BDS-HA:构建高可用、低延迟的HBase服务
HBase可以支持百TB数据规模、数百万QPS压力下的毫秒响应,适用于大数据背景下的风控和推荐等在线场景。阿里云HBase服务了多家金融、广告、媒体类业务中的风控和推荐,持续的在高可用、低延迟、低成本方向上进行优化。目前单集群承诺可用性99.9%,SSD机型上可以做到请求毛刺99.5% < 50ms,以及新上线的表内冷热分离可以加速热数据访问性能、减少冷数据存储成本并且在API上对用户透明。为了进一步满足客户在可用性以及低延迟上的诉求,阿里云HBase将提供以主备架构为平台,以冗余、并发、隔离、降级等全方位服务为支撑的高可用解决方案,目标提供99.99%可用性、99.9%请求小于50ms。目前高可用项目一期已经完成,本文将介绍主备架构以及一键切换能力。
HBase单集群可用性
一个HBase系统包含了Zookeeper、HDFS、HBase三个组件。其中Zookeeper在数据和计算上都进行了冗余,且是一个可自愈系统,单节点故障可在秒级恢复。HBase对Zookeeper是轻依赖,一般不会出现大问题。HDFS是一个Master-Slave模式的分布式文件系统,存在中心节点Namenode,Namenode支持以HA方式部署,单Namenode故障可秒级恢复,在两个NN都宕机的情况下依然可以重启自愈,但恢复时间取决于回放日志大小,在分钟级别。数据多副本冗余,Datanode单节点宕机不中断服务。HBase也是一个Master-Slave模式的分布式系统,其中HMaster不参与读写路径,因此HMaster宕机不中断服务,但长期宕机会影响负载均衡、Failover等能力,HMaster支持HA方式部署。HBase还有一个单点是Meta服务,它随机选择一个RegionServer节点作为宿主,如果meta服务不可用则所有请求路由会失效,导致整体不可用。由于客户端有路由缓存,meta服务停机不会立即造成不可用。HBase数据分片使用Range Partition的方式,每一个Region由一个RegionServer服务,即HBase的计算服务是0冗余,因此当RegionServer故障时多个分片不可服务。HBase Failover机制可以自愈,单RegionServer宕机恢复时间在分钟级,多个RegionServer宕机恢复时间在10分钟~1小时时间不等。
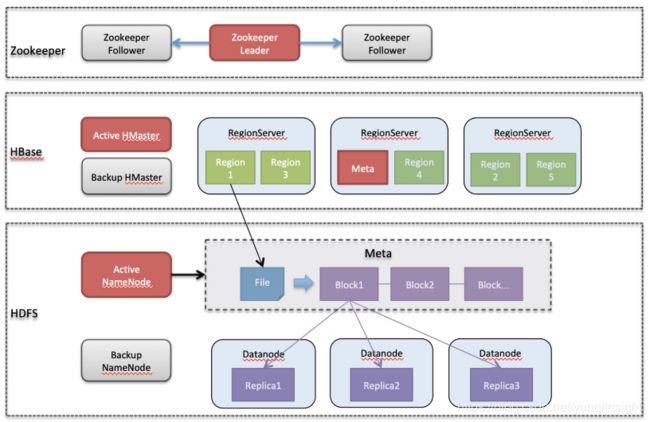
单集群HBase高可用部署
| 组件 | 角色 | 高可用机制 | 故障影响 |
|---|---|---|---|
| Zookeeper | 数据、计算冗余 | 单点宕机秒级服务 | |
| HDFS | Namenode | 双节点HA部署 | 单点宕机秒级恢复,双节点宕机恢复时间在分钟级 |
| Datanode | 数据、计算冗余 | 单点宕机不中断服务 | |
| HBase | HMaster | 双节点HA部署 | 不影响数据读写 |
| Meta服务 | 单点,可自愈 | 影响全局不可用 | |
| Region | 单点,可自愈 | 局部不可用,单点分钟级恢复,多点恢复时间可达小时级别 |
内核或运行环境Bug造成HBase自愈不可控
case1 某金融公司自建HBase因ECS重启导致WAL数据破坏,HBase Failover无法进行,集群不可用无法自愈
case2 某视频公司自建HBase集群Meta数据陷入不一致无法恢复,造成分区无法上线,部分表不可用无法自愈
case3 某媒体公司IO压力较大经常触发空间泄漏Bug,导致空间不足集群宕机无法自愈
以上是真实的案例,Bug是不可避免的,未知Bug处理考验内核团队的技术实力,需要具备外科手术的能力,但其处理时间是不可预期的。
云HBase主备高可用方案
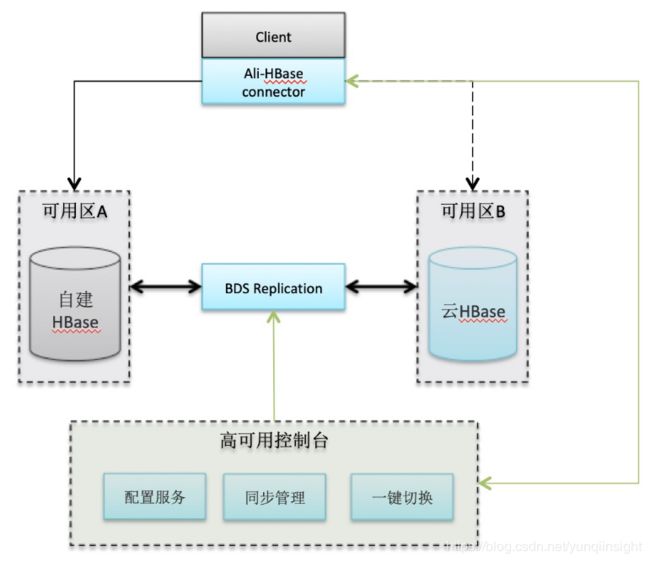
故障恢复时间可预知的高可用系统,故障发生时可以在分钟级别恢复读写能力。实现方案选择经典的主备模式,也支持主主模式。备集群部署在同城的不同机房内,在资源层面完全隔离,软件可部署不同的版本,最大程度保持两个集群的独立性。从经验数据出发,单机房故障恢复时间的上限为1个小时,在这1个小时内另一个机房也发生故障的概率非常低,有两种情况除外:第一种是城市级灾难,这个需要异地容灾方案;第二种是故障源于业务流量增长,系统过载,此时的解决方案是限流或者扩容。这两种情况不在本文设计考虑之内。系统提供一键切换能力,不需要客户端重启,每一个客户端在收到切换信号时会自动完成连接的切换,客户端的切换是并发进行的,所有客户端可以在10秒内完成切换。
高可用方案可以独立提供给自建使用,支持自建和云HBase混合主备。如果你已经拥有一个HBase集群,可以方便的弹出一个冗余备集群,备集群的建表和数据复制都是自动完成。当故障发生时,可以在控制台切换流量到备库,待主集群恢复后再把流量切回。云HBase高可用服务是一个独立的服务,可以看做是基于HBase之上的一个中间件,支持混合云是我们的设计原则,云上同VPC下的自建HBase、EMR HBase、云HBase可以方便的进行主备混合使用,对于IDC自建HBase或者它云上的HBase则需要用户自行解决网络联通。
简单易用,HBase客户端从普通模式转化为高可用模式不需要修改代码。云HBase会提供一个插件集成到HBase客户端,并且为高可用提供一个新的Endpoint。这个Endpoint就是简单的 ip+port,用来替换单集群模式下的Zookeeper地址。用户可以选择核心表进行高可用建设,非核心表依然保持单集群来降低成本。对于高可用的表,可以通过高可用客户端进行创建、修改和删除,控制台会保证主备集群元数据的一致性。目前我们支持0.96、0.98、1.x、2.x、云HBase增强版等多个版本。
| 0.96 | 1.x | 2.x | 云增强版 | |
|---|---|---|---|---|
| 0.96 | YES | NO | NO | YES |
| 1.x | NO | YES | YES | YES |
| 2.x | NO | YES | YES | YES |
| 云增强版 | YES | YES | YES | YES |
版本主备兼容性列表
综上所述,云HBase主备高可用架构如下图:
- 数据同步
云HBase并没有采用开源的Replication方案,主要的原因包括:
HBase Replication抗热点能力差,每台机器只能处理自己的日志
HBase Replication Failover的设计存在缺陷,导致一旦RS宕机就会出现长时间同步延迟
HBase Replication与内核争抢资源,无法独立扩容
HBase Replication的管理依赖表属性配置,配置项很多,在混合云模式下很难维护
BDS Replication是一个独立的数据复制服务,提供延迟百毫秒级别的双向数据同步能力。BDS Replication可以独立的扩容缩容,它不需要磁盘,可以更好的管理成本。
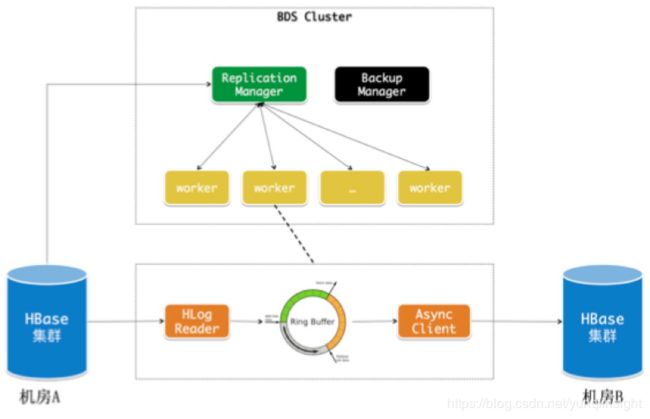
- 主备一致性
云HBase主备采用的是异步复制,提供基于版本的最终一致性。写入主库的一行数据在同步到备库时,会保持和主库一致的版本号。云HBase高可用目前仅支持最终一致性切换,在切换时主备可能存在秒级的不一致。对于风控、推荐、画像类的应用,最终一致性是满足需求的。如果您使用了CheckAndPut、CheckAndDelete这样的接口则会出现一致性问题,此种情况请联系云HBase提供技术咨询。
- 配置服务
配置服务有两个作用,存储主备集群的地址信息和通知切换命令。高可用客户端在启动时会访问该服务加载主备集群地址信息。通过控制台执行的切换命令也会由配置服务通知所有的客户端。配置服务本身采用了冗余来保障存储和消息的高可用。
- 监控
高可用服务可以实时显示主备集群的状态。主、备角色在初始配置时确定不能更改,但状态"active/standby"是可变化的,处于"active"状态的集群是目前客户端访问的集群。提供主备集群双向同步链路的实时延迟展示,同时提供客户端链接数量监控,使得用户可以准确的判断切换进度。
云HBase高可用使用方式
如果您已经使用了云HBase并且希望增加一个备库,只需如下步骤
1 购买一个BDS集群用于管理主备
2 购买一个空的云HBase集群作为备库
3 输入主备两个集群的实例ID创建高可用访问地址
4 开始您的高可用之旅
如果您使用的是ECS自建集群或者EMR HBase,希望增加一个备库,只需如下步骤
1 购买一个BDS集群用于管理主备
2 购买一个空的云HBase集群作为备库
3 配置域名映射和安全组(会提供相关的服务一键解决)
4 输入主备两个集群的地址信息创建高可用访问地址
5 开始您的高可用之旅
原文链接
本文为云栖社区原创内容,未经允许不得转载。