基于函数计算的 Serverless AI 推理
前言概述
本文介绍了使用函数计算部署深度学习 AI 推理的最佳实践, 其中包括使用 FUN 工具一键部署安装第三方依赖、一键部署、本地调试以及压测评估, 全方位展现函数计算的开发敏捷特性、自动弹性伸缩能力、免运维和完善的监控设施。
1.1 DEMO 概述

通过上传一个猫或者狗的照片, 识别出这个照片里面的动物是猫还是狗
- DEMO 示例效果入口: http://sz.mofangdegisn.cn
- DEMO 示例工程地址: https://github.com/awesome-fc/cat-dog-classify
1.2 解决方案
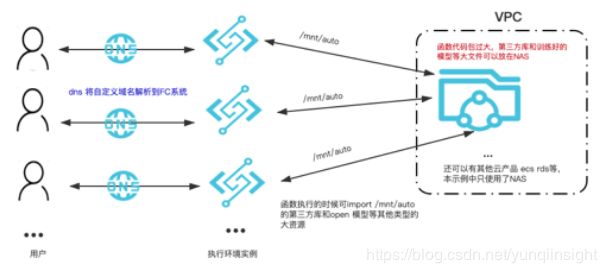
如上图所示, 当多个用户通过对外提供的 url 访问推理服务时候,每秒的请求几百上千都没有关系, 函数计算平台会自动伸缩, 提供足够的执行实例来响应用户的请求, 同时函数计算提供了完善的监控设施来监控您的函数运行情况。
1.3. Serverless 方案与传统自建服务方案对比
1.3.1 卓越的工程效率
| 自建服务 | 函数计算 Serverless | |
|---|---|---|
| 基础设施 | 需要用户采购和管理 | 无 |
| 开发效率 | 除了必要的业务逻辑开发,需要自己建立相同线上运行环境, 包括相关软件的安装、服务配置、安全更新等一系列问题 | 只需要专注业务逻辑的开发, 配合 FUN 工具一键资源编排和部署 |
| 学习上手成本 | 可能使用 K8S 或弹性伸缩( ESS ),需要了解更多的产品、名词和参数的意义 | 会编写对应的语言的函数代码即可 |
1.3.2 弹性伸缩免运维
| 自建服务 | 函数计算 Serverless | |
|---|---|---|
| 弹性高可用 | 需要自建负载均衡 (SLB),弹性伸缩,扩容缩容速度较 FC 慢 | FC系统固有毫秒级别弹性伸缩,快速实现底层扩容以应对峰值压力,免运维 |
| 监控报警查询 | ECS 级别的 metrics | 提供更细粒度的函数执行情况,每次访问函数执行的 latency 和日志等, 更加完善的报警监控机制 |
1.3.3 更低的成本
- 函数计算 (FC) 固有自动伸缩和负载均衡功能,用户不需要购买负载均衡 (SLB) 和弹性伸缩。
- 具有明显波峰波谷的用户访问场景(比如只有部分时间段有请求,其他时间甚至没有请求),选择按需付费,只需为实际使用的计算资源付费。
对于明显波峰波谷或者稀疏调用具有低成本优势, 同时还保持了弹性能力,以后业务规模做大以后并没有技术切换成本,同时财务成本增长配合预付费也能保持平滑。
- 部分请求持续平稳的场景下,可以配合预付费解决按需付费较高单价问题。函数计算成本优化最佳实践文档。
假设有一个在线计算服务,由于是CPU 密集型计算, 因此在这里我们将平均 CPU 利用率作为核心参考指标对成本,以一个月为周期,10台 C5 ECS 的总计算力为例,总的计算量约为 30% 场景下, 各解决方案 CPU 资源利用率使用情况示意图大致如下:

由上图预估出如下计费模型:
- 函数计算预付费 3CU 一个月: 246.27 元, 计算能力等价于 ECS 计算型 C5
- ECS 计算型 C5 (2vCPU,4GB)+云盘: 包月219 元,按量: 446.4 元
- 包月10 Mbps 的 SLB: 526.52 元(这里做了一定的流量假设), 弹性伸缩免费
- 饱和使用下,函数计算按量付费的一台机器成本约为按量付费 C5 ECS 的2 倍
| 平均CPU利用率 | 计算费用 | SLB 总计 | ||
|---|---|---|---|---|
| 函数计算组合付费 | >=80% | 738+X(246.27*3+X) | 无 | <= 738+X |
| 按峰值预留ECS | <=30% | 2190(10*219) | 526.52 | >=2716.52 |
| 弹性伸缩延迟敏感 | <=50% | 1314(102193/5) | 526.52 | >= 1840.52 |
| 弹性伸缩成本敏感 | <=70% | 938.57 (102193/7) | 526.52 | >= 1465.09 |
注:
- 这里假设函数逻辑没有公网公网下行流量费用, 即使有也是一致的, 这里成本比较暂不参与
- 延时敏感,当 CPU 利用率小于等于 50% 就需要开始进行扩容,不然更来不及应对峰值
- 成本敏感,当 CPU 利用率大约 80% 即开始进行扩容, 能容受一定几率的超时或者5XX
上表中, 其中函数计算组合付费中的 X 为按需付费的成本价,假设按需付费的计算量占整个计算量的 10%,假设 CPU 利用率为100%, 对应上表,那么需要 3 台 ECS 的计算能力即可。因此 FC 按量付费的成本 X = 3 219 10% * 2 = 131.4 ( FC 按量付费是按量 ECS 的2倍),这个时候函数计算组合付费总计 869.4 元。 在这个模型预估里面, 只要FC 按量付费占整个计算量小于 20%, 即使不考虑 SLB, 单纯考虑计算成本, 都是有一定优势的。
1.3.4. 小结
基于函数计算进行 AI 推理等 CPU 密集型的主要优势:
-
上手简单, 只专注业务逻辑开发, 极大提高工程开发效率。
- 自建方案有太多学习和配置成本,如针对不同场景,ESS 需要做各种不同的参数配置
- 系统环境的维护升级等
- 免运维,函数执行级别粒度的监控和告警。
- 毫秒级弹性扩容,保证弹性高可用,同时能覆盖延迟敏感和成本敏感类型。
-
在 CPU 密集型的计算场景下, 通过设置合理的组合计费模式, 在如下场景中具有成本优势:
- 请求访问具有明显波峰波谷, 其他时间甚至没有请求
- 有一定稳定的负载请求, 但是有部分时间段请求量突变剧烈
打包代码ZIP包和部署函数
FUN 操作简明视频教程
2.1 安装第三方包到本地并上传到NAS
2.1.1 安装最新的Fun
- 安装版本为8.x 最新版或者10.x 、12.x nodejs
- 安装 funcraf
2.1.2 Clone 工程 & Fun 一键安装第三方库到本地
git clone https://github.com/awesome-fc/cat-dog-classify.git- 复制 .env_example 文件为 .env, 并且修改 .env 中的信息为自己的信息
-
执行
fun install -v, fun 会根据 Funfile 中定义的逻辑安装相关的依赖包
root@66fb3ad27a4c: ls .fun/nas/auto-default/classify model python root@66fb3ad27a4c: du -sm .fun 697 .fun
根据 Funfile 的定义:
- 将第三方库下载到
.fun/nas/auto-default/classify/python目录下 - 本地 model 目录移到
.fun/nas/auto-default/model目录下
安装完成后,从这里我们看出, 函数计算引用的代码包解压之后已经达到了 670 M, 远超过 50M 代码包限制, 解决方案是 NAS 详情可以参考: 挂载NAS访问,幸运的是 FUN 工具一键解决了 nas 的配置和文件上传问题。
2.1.3. 将下载的依赖的第三方代码包上传到 NAS
fun nas init
fun nas info
fun nas sync
fun nas ls nas://classify:/mnt/auto/
依次执行这些命令,就将本地中的 .fun/nas/auto-default 中的第三方代码包和模型文件传到 NAS 中, 依次看下这几个命令的做了什么事情:
fun nas init: 初始化 NAS, 基于您的 .env 中的信息获取(已有满足条件的nas)或创建一个同region可用的nasfun nas info: 可以查看本地 NAS 的目录位置, 对于此工程是 $(pwd)/.fun/nas/auto-default/classifyfun nas sync: 将本地 NAS 中的内容(.fun/nas/auto-default/classify)上传到 NAS 中的 classify 目录fun nas ls nas://classify:/mnt/auto/: 查看我们是否已经正确将文件上传到了 NAS
登录 NAS 控制台 https://nas.console.aliyun.com 和 VPC 控制台 https://vpc.console.aliyun.com
可以观察到在指定的 region 上有 NAS 和 相应的 vpc 创建成功
2.2 本地调试函数
在 template.yml 中, 指定了这个函数是 http 类型的函数, 所以根据 fun 的提示:
Tips for next step
======================
* Invoke Event Function: fun local invoke
* Invoke Http Function: fun local start
* Build Http Function: fun build
* Deploy Resources: fun deploy执行 fun local start, 本地就会启动一个 http server 来模拟函数的执行, 然后我们 client 端可以使用 postman, curl 或者浏览器, 比如对于本例:
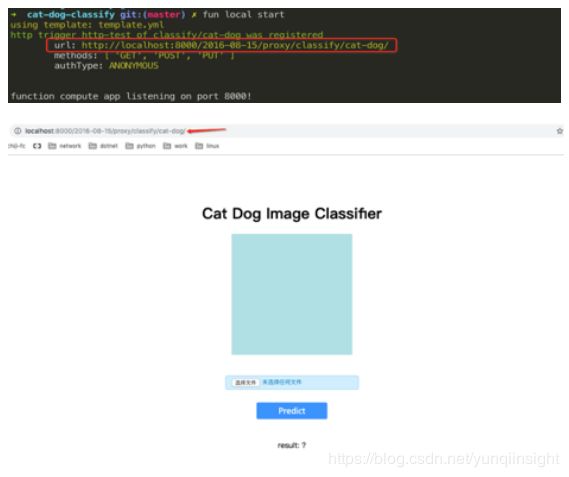
2.3 部署函数到FC平台
本地调试OK 后,我们接下来将函数部署到云平台:
修改 template.yml LogConfig 中的 Project, 任意取一个不会重复的名字即可, 然后执行
fun deploy
注意: template.yml 注释的部分为自定义域名的配置, 如果想在 fun deploy 中完成这个部署工作:
- 先去域名解析, 比如在示例中, 将域名 sz.mofangdegisn.cn 解析到 123456.cn-hangzhou.fc.aliyuncs.com, 对应的域名、accountId 和 region 修改成自己的
- 去掉 template.yml 中的注释, 修改成自己的域名
- 执行
fun deploy
这个时候如果没有自定义域名, 直接通过浏览器访问访问http trigger 的url, 比如 https://123456.cn-shenzhen.fc.aliyuncs.com/2016-08-15/proxy/classify/cat-dog/ 会被强制下载.
原因:https://help.aliyun.com/knowledge_detail/56103.html#HTTP-Trigger-compulsory-header

登录控制台https://fc.console.aliyun.com,可以看到service 和 函数已经创建成功, 并且 service 也已经正确配置。

在这里,我们发现第一次打开页面访问函数的时候,执行环境实例冷启动时间非常长, 如果是一个在线AI推理服务,对响应时间非常敏感,冷启动引起的毛刺对于这种类型的服务是不可接受的,接下来,本文讲解如何利用函数计算的预留模式来消除冷启动带来的负面影响。
使用预留模式消除冷启动毛刺
函数计算具有动态伸缩的特性, 根据并发请求量,自动弹性扩容出执行环境来执行环境,在这个典型的深度学习示例中,import keras 消耗的时间很长 , 在我们设置的 1 G 规格的函数中, 并发访问的时候耗时10s左右, 有时甚至20s+
start = time.time()
from keras.models import model_from_json
print("import keras time = ", time.time()-start)3.1 函数计算设置预留
预留操作简明视频教程
- 在 FC 控制台,发布版本,并且基于该版本创建别名 prod,并且基于别名 prod 设置预留, 操作过程请参考:https://help.aliyun.com/document_detail/138103.html
- 将该函数的 http trigger 和 自定义域名的设置执行 prod 版本

一次压测结果

从上面图中我们可以看出,当函数执行的请求到来时,优先被调度到预留的实例中被执行, 这个时候是没有冷启动的,所以请求是没有毛刺的, 后面随着测试的压力不断增大(峰值TPS 达到 1184), 预留的实例不能满足调用函数的请求, 这个时候函数计算就自动进行按需扩容实例供函数执行,此时的调用就有冷启动的过程, 从上面我们可以看出,函数的最大 latency 时间甚至达到了 32s,如果这个web AP是延时敏感的,这个latency是可接受的。
总结
- 函数计算具有快速自动伸缩扩容能力
- 预留模式很好地解决了冷启动中的毛刺问题
- 开发简单易上手,只需要关注具体的代码逻辑, Fun 工具助您一键式部署运用
- 函数计算具有很好监控设施, 您可以可视化观察您函数运行情况, 执行时间、内存等信息
原文链接
本文为云栖社区原创内容,未经允许不得转载。