CSDN爬虫(一)——爬虫入门+数据总览
CSDN爬虫(一)——爬虫入门+数据总览
首先感谢webMagic的作者黄亿华以及Jsoup的开发人员。
说明
- 开发环境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬虫框架:webMagic
- 建议:建议首先阅读webMagic的文档,再查看此系列文章,便于理解,快速学习:http://webmagic.io/
- 开发所需jar下载(不包括数据库操作相关jar包):点我下载
- 该系列文章会省略webMagic文档已经讲解过的相关知识。
博主信息抓取核心代码预览
package com.wgyscsf.spider;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import com.wgyscsf.utils.MyStringUtils;
/**
* @author 高远
* 编写日期 2016-9-24下午7:25:36
* 邮箱 [email protected]
* 博客 http://blog.csdn.net/wgyscsf
* TODO
*/
public class CsdnBlogAuthorSpider implements PageProcessor {
private Site site = Site
.me()
.setDomain("blog.csdn.net")
.setSleepTime(300)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
// 列表页: 这里进行匹配,匹配出列表页进行相关处理。在列表页我们获取必要信息,对于全文、评论、顶、踩在文章详情中。
if (page.getUrl().regex("^http://blog.csdn.net/((?!/).)*$").match()) {
/*
* header
*/
Selectable titleSelectable = page.getHtml().xpath(
"//div[@class=\"header\"]//div[@id=\"blog_title\"]");
String blogUrl = titleSelectable.links().get();
// 作者id
String id_author = MyStringUtils.getLastSlantContent(blogUrl);
// 博客标题
String title = titleSelectable.xpath("//a//text()").get();
// 描述
String describe = titleSelectable.xpath("//h3//text()").get();
/*
* 获取个人资料模块
*/
Selectable profileSelectable = page.getHtml().xpath(
"//ul[@class=\"panel_body profile\"]");
// 获取博主名字,打印结果可以看出不是博主名字,而是用户id,这个应该是动态显示的,还不能解决。
String name = profileSelectable.xpath("//span/text()").toString();
// 头像
String headImg = profileSelectable.xpath("//a//img/@src")
.toString();
// System.out.println(headImg);
/*
* 获取个人成就模块
*/
Selectable medalSelectable = profileSelectable
.xpath("//div[@id=\"blog_medal\"]");
// 是否是博客专家
boolean isBlogExpert = false;
// 获取其它头衔
boolean isColumnUp = false;
boolean isPreBlogExpert = false;
boolean isPersist = false;
boolean isBlogStars = false;
boolean isMicrMvp = false;
// 是否是博客专家
Selectable expert = medalSelectable
.xpath("//div[@class='ico_expert']//@title");
if (expert.match())
if (expert.equals("CSDN认证专家")) {
isBlogExpert = true;
} else if (expert.equals("CSDN博客准专家")) {
isPreBlogExpert = true;
}
// 头衔模块判断
Selectable selectable = medalSelectable
.xpath("//div[@id='bms_box']//a//img//@src");
if (selectable.match()) {
List honor = selectable.all();
List mHonor = processHonor(honor);
// System.out.println(mHonor);
for (String string : mHonor) {
if (string.equals("zhuanlandaren.png"))
isColumnUp = true;
else if (string.equals("chizhiyiheng.png"))
isPersist = true;
else if (string.equals("bokezhixing.png"))
isBlogStars = true;
else if (string.equals("weiruanmvp.png"))
isMicrMvp = true;
}
}
/*
* 排名模块
*/
Selectable rankSelectable = profileSelectable
.xpath("//ul[@id=\"blog_rank\"]");
//以jsoup的方式进行解析
Elements allElements = new Html(rankSelectable.get()).getDocument().getAllElements().get(0).getElementsByTag("li");
// 浏览量
String viewNums = allElements.get(0).getElementsByTag("span")
.text();
viewNums = viewNums.substring(0, viewNums.length() - 1);
// 积分
String points = allElements.get(1).getElementsByTag("span")
.text();
// 排名
String rank = allElements.get(3).getElementsByTag("span").text();
rank = MyStringUtils.getStringPureNumber(rank);
/*
* 博客数量模块
*/
Selectable statisSelectable = profileSelectable
.xpath("//ul[@id=\"blog_statistics\"]");
// 以jsoup的方式进行解析
Elements statisElements = new Html(statisSelectable.get())
.getDocument()
.getAllElements().get(0).getElementsByTag("li");
// 原创量
String originalNums = statisElements.get(0)
.getElementsByTag("span")
.text();
originalNums = MyStringUtils.getStringPureNumber(originalNums);
// 转载量
String repuishNums = statisElements.get(1).getElementsByTag("span")
.text();
repuishNums = MyStringUtils.getStringPureNumber(repuishNums);
// 译文量
String translateNums = statisElements.get(2)
.getElementsByTag("span")
.text();
translateNums = MyStringUtils.getStringPureNumber(translateNums);
// 评论量
String commentNums = statisElements.get(3).getElementsByTag("span")
.text();
commentNums = MyStringUtils.getStringPureNumber(commentNums);
// 测试打印
System.out.println("博主id:" + id_author + ",博客标题:" + title
+ ",博客描述:" + describe + ",浏览量:" + viewNums + ",原创文章数:"
+ originalNums + ",博客积分:" + points + ",(其它信息未打印)");
}
}
/**
* 获取后缀名
*/
private List processHonor(List honor) {
List str = new ArrayList<>();
for (String string : honor) {
str.add(MyStringUtils.getLastAfterSprit(string));
}
return str;
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CsdnBlogAuthorSpider())
.addUrl("http://blog.csdn.net/" + "wgyscsf")
.run();
}
}
关键代码解释
page.getUrl().regex("^http://blog.csdn.net/((?!/).)*$").match()这句话是一个正则表达式,作用是过滤出以http://blog.csdn.net/开头的网址,并且该网址后面不能再含有“/”这样的字符。因为我们观察CSDN的博客会发现,在http://blog.csdn.net/后面紧跟的一串字符(数字+字母)就是用户的id,不会再后其他“/”多更的信息。只要符合该规则都会进入到爬虫队列。Selectable titleSelectable = page.getHtml().xpath("//div[@class=\"header\"]//div[@id=\"blog_title\"]");这句话是为了获取博客“头部”的节点信息,里面包含作者id、博客标题、博客描述等信息。Elements allElements = new Html(rankSelectable.get()).getDocument().getAllElements().get(0).getElementsByTag("li");代码中有大量的这样类似的代码,在webMagic中是没有的,需要特别注意,这是jsoup风格的代码,在jsoup中是以“节点”进行操作的,所有html元素全部以节点进行处理,有时候比较方便。new Html(rankSelectable.get()).getDocument().getAllElements()就是将webMagic处理的方式转化为了jsoup的方式进行处理的关键代码。.addPipeline(null)这代码片段可以将控制台打印的网址过滤掉。
数据预览
- CSDN用户数据,跑了大致两天的数据量
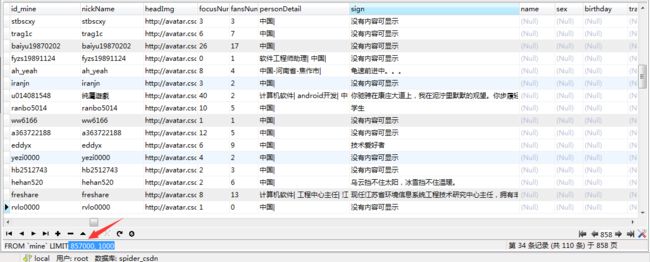
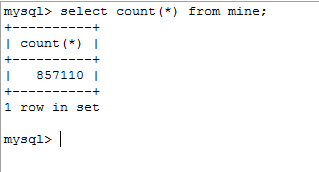
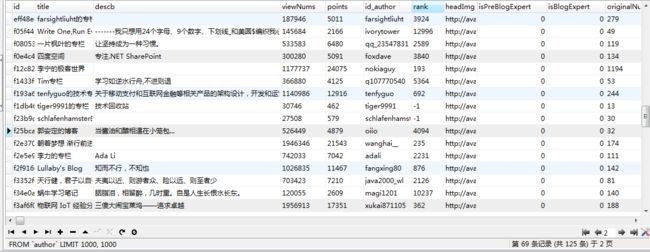
- CSDN博主数据,刚开始

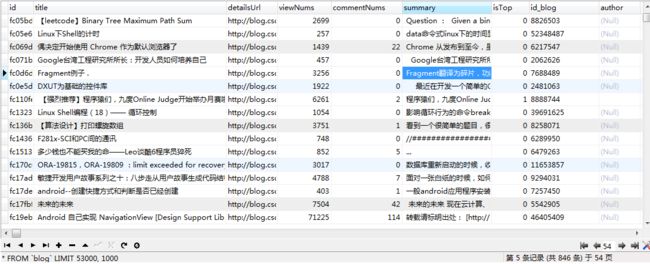
- CSDN博数据,刚开始,电脑有点扛不住,数据量巨大

操作代码及webMagic源码下载
http://download.csdn.net/detail/wgyscsf/9644613
个人公众号,及时更新技术文章
