DEEP COMPRESSION(深度学习网络参数压缩)
DEEP COMPRESSION:
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
github 源码地址
Introduce
本篇论文是ICLR2016年的best paper,主要讲述关于深度学习网络参数的压缩工作。论文主要从下三点出发:
- pruning
- train quantization
- huffman coding
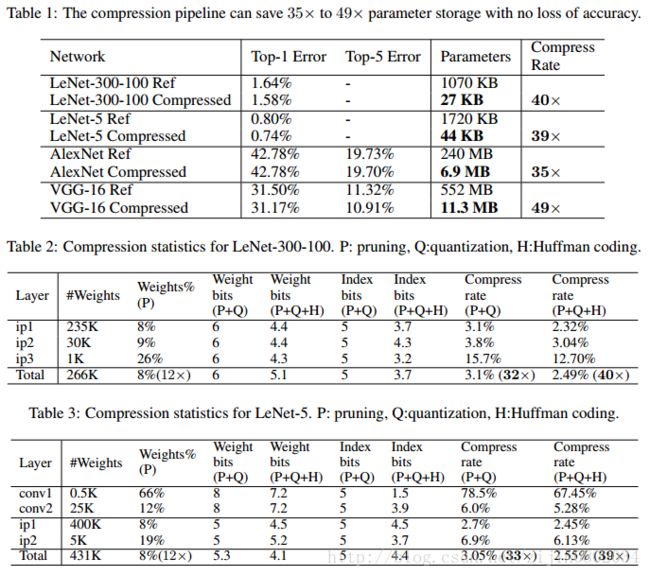
本文首先对网络进行剪枝,只保留重要的连接;第二步通过参数共享量化权重矩阵;第三步对量化值进行huffman编码,进一步压缩。整个网络在不影响性能的情况下,能够将参数量降低到原来的1/49~1/35。
在ImageNet数据集上,压缩后的网络的实验结果如下所示:
1. AlexNet在不影响精度的前提下,参数从240M减少到6.9M,35 ×
2. VGG-16在不影响精度的前提下,参数量从552M减少到11.3M,49 ×
3. 模型能够在DRAM运行。
4. 运行速度提高3-4倍。
5.消耗能量减少到原来的1/7~1/3。

从图1可以看出网络的基本流程,首先移除冗余的连接,只保留权值比较大的连接,得到剪枝后的网络;第二步,权重进行量化,然后多个连接共享一个参数,只保存码本和索引;第三步,使用huffman编码,压缩量化的值。
Network pruning
在深度学习训练的过程中,会学到连接的参数。剪枝的方法也很简单,连接的权值小于一定阈值的直接移除,最终就得到了稀疏的网络连接。剪枝这一步骤能够将VGG-16(AlexNet)参数降低到原来的1/13(1/9)。
稀疏矩阵用compressed sparse row(CSR)和compressed sparse column(CSC)的格式进行压缩,总共需要2a+n+1个存储单元,a是非零元素个数,n是行数或者列数。
网络剪枝的过程如figure 2所示:

一个4*4的矩阵可以用一维16数组表示,剪枝时候,只保留 权值大于指定阈值的数,用相对距离来表示,例如idx=4和idx=1之间的位置差为3,如果位置差大于设定的span,那么就在span位置插入0。例如15和4之间距离为11大于span(8),所以在4+8的位置插入0,idx=15相对idx=12为3。这里span阈值在卷积层设置为8,全连接层为5。
Train Quantization And Weight Shared
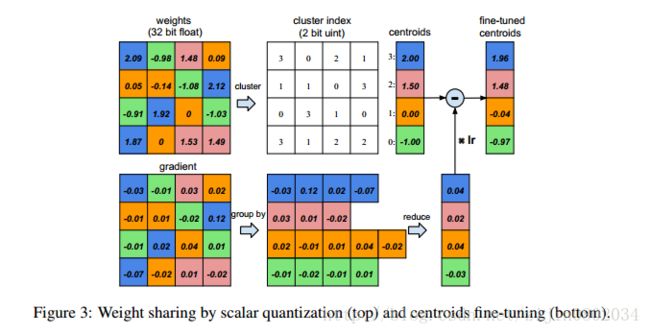
图3假定某层有4个输入单元4个输出单元,权重矩阵为4*4,梯度同样为4*4。假设权重被量化为4类,用四种颜色标识。用每类量化的值代表每类的权值,得到量化后的权值矩阵。用4个权值和16个索引就可以计算得到4*4权重矩阵连接的权值。梯度矩阵同样量化为4类,对每类的梯度进行求和得到每类的偏置,和量化中心一起更新得到新的权值。
压缩率计算方法如下公式所示:
公式(1)n代表连接数,b代表每一个连接需要b bits表示,k表示量化k个类,k类只需要用 log2(k) 个bit表示,n个连接需要 nlog2(k) 索引,还需要用 kb 表示量化中心的数值。
拿图3为例,有16个连接,每一个连接需要用32位的数值进行比较,量化为4类,每类只需要两个bit表示,每类的量化中心值32位。
在量化为k个类时,作者采用了K-means聚类方法,把原始的n个权重 W={w1,w2,......,wn} 使用聚类算法变为k个聚类中心 C={c1,c2,......,ck} 。聚类算法最小化类内误差,目标函数如下所示:
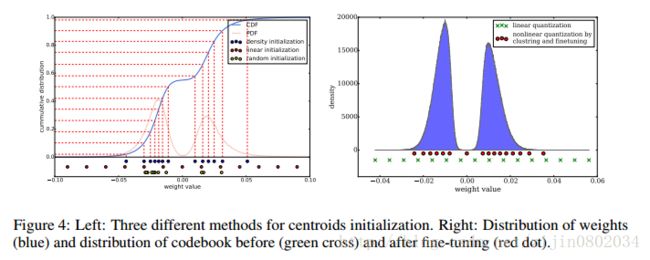
聚类中心的初始化也会影响网络的精度,作者提出了三种初始化方法,分别为:
- Forgy: 从原始的数据集中随机选取k个值作为聚类中心,从figure4可以看出,原始的数据符合双峰曲线,所以初始化的值集中在两个峰顶附近。
- Density-based:在Y轴平分CDF曲线,然后找到对应的X轴位置,作为初始化聚类中心。这种方法初始化距离中心也是在双峰附近,但是比Forgy相对稀疏。
- Linear:找到权值的最大值和最小值,在[min,max]区间内平均划分k份,作为原始的聚类中心。
但是在深度学习中,大的权值说明对该因素的影响大,但是实际上,大的权值在参数中很少,如果采用1,2方法进行初始化,可能会把大的权值量化为小的值,影响实际效果。所以线性的初始化效果最好。
量化之后,目标函数的求导就变为了量化后聚类中心的值的求导:
1(.) 是指示函数。
Huffman Coding
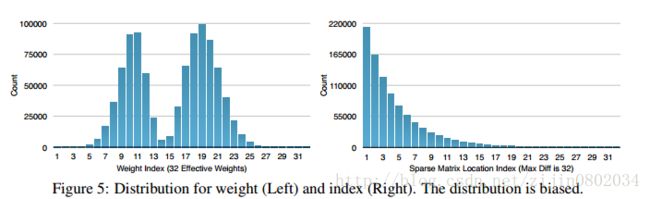
聚类中心,需要用 log2(k) 的bit作为索引,这里可以使用变长的huffman编码进一步压缩。figure 5显示了压缩前和压缩后的长度分布。
Experiment
作者把上述方法分别在Lenet,AlexNet和VGG上,在MNIST和ImageNet的数据集测试实验结果:
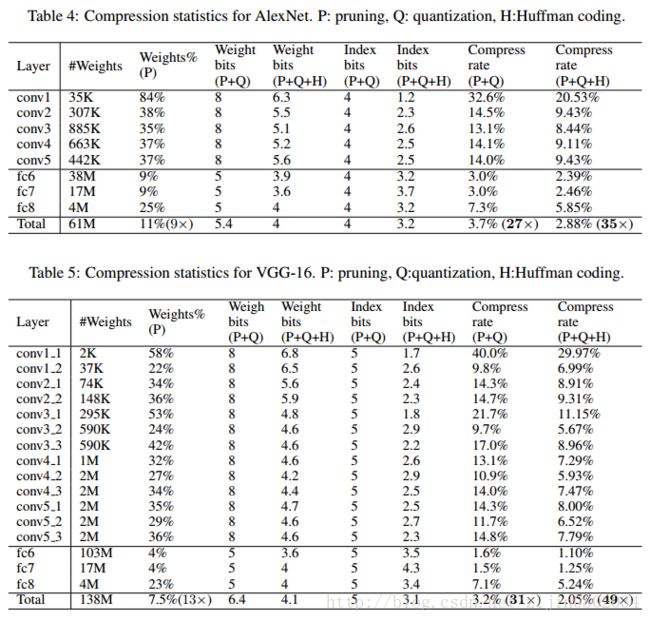
论文还有一些关于discuss部分以及实验结果就不再仔细阐述了,相关内容请阅读论文。
Conclusion
深度学习最近几年很火热,但是终究由于需要资源过多的原因,并没有在移动设备上大量应用,这也是深度学习的缺陷之一,这也是很多科研人员努力的解决的问题。本文就是基于网络参数压缩作的工作,还有相关研究从硬件出发设计符合深度学习的芯片,我们研究所的寒武纪公司就是代表。希望未来不远,移动芯片都能良好的使用深度学习。
最后推荐一下ICLR这个会议,最近几年的举办的会议,FeiFei Li,Lecun Yan, Bengio等大牛都在上面发表文章。
Reference
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING ICLR2016 song han, Huizi Mao,William J.Dally