windows下安装Logstash-7.3.2
windows下安装Logstash-7.3.2
Logstash 是开源的服务器端数据处理管道, 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构。
Logstash原理
Logstah处理事件有三个阶段:input、filter、output。
1. input
产生事件,常见的input有file、beats。
2. filter
结合条件语句对符合标准的事件进行处理。
- grok:解析和结构化任何文本。Grok目前是logstash最好的方式对非结构化日志数据解析
成结构化和可查询化。 - mutate:在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
- drop:完全丢弃事件,如debug事件
- clone:复制事件,可能添加或者删除字段。
- geoip:添加有关IP地理位置信息。
3. output
output是logstash管道的最后一个阶段,一个事件可以经过多个output。但是一旦所有输出
处理完,该事件已经执行完。常用的output有elasticsearch、file。
Logstash-7.3.2安装过程
1. 下载链接 红色方框中可下载Logstash-7.3.2的windows版本logstash-7.3.2.zip
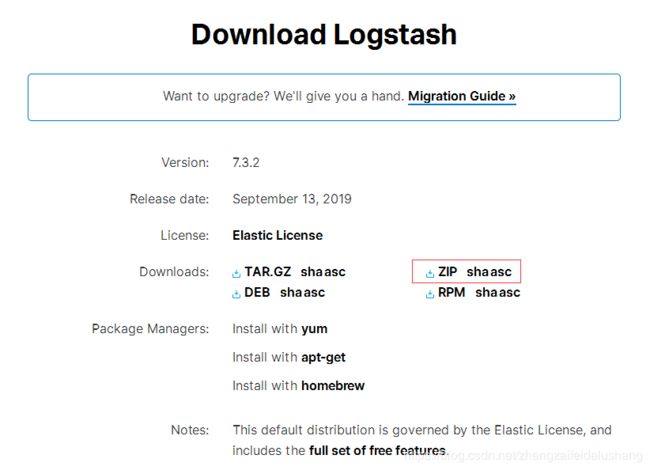
2. 解压缩
3. 重点:一定要在logstash的/bin目录下,新建一个配置文件。配置文件可以参考logstash/config目录下的logstash-sample.conf。
配置文件
input {
beats {
port => 5044
}
}
filter {
if "java-logs" in [tags]{
grok{
#筛选过滤
match => {
"message" => "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]\[(?[A-Z]{4,5})\]\[(?[A-Za-z0-9/-]{4,40})\]\[(?[A-Za-z0-9/.]{4,40})\]\[(?.*)"
}
remove_field => ["message"]
}
#不匹配正则则删除,匹配正则则用=~
if [level] !~ "(ERROR|WARN|INFO)" {
# 删除日志
drop {}
}
}
}
output {
elasticsearch {
hosts => "localhost:9200"
}
}
启动logstash
logstash -f logstash.conf
启动成功如图所示。默认端口为9600。在浏览器中输入localhost:9600即可查看效果。

logstash配置文件详解
1. Input
input {
path => "D:\input\a\*.log"
exclude => "*.gz"
start_position => "beginning"
ignore_older => 0
sincedb_path => "D:\input\record"
add_field => {"test"="test"}
type => "apache-log"
}
path:数组类型,读取文件的路径。
exclude:数组类型,排除不想监听的文件规则。
sincedb_path:字符串类型,记录sincedb文件路径,logstash会通过sincedb文件来跟踪记录每个文件中的当前位置,停止和重新启动logstash,logstash会从记录位置继续读取文件。
start_position: 字符串类型,可以配置为beginning/end,是否从头读取文件
stat_interval: 数值类型,定时检查文件是否有更新,默认是1秒
discover_interval: 数值类型,定时检查是否有新文件待读取,默认是15秒
ignore_older: 数值类型,扫描文件列表时,如果该文件上次更改时间超过设定的时长,则不做处理,但依然会监控是否有新内容,默认关闭
close_older: 数值类型,如果监听的文件在超过该设定时间内没有新内容,会被关闭文件句柄,释放资源,但依然会监控是否有新内容,默认3600秒,即1小时
add_field: 增加一个字段
type: 表明导入的日志类型
2. Codec
Codec作用于Input和Output,负责将数据在原始与Logstash Event之间转换,常见的codec有:
- plain: 读取原始内容
- dots: 将内容简化为点进行输出
- rubydebug: 将Logstash Events按照ruby格式输出,方便调试
- line: 处理带有换行符的内容
- json: 处理json格式的内容
- multiline: 处理多行数据的内容,当一个事件的message由多行组成时,需要使用multiline,常见的情况是处理日志信息。
input {
file {
path => "D:\input\a\*.log"
start_position => "beginning"
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}
pattern: 设置行匹配的正则表达式,可以使用grok
what: 可设置为previous或next。表示当与pattern匹配成功的时候,匹配行是归属上一个事件还是下一个事件
negate: 布尔值,表示是否对pattern的结果取反
3. Filter
Filter可以对Logstash事件进行丰富的处理,比如解析数据、删除字段、类型转换等等
grok插件
grok插件用于解析日志内容。
grok语法:%{SYNTAX:SEMANTIC}
SYNTAX代表匹配值类型,SEMANTIC代表赋值字段名称。
%{NUMBER:duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以通过在最后指定为int或者float来强转类型:
%{NUMBER:duration:int}
(1) Grok过滤插件的基本语法格式
filter{
grok{
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}
#message: 所有文本数据都是在Logstash的message字段中的,要在过滤器里操作的数据就是message
#match : 从message字段中把时间字段给抠出来,并且赋值给另一个字段logdate
#grok十分消耗资源,有许多预装的正则表达式
#TIMESTAMP_ISO8601,ISO8601时间戳格式,2016-07-03T00:34:06+08:00
filter{
grok{
match => {'message' => "%{IPORHOST:clientip}\s+%{WORD:method}\s+%{URIPATHPARAM:request}\s+%{NUMBER:bytes}\s+%{NUMBER:duration}"}
}
}
#IPORHOST:IP或者主机名称
#WORD: 字符串,包括数字和大小写字母比如:String、3529345、I LoveYou等
#URIPATHPARAM:URI路径+GET参数,比如://www.stozen.net/abc/api.php?a=1&b=2&c=3
#number:必须是有效的数值,浮点数或者整数
(2) 常用的配置选项
match:
match作用:用来对字段的模式进行匹配
filter{
grok{
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}
当需要匹配多条不同的日志时可以写为:
filter{
grok{
match => [
"message","%{URIHOST:http_host} %{IP:server_addr} %{IP:remote_addr} \[%{HTTPDATE:timestamp}\]",
"message","(?"<datetime>\d\d\d\d/\d\d/\d\d \d\d:\d\d:\d\d) \[(?<errtype>\w+)\] (?<other1>\s+:) \*\d+ (?<errmsg>[^,]+), (?<errinfo>.*)$",
"message","(?"<datetime>\d\d\d\d/\d\d/\d\d \d\d:\d\d:\d\d) \[(?<errtype>\w+)\] (?<other1>\s+:) \*\d+ (?<errmsg>[^,]+)"
]
}
}
patterns_dir:
作用:用来指定规则的匹配路径,如果使用logstash自定义的规则时,不需要写此参数。patterns_dir可以同时制定多个存放过滤规则的目录。
patterns_dir => ["D:\input\patterns","D:\input\extra_patterns"]
remove_field:
作用:如果匹配到某个日志字段,则将匹配的这个日志字段从这条日志中删除。也可以同时删除多个匹配到的切割后的日志段。
grok {
remove_field => ["err_%{field}","error_field"]
}
自定义grok pattern
通过pattern_definitions参数,以键值对的方式定义pattern名称和内容,也可以通过pattern_dir参数,以文件的形式读取pattern。
input {
stdin{
}
}
filter {
grok {
match => {
"message" => "%{SERVICE:service}"
}
pattern_definitions => {
"SERVICE" => "[a-z0-9]{10,11}"
}
}
}
output {
stdout { codec => rubydebug}
}
输出如下所示
[2019-09-23T14:19:33,461][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
yf123456789
D:/software/ELK/logstash-7.3.2/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"@version" => "1",
"message" => "yf123456789\r",
"@timestamp" => 2019-09-23T06:21:34.754Z,
"host" => "LW7CNENJEDRD183",
"service" => "yf123456789"
}
yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
{
"@version" => "1",
"message" => "yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy\r",
"@timestamp" => 2019-09-23T06:21:51.967Z,
"host" => "LW7CNENJEDRD183",
"service" => "yyyyyyyyyyy"
}
kv插件
grok切割匹配日志是根据正则表达式来匹配的,kv插件也可对日志进行切割,kv是以指定的特殊字符串对日志以key-value形式的切割,“key"和"value"都存在于日志中。kv插件中默认字符段的分隔符是” “, “key” 和"value"的分隔符是”="。而grok插件中"key"是自定义的,"value"是通过正则匹配出来的。所以对不规律的日志只能使用grok规律,对于有规律的日志使用kv插件更方便。
(1) kv插件的基本语法格式
kv {
source => "ERROR"
field_split => "\,"
value_split => ":"
}
(2) kv插件常用的配置选项
allow_duplicate_values:
作用:用于删除重复键值对的bool选项。当设置为false时,只保留一个唯一的键值对。
kv {
allow_duplicate_values => false
}
field_split:
作用:指定多对key-value之间的分割符,默认分隔符是" "。
kv {
field_split =>"&?"
}
include_brackets:
作用:指定是否将方括号,尖括号和括号视为值"包装器",应该从值中删除,值为布尔值,true或false
kv {
include_brackets => true
}
source:
作用:选择过滤字符串的来源
kv {
source =>"message"
}
value_split:
作用:指定做分割的日志中"key-value"之间的分隔符,默认的值为"="
kv {
value_split => ": "
}
mutate插件
mutate主要用来修改、替换、删除及重命名字段。
mutate {
convert => {"age" => "integer"}
gsub => [
"birthday", "-", "/",
"image", "\/", "_"
]
split => {"hobities" => ","}
rename => {"hobities" => "hobityList"}
replace => {"icon" => "%{image}"}
remove_field => ["message"]
}
常用的配置选项:
gsub:
作用:使用正则表达式或者字符串替换日志中的某些字符串。
#将message中的"/"替换为"_"
gsub => [
"message", "[/]", "_"
]
remove_field:
作用: 将匹配到的"key-value"从日志中删除。
rename:
作用:对某些字段重新命名
#将HOSTORIP重命名为client_ip
rename => {"HOSTORIP" => "client_ip"}
replace、update:
作用: 字段内容更新或替换。区别在于update只在字段存在时生效,replace在字段不存在时会执行新增字段的操作
replace => {"salary"=>"%{salary_1}.%{salary_2}"}
convert:
作用:类型转换
split:
作用:字符串切割
join
作用:数组合并为字符串
merge:
作用: 数组合并为数组
dissect插件
基于分隔符原理解析数据,解决grok解析时消耗过多cpu资源的问题。dissect语法简单,只能处理格式相似,且有分割符的字符串。切割的日志中,基本上所有的字段格式是字符串类型的,如果需要在kibana中对收集的日志的部分字段求和或做其他的计算操作,需要将字符串转换为数字格式,这时就用到了dissect插件。
常用的配置选项:
convert_datatype :
作用:对key所对应的value的类型做转化。
例子1:
输入:
Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool
把这个日志的日期和时间解析到同一个字段中,通过dissect插件实现。
input {
stdin{
}
}
filter {
dissect {
mapping => {
"message" => "%{ts} %{+ts} %{+ts} %{src} %{prog}[%{pid}]: %{msg}"
}
}
}
output {
stdout { codec => rubydebug}
}
输出如下所示:
{
"pid" => "1",
"host" => "LW7CNENJEDRD183",
"ts" => "Apr 26 12:20:02",
"msg" => "Starting system activity accounting tool\r",
"prog" => "systemd",
"@timestamp" => 2019-09-23T06:37:42.507Z,
"message" => "Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool\r",
"@version" => "1",
"src" => "localhost"
}
例子2:
输入:name=huoyingrenzhe&age=23
input {
stdin{
}
}
filter {
dissect {
mapping => {
"message" => "%{?key1}=%{&key1}&%{?key2}=%{&key2}"
convert_datatype => {
age => "int"
}
}
}
}
output {
stdout { codec => rubydebug}
}
输出:
{
"name" => "huoyingrenzhe",
"@timestamp" => 2019-09-23T06:56:32.885Z,
"host" => "LW7CNENJEDRD183",
"message" => "name=huoyingrenzhe&age=23\r",
"@version" => "1",
"age" => "23\r"
}
%{?}代表忽略匹配值,但是赋予字段名,用于后续匹配用。
%{&}代表将匹配字段值赋到指定字段中。
%convert_datatype => 可以将指定字符串转为int或者float类型
geoip插件的用法
根据ip地址提供对应的地域信息,比如经纬度、城市名等,方便进行地理数据分析。
filter {
geoip {
source => "clientIp"
target => "geoip"
database => "D:\input\GeoLite2-City.mmdb "
}
}
常用的配置选项:
soruce :
作用: 用来指定对分割的日志中的哪个"key"对应的ip地址通过geoip插件处理。
tatget :
作用:指定logstash应该存储geoip数据的字段
fields :
作用: 设置需要geoip中包含的字段,值类型为数组
database :
作用:设置geoip2数据库文件所在的地址。GeoIP2 服务能识别互联网用户的地点位置与其他特征。
json插件的用法
将字段内容为json格式的数据解析出来
filter {
json {
source => "message"
target => "msg_json"
}
}
3. Output
输出到控制台
output {
stdout {
codec => rubydebug
}
}
输出到文件
output {
file {
path => "文件路径"
codec => line {format => %{message}}
}
}
输出到elasticsearch
output {
elasticsearch {
hosts => "localhost:9200"
}
}