhya.com/blog/2016/12/45-questions-to-test-a-data-scientist-on-regression-skill-test-regression-solution/