利用Python爬取全国250m精度的人口数据、房价数据等数据 | CSDN博文精选

作者 | 中原百科 来源 | CSDN博客
(一)
我的第一篇博客写的就是爬取人口数据基于腾讯位置大数据平台的全球移动定位数据获取(Python爬取),精度是1000m,后来有朋友和我说有个网站开放过250m精度的人口分布数据,而且人口分布有年龄分段等属性。
 看人口专题分类1
看人口专题分类1
 看人口专题分类2
看人口专题分类2
所以我决定试一下能不能爬到这个网站的人口信息,首先得注册登录到达创建地图的界面,可以看到如下网页,人口数据可以按照行政区来显示:
 按行政区分布人口
按行政区分布人口
如果放大的话可以看到精确到250m格网的人口数据,不同的放大级别的爬取方法不一样,这里我就主要分析下如何爬取格网的数据。
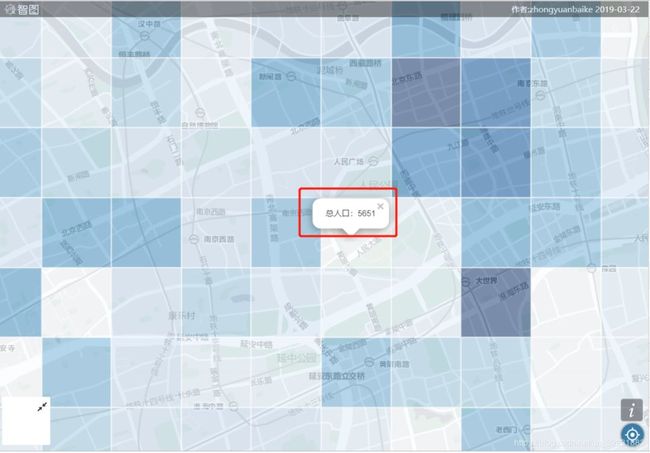 格网尺度人口分布
格网尺度人口分布
其实去年该网站开放过api,可以通过api获取人口数据 (结果图如下,比1000m精度的更加精细)
但是现在接口已经关闭,也没办法再去申请key。而且好像通过以前的key还可以抓数据,但是返回数据的大小有限制,这里我们通过自行抓包分析如何爬取人口数据。
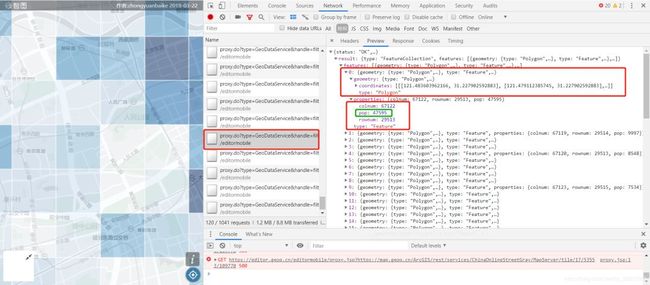
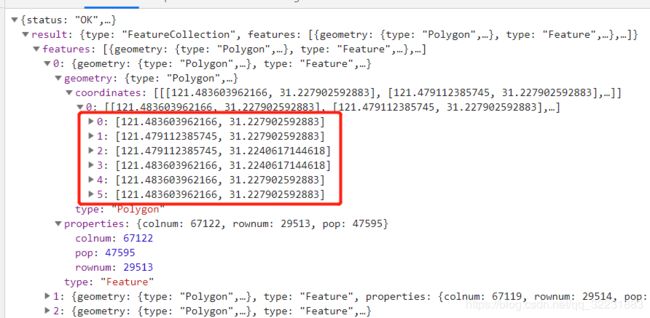 红框中是格网的shape坐标
红框中是格网的shape坐标
我们查看Header, 即可知道url和参数
网页分析好了之后写代码就容易了,下面代码我只是获取的8000m精度的格网,范围是南京市,代码仅仅用来测试。而且一开始我是获取成表格数据,经纬度和人口数存成excel。
0-11是格网图形坐标,12是人口数
 爬取到的网格人口
爬取到的网格人口
但是后来一想这么做费力不讨好,因为features就是一种geojson格式的数据,其实可以直接保存成json格式数据,然后直接转成shp,里面的属性信息也全部保存,岂不美哉!
response = requests.request('POST', url, data=values)
print(response.url)
datas=response.text
dictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式
result=dictdatas['result']
features=result['features']
time.sleep(0.001)
c1 = pd.DataFrame(features)
c1.to_json('GeoqPop.json')
以上其实抓的都是一定范围内的数据,比如那个extent,就是南京市的范围,配合着的是8000m精度的格网。
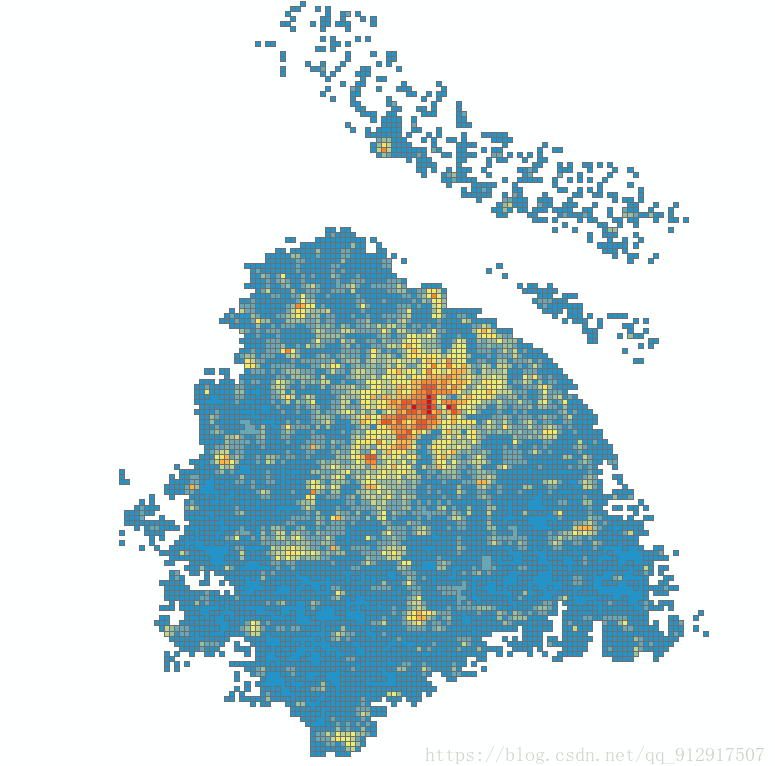
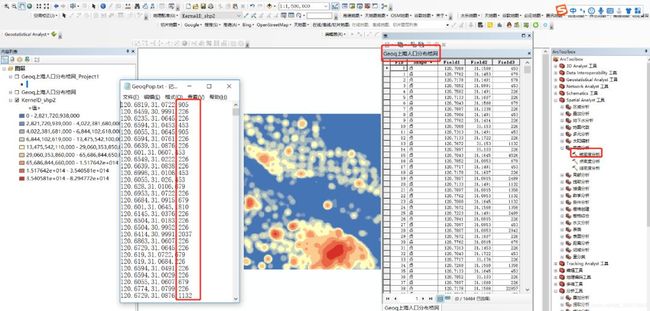
"extent":"[117.73498535156251,31.03834440994876,119.92675781250001,32.722136436046284]",若想获得全国的格网,则需要按照extent和radius的规律写个循环即可,这里不再赘述(下篇文章详细讲解)。另外下图是随便选择经纬度范围获取的格网中心点集合(上海地区):
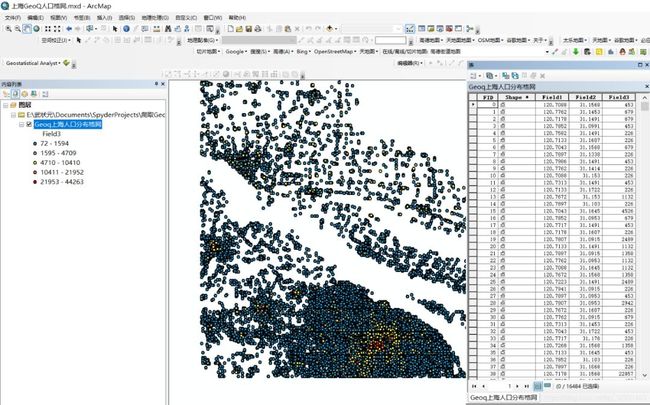
定义成北京 坐标系之后,我查看了下格网中心点之间距离428m,根本不是250m,求解释。

当然这个网站还有其他很棒的数据,比如全国房价格网数据:
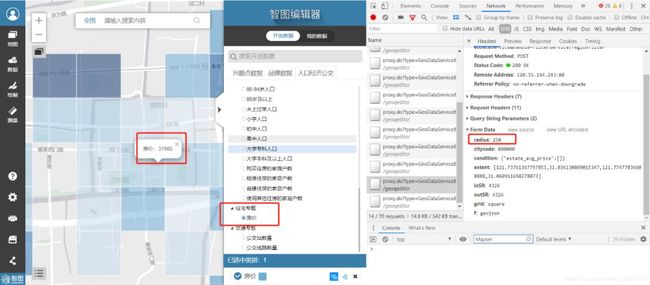
全国房价数据
全国公交站点和公交线路的数据
 全国公交站点格网数据
全国公交站点格网数据
当然了,这个网站其他数据获取方法都是大同小异的,大家可以亲手试一试。
(二)
接着介绍如何爬取全国数据
import requests
import json
import pandas as pd
import time
#地图范围 73.063112,2.995764,135.172386,53.802238
header = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'origin':'origin: https://editor.geoq.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Connection': 'keep-alive',
'Referer': '你自己创建的链接'
}
def get_data(radius=250,step=0.1,xmin=73.06,xmax=135.17,ymin=2.99,ymax=53.81):
xlen=round((xmax-xmin)/step)
ylen=round((ymax-ymin)/step)
print(xlen)
print(ylen)
x1=xmin
x2=xmin+step
y1=ymin
y2=ymin+step
num=0
for i in range(1,xlen):
start_i = time.clock()
for j in range(1,ylen):
time.sleep(0.001)
values={
"citycode":"000000",
"extent":"["+str(x1)+","+str(y1)+","+str(x2)+","+str(y2)+"]",
"inSR":"4326",
"outSR":"4326",
"grid":"square",
"radius":str(radius),
"f":"geojson",
"condition":'{"pop":[]}'
}
url='https://editor.geoq.cn/editormobile/proxy.do?type=GeoDataService&handle=filterservice/regionfilter'
response = requests.request('POST', url, data=values,headers = header)
datas=response.text
dictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式
result=dictdatas['result']
features=result['features']
#time.sleep(0.001)
#c1 = pd.DataFrame(features)
#c1.to_json('GeoqPop.json')
tem=[]
for m in range(0,len(features)):
geometry=features[m]['geometry']
coordinates=geometry['coordinates']
properties=features[m]['properties']
pop=properties['pop']
point=coordinates[0]
p0x=point[0][0]
p0y=point[0][1]
p1x=point[1][0]
p1y=point[1][1]
p2x=point[2][0]
p2y=point[2][1]
p3x=point[3][0]
p3y=point[3][1]
centerx=(p0x+p1x+p2x+p3x)/4
centery=(p0y+p1y+p2y+p3y)/4
tem.append([round(centerx,4),round(centery,4),pop])
c = pd.DataFrame(tem)
c.to_csv('GeoqChinaPop.txt',mode='a',index = False,header=None,encoding='utf-8-sig')
x1=xmin+i*step
y1=ymin+j*step
x2=xmin+(i+1)*step
y2=ymin+(j+1)*step
num+=1
print("当前正在爬取网格大小为"+str(radius)+"m精度的人口数据,目前爬取到第"+str(j)+"行第"+str(i)+"列,"+"总共爬取了"+str(100*num/(xlen*ylen))+"%")
elapsed_i = (time.clock() - start_i)
print("爬取第"+str(i)+"列用时:"+str(elapsed_i))
if __name__ =='__main__':
start = time.clock()
get_data(250,0.1,73.06,135.17,17.50,54.22)
end = time.clock()
t=end-start
print("程序总共耗时:"+str(t))
可以利用get_data(250,0.1,73.06,135.17,17.50,54.22)这个函数来爬取全国的数据,范围是全国,为了避免漏掉数据,所以extent范围还是主动扩大了一些(这导致一开始可能会爬到很多空数据,消耗时间)按照全国这个范围,0.1度 循环下去,一共621列367行,一行测试出来爬取时间是262秒,如果要爬取全部一共要691天哈哈。
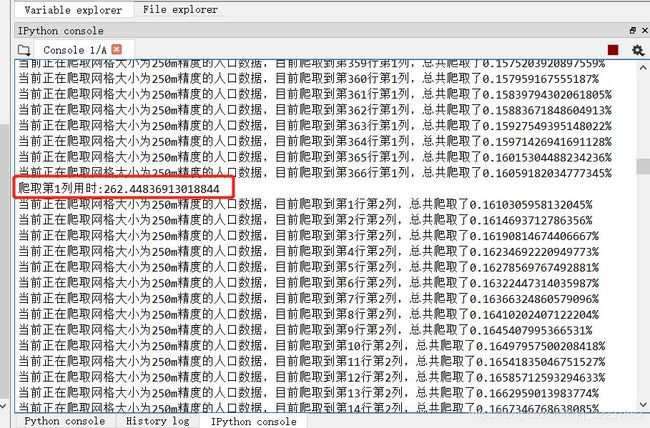
看来应该搞一个分布式了,这样太慢了,这里暂时先不管了,以后有时间再说。
还是先搞一个南京的吧,其他城市的我暂时也不需要,按照城市来的话挺快的。爬取第18列用时:6.261595580461972s;程序总共耗时:156.5806489491781s
其实如果想爬其他数据也很简单,只要把参数换一下,然后查看其response数据格式,和人口的一模一样

# -*- coding: utf-8 -*-
"""
Created on Thu Mar 28 17:11:01 2019
@author: 武状元
"""
import requests
import json
import pandas as pd
import time
#地图范围 73.063112,2.995764,135.172386,53.802238
header = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'origin':'origin: https://editor.geoq.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Connection': 'keep-alive',
'Referer': '你自己的链接'
}
def get_data(radius=250,step=0.1,xmin=73.06,ymin=2.99,xmax=135.17,ymax=53.81):
xlen=round((xmax-xmin)/step)
ylen=round((ymax-ymin)/step)
print(xlen)
print(ylen)
x1=xmin
x2=xmin+step
y1=ymin
y2=ymin+step
num=0
for i in range(1,xlen):
start_i = time.clock()
for j in range(1,ylen):
time.sleep(0.001)
values={
"citycode":"000000",
"extent":"["+str(x1)+","+str(y1)+","+str(x2)+","+str(y2)+"]",
"inSR":"4326",
"outSR":"4326",
"grid":"square",
"radius":str(radius),
"f":"geojson",
"condition":'{"estate_avg_price":[]}'
}
url='https://editor.geoq.cn/editormobile/proxy.do?type=GeoDataService&handle=filterservice/regionfilter'
response = requests.request('POST', url, data=values,headers = header)
datas=response.text
dictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式
result=dictdatas['result']
features=result['features']
tem=[]
for m in range(0,len(features)):
geometry=features[m]['geometry']
coordinates=geometry['coordinates']
properties=features[m]['properties']
estate_avg_price=properties['estate_avg_price']
point=coordinates[0]
p0x=point[0][0]
p0y=point[0][1]
p1x=point[1][0]
p1y=point[1][1]
p2x=point[2][0]
p2y=point[2][1]
p3x=point[3][0]
p3y=point[3][1]
centerx=(p0x+p1x+p2x+p3x)/4
centery=(p0y+p1y+p2y+p3y)/4
tem.append([round(centerx,4),round(centery,4),estate_avg_price])
c = pd.DataFrame(tem)
c.to_csv('GeoqPrice_nanjing.txt',mode='a',index = False,header=None,encoding='utf-8-sig')
x1=xmin+i*step
y1=ymin+j*step
x2=xmin+(i+1)*step
y2=ymin+(j+1)*step
num+=1
print("当前正在爬取网格大小为"+str(radius)+"m精度的平均房价数据,目前爬取到第"+str(j)+"行第"+str(i)+"列,"+"总共爬取了"+str(100*num/(xlen*ylen))+"%")
elapsed_i = (time.clock() - start_i)
print("爬取第"+str(i)+"列用时:"+str(elapsed_i))
if __name__ =='__main__':
start = time.clock()
get_data(250,0.1,117.66467283479871,31.03457902411351,119.60650633089246,32.71843925265175)
#get_data(250,0.1,73.06,17.50,135.17,54.22)
end = time.clock()
t=end-start
print("程序总共耗时:"+str(t))
之后测试大概用了178秒,南京250m格网房价数据爬取完毕。
原文链接:
https://blog.csdn.net/qq_32231883/article/details/88870167
◆
精彩推荐
◆
「2019 AI开发者大会」 除了邀请国内外一线公司重磅嘉宾外,还邀请到了亚马逊首席科学家@李沐,他将于9月5日亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。

 推荐阅读:
推荐阅读:
开源之战
谁偷偷删了你的微信?别慌!Python帮你都揪出来了
吐血整理!140种Python标准库、第三方库和外部工具都有了
如何用爬虫技术帮助孩子秒到心仪的幼儿园(基础篇)
Python传奇:30年崛起之路
干货 | Python后台开发的高并发场景优化解决方案
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
阿里巴巴杨群:高并发场景下Python的性能挑战