【AI前沿】机器阅读理解与问答·Dynamic Co-Attention Networks
内容速览
- 协同注意力 Co-Attention
- 动态迭代 Dynamic Iteration
- DCN模型
- Highway和Maxout简介
- 实验与总结
在上期的文章【AI前沿】机器阅读理解与问答·介绍篇中,我们介绍了机器阅读理解与问答这一任务。介绍了该任务现在的Benchmark数据集(由Stanford发布的SQuAD)、基本的评价标准(Exact-match、F1-Score)、Baseline(基于特征的逻辑回归方法)以及相关的比赛。
接下来的几期,我们将挑选一些比赛排行榜中的公开的算法,为大家进行介绍。由于这些算法都涉及到了最新最前沿的NLP技术,可以说是充满干货,我们希望通过对这些算法进行讲解和介绍,能够让各位读者朋友了解到NLP领域最前沿的一些方法,这些方法也可以应用并扩展到NLP的其他领域中,诸如我们的KB-QA等等。
今天为大家带来的文章是由Salesforce Research组发表在ICLR2017的Dynamic Coattention Networks for Question Answer,该方法的ensemble model在SQuAD比赛中目前排名第9。从文章的名字我们可以注意到两个关键词——Dynmaic和Co-Attention,这是两个在NLP和CV领域都非常流行的两种前沿技术思想。我们以该文章为例,为大家介绍这两种技术,并看看这篇文章是如何使用这两种技术来解决机器阅读理解的。

协同注意力
协同注意力Co-Attention是注意力机制的一种变体,以机器阅读理解为例,注意力机制就很像我们人在做阅读理解时所使用的一种技巧——带着问题去阅读,先看问题,再去文本中有目标地阅读以寻找答案。而机器阅读理解则是通过结合问题和文本段落二者的信息,生成一个关于文本段落各部分的注意力权重,对文本信息进行加权,该注意力机制可以帮助我们更好的去捕捉文本段落中和问题相关的信息。
而协同注意力Co-Attention则是一种双向的注意力,不仅我们要给阅读的文本段落生成一个注意力权重,还要给问句也生成一个注意力权重。该技巧在很多的多模态问题中都可以使用,诸如VQA,同时去生成关于图片和问句的Attention。
协同注意力可以分为两种方式:
- Parallel Co-Attention:将数据源A和数据源B的信息结合(Bilinear等方式),再基于结合的信息分别对两种数据源生成其对应的Attention。
- Alternating Co-Attention:先基于数据源A的信息,产生数据源B的Attention,再基于加入Attention之后的数据源B的信息,去生成数据源A的Attention,类似交替使用两次传统的Attention。
(想对Co-Attention作进一步了解的朋友推荐阅读文章Hierarchical Question-Image Co-Attentionfor Visual Question Answering)
我们可以通过Co-Attention技术对问句和阅读文本都生成Attention,以提升模型的性能。
动态迭代
动态迭代Dynamic iteration也是NLP领域一种比较前沿的技术思想,其主要思想在于仿照人类在考量问题时,需要反复思考。对于模型输出的结果,我们不直接将它作为最终的结果,而是将它继续输入到模型中作为参考,迭代出新一轮的输出,经过多次迭代,直到输出不再变化或超过迭代次数阈值。
这一技术在文本生成上有很多的应用,反复的去打磨生成的文本,诸如唐诗生成等等。
对于机器阅读理解,模型最终需要预测阅读文本的哪一个片段(Span)是问句的答案,我们则可以引入动态迭代的思想,先预测一个片段,再将预测输入回模型,反复迭代后,得到最终的预测片段。
DCN模型
通过对协同注意力和动态迭代这两个技术思想的简单介绍后,我们就有了整个Dynamic Coattention Networks (DCN)的框架,如下图
整个模型分为两个部分

- Coattention Encoder:对文档和问句信息进行引入Coattention机制的encode
- Dynamic Pointer Decoder:根据Coattention Encoder,对输出的预测片段(即起始位置指针和终点位置指针)进行动态迭代
接下来,我们具体介绍这两个部分的模型细节。
Co-Attention Encoder
首先,我们使用LSTM分别对问句和阅读文本进行建模。对于阅读文本,我们将LSTM每一时刻的隐层提取出来,得到文本信息矩阵,作为阅读文本的特征信息。对于问句,我们也将LSTM每一时刻隐层提取出来(为了将问句的encode space能够变换到阅读文本的encode space,我们对提取出来的矩阵作一个非线性变换),得到问句信息矩阵。
有了二者的信息特征矩阵后,我们结合两个矩阵的信息(即相乘):
其中,m代表文档的长度,n代表问句的长度。我们对信息结合后的矩阵分别按行(Row-wise)和按列(Column-wise)求Softmax,就可以得到对文档和问句的Attention矩阵:
这里矩阵即对于文档中的每一个单词(有m个),都对问句中的每一个单词有一个Normlized的Attention,矩阵同理。
接下来,我们借鉴Alternating Co-Attention的思想,先将Attention应用到问句中:
我们同理也可将Attention应用到文档中,即。并且根据Alternating Co-Attention的思想,我们也可以将问句的信息矩阵Q替换为加入了Attention之后的问句信息去对文档进行Attention,即,由于这两个步骤都要与矩阵相乘,我们可以并行计算:
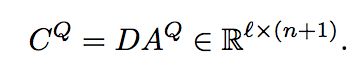
我们将看作是引入Co-Attention机制后的文档信息和文本信息的结合,由于我们最后要基于文档去预测答案片段,所以我们将文档信息D和通过双向LSTM在时序上进行融合:
我们将双向LSTM每一时刻的隐层都提取出来,作为整个Co-Attention Encoder部分的最终输出:
整个Co-Attention Encoder部分的流程图如下所示:
整个Encoder部分可以概括为通过Co-Attention结合文档和问句的特征信息,用双向LSTM对结合后的特征信息和文档信息进行融合。
Dynamic Pointer Decoder
有了Encoder部分输出的矩阵U,我们要利用该矩阵来预测文档中的片段作为最终答案,即预测该片段在文档的起始位置和终止位置。我们可以通过动态迭代的方式,去反复迭代预测起始位置和终止位置,当预测结果不再变化或迭代次数超过阈值,则停止迭代。
整个迭代过程其实就是根据上一次的预测结果和Encoder信息以及历史预测信息,输出下一次的预测结果。作者使用了一个Highway Maxout Networks (HMN) 来完成。HMN模型对文档中的每一个字,都分别从【将它作为起始位置】或【终止位置】两个方面进行打分,以对起始位置打分为例:
其中下标分别表示上一次预测的起始位置和终止位置,表示历史预测信息。对于历史预测信息,我们可以将每一次的预测结果都输入到一个LSTM中去保存该历史预测信息:

有了每个字的打分,我们就可以选取得分最高字的作为起始位置,对于终止位置的预测是一样的。

那么,最后的问题是,HMN是一个什么样的模型?Highway Maxout Networks,其实就是在传统的MLP(多层感知机)上加入了两个改进,引入了Highway Network中的Skip Connection以及使用Maxout作为激活函数。
- Highway Network是由深度学习大牛Schimidhuber(LSTM发明者)小组提出的一种网络结构,其核心思想是将网络前一层的输出,跳着连到更后面的层(Skip Connection),使得模型的深度可以达到上百层,现在非常火热的残差网络ResNet就是受到了该模型的启发。顺便一提,LSTM之父Schimidhuber本人也是一个人工智能的狂热爱好分子,对AI的发展做出了巨大的贡献,本人在温哥华参加会议时有幸和Schimidhuber单独交流并合影,个人感觉他无论从人品和学术上都非常的nice。
- Maxout则是由GAN之父Goodfellow和Yoshua Bengio提出来的一种可学习的激活函数,其思想在于对每一个神经元的输出,都通过k组可学习的参数进行加权变换,得到k个输出,对k个输出取最大值作为最终输出。该方法理论上可以学习到任何类型的激活函数,缺点是引入了更多的参数,增加了训练成本和过拟合的可能。
好了,言归正传,HMN的结构如下图所示:
先将三个信息拼接后通过单层MLP进行融合得到输出。再将待预测的位置和拼接后输入到一个使用Maxout作为激活函数的三层MLP中。该三层MLP引入skip connection,即将第一层的输出同时也传给第三层。整个流程的公式如下:

我们再用下面这张图,将整个Dynamic Pointer Decoder的结构做一个总结:

整个Decoder部分可以概括为用HMN根据历史预测信息、上一次预测情况对每文档中每一个字作为起始位置(或终止位置)进行打分,用LSTM存储历史预测信息,将最后一次迭代得分最高的作为起始位置(或终止位置),得到文档片段作为最终答案。
实验与总结
模型所有隐层大小(LSTM units、Maxout layers、Linear layers)都设置为200,动态迭代的最大迭代次数为4(即迭代四次如果预测结果还不固定依旧停止),作者发现使用预训练并固定的word embedding效果较好。
作者也对模型进行了一个Ablation Study,结果如下:

可以看出HMN、Dynamic Iteration以及Co-Attention都对模型有不同程度的提升。
作者实验发现模型对文档和问句的长度并不敏感(侧面说明了Co-Attention机制能够减少文档长度对模型的影响)。但是当答案长度增长时,模型的性能会有一定的退化。
下图直观的展现了动态迭代预测起始位置和终止位置的情况。图中颜色越深(蓝色系的条表示预测起始位置,橙色系的条表示预测终止位置)表示该位置作为起始位置(或终止位置)的打分越高。
可以看出第一次预测的时候,预测的span是[5,22],经过三次迭代后,成功预测出了正确答案[21,22]。实验结果表明,平均需要的迭代次数为2.7次。

我们最后再对该方法做一个总结,该方法采用了最基本的seq2seq框架来对答案片段的起始和终止位置进行预测。在seq2seq框架的Encoder部分,加入Co-Attention机制去融合问句和文档信息,再将融合信息和文档信息通过双向LSTM再次融合。Decoder部分使用HMN对结果进行预测,通过一个LSTM保存历史预测信息。
该方法的single model F1-Score为75.9,ensemble model F1-Score为80.4。
下期,我们将介绍机器阅读理解任务的另一系列方法,seq-Match-seq,敬请期待。