【Python机器学习及实践】进阶篇:流行库/模型实践
Python机器学习及实践——进阶篇:流行库/模型实践
1.自然语言处理包(NLTK)
使用词袋法(Bag-of-Words)对示例文本进行特征向量化
# 使用词袋法对示例文本进行特征向量化
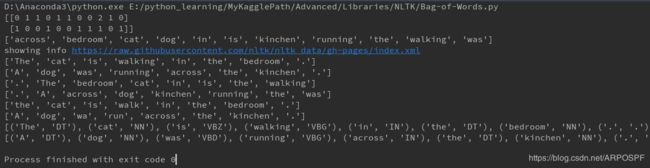
sent1 = 'The cat is walking in the bedroom.'
sent2 = 'A dog was running across the kinchen.'
from sklearn.feature_extraction.text import CountVectorizer
count_vec = CountVectorizer()
sentences = [sent1, sent2]
# 输出特征向量化后的表示
print(count_vec.fit_transform(sentences).toarray())
# 输出向量各个维度的特征含义
print(count_vec.get_feature_names())
使用NLTK对示例文本进行语言学分析
# 使用NLTK对示例文本进行语言学分析
import nltk
nltk.download()
# 对句子进行词汇分割和正规化,有些情况如aren't需要分割为are和n't;或者I'm要分割欸I和'm
tokens_1 = nltk.word_tokenize(sent1)
print(tokens_1)
tokens_2 = nltk.word_tokenize(sent2)
print(tokens_2)
# 整理两句的词表,并且按照ASCII的排序输出
vocab_1 = sorted(set(tokens_1))
print(vocab_1)
vocab_2 = sorted(set(tokens_2))
print(vocab_2)
# 初始化stemmer寻找各个词汇最原始的词根
stemmer = nltk.stem.PorterStemmer()
stem_1 = [stemmer.stem(t) for t in tokens_1]
print(stem_1)
stem_2 = [stemmer.stem(t) for t in tokens_2]
print(stem_2)
# 初始化词性标注器,对每个词汇进行标注
pos_tag_1 = nltk.tag.pos_tag(tokens_1)
print(pos_tag_1)
pos_tag_2 = nltk.tag.pos_tag(tokens_2)
print(pos_tag_2)
这里需要注意的是,需要根据提示下载相关的语料库:nltk.download()
2.词向量(Word2Vec)技术
词袋法(Bag of Words)可以视为对文本向量化的表示技术,通过这项技术可以对文本之间在内容的相似性进行一定程度的度量。但是对于两段文本,词袋法(Bag of Words)技术似乎对计算他们的相似度表现得无能为力。
为了寻找词汇之间的相似度关系,我们也将词汇的表示向量化,通过计算表示词汇的向量之间的相似度,来度量词汇之间的含义是否相似。
句子中的连续词汇片段,也被称为上下文(Context)。词汇之间的联系就是通过无数这样的上下文建立的。从语言模型(Language Model)的角度来讲,每个连续词汇片段的最后一个单词究竟有可能是什么,都受到前面n个词汇的制约。因此,这就形成了一个根据前面n个单词,预测最后一个单词的监督学习系统。
用20类新闻文本进行词向量训练
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : Word2Vec.py
@Author: Xinzhe.Pang
@Date : 2019/7/25 22:15
@Desc :
"""
# 用20类新闻文本进行词向量训练
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
X, y = news.data, news.target
from bs4 import BeautifulSoup
import nltk, re
nltk.download()
# 定义一个函数news_to_sentences讲每条新闻中的句子逐一剥离出来,并返回一个句子的列表
def news_to_sentences(news):
news_text = BeautifulSoup(news).get_text()
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
raw_sentences = tokenizer.tokenize(news_text)
sentences = []
for sent in raw_sentences:
sentences.append(re.sub('[^a-zA-Z]', '', sent.lower().strip()).split())
return sentences
sentences = []
# 将长篇新闻文本中的句子剥离出来,用于训练
for x in X:
sentences += news_to_sentences(x)
# 从gensim.models中导入word2vec
from gensim.models import word2vec
# 配置词向量的维度
num_features = 300
# 保证被考虑的词汇的频度
min_word_count = 20
# 设定并行化训练使用CPU计算核心的数量
num_workers = 2
# 定义训练词向量的上下文窗口大小
context = 5
downsampling = 1e-3
# 训练词向量模型
model = word2vec.Word2Vec(sentences, workers=num_workers, size=num_features, min_count=min_word_count, window=context,
sample=downsampling)
# 这个设定代表当前训练好的词向量为最终版,也可以加快模型的训练速度
model.init_sims(replace=True)
# 利用训练好的模型,寻找训练文本中与morning最相关的10个词汇
model.most_similar('morning')
# 利用训练好的模型,寻找训练文本中与email最相关的10个词汇
model.most_similar('email')
警告:
D:\Anaconda3\python.exe E:/python_learning/MyKagglePath/Advanced/Libraries/NLTK/Word2Vec.py
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
D:\Anaconda3\lib\site-packages\bs4\__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 34 of the file E:/python_learning/MyKagglePath/Advanced/Libraries/NLTK/Word2Vec.py. To get rid of this warning, change code that looks like this:
BeautifulSoup(YOUR_MARKUP})
to this:
BeautifulSoup(YOUR_MARKUP, "lxml")
markup_type=markup_type))
D:\Anaconda3\lib\site-packages\gensim\models\base_any2vec.py:743: UserWarning: C extension not loaded, training will be slow. Install a C compiler and reinstall gensim for fast training.
"C extension not loaded, training will be slow. "
Traceback (most recent call last):
File "E:/python_learning/MyKagglePath/Advanced/Libraries/NLTK/Word2Vec.py", line 57, in
model.most_similar('morning')
File "D:\Anaconda3\lib\site-packages\gensim\utils.py", line 1447, in new_func1
return func(*args, **kwargs)
File "D:\Anaconda3\lib\site-packages\gensim\models\base_any2vec.py", line 1397, in most_similar
return self.wv.most_similar(positive, negative, topn, restrict_vocab, indexer)
File "D:\Anaconda3\lib\site-packages\gensim\models\keyedvectors.py", line 553, in most_similar
mean.append(weight * self.word_vec(word, use_norm=True))
File "D:\Anaconda3\lib\site-packages\gensim\models\keyedvectors.py", line 468, in word_vec
raise KeyError("word '%s' not in vocabulary" % word)
KeyError: "word 'morning' not in vocabulary"
Process finished with exit code 1
解决办法:
1. news_text = BeautifulSoup(news,'lxml').get_text()
2. 在Anaconda中执行下面命令(未检验):
conda install mingw libpython
pip uninstall gensim
conda install gensim
pip install scipy
3.XGBoost模型
提升(Boosting)分类器隶属于集成学习模型,它的基本思想是把成百上千个分类准确率较低的树模型组合起来,称为一个准确率很高的模型。这个模型的特点在于不断迭代,每次迭代就生成一颗新的树。对于如何在每一步生成合理的树,大家提出了很多的方法,比如我们在集成(分类)模型中提到的梯度提升树(Gradient Tree Boosting)。它在生成每一棵树的时候采用梯度下降的思想,以之前生成的所有决策树为基础,向着最小化给定目标函数的方向再进一步。
在合理的参数设置下,我们往往要生成一定数量的树才能达到令人满意的准确率。在数据集较大较复杂的时候,模型可能需要几千次迭代运算。但是,XGBoost工具更好地解决这个问题。XGBoot 的全称是eXtreme Gradient Boosting。正如其名,它是Gradient Boosting Machine的一个C++实现。XGBoost最大的特点在于能够自动利用CPU的多线程进行并行,并在算法上提高了精度。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : XGBoost.py
@Author: Xinzhe.Pang
@Date : 2019/7/25 23:31
@Desc :
"""
# 对比随机决策森林以及XGBoost模型对泰坦尼克号上的乘客是否生还的预测能力
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
# 通过URL地址来下载Titanic数据
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
# 选取pclass、age以及sex作为训练特征。
X = titanic[['pclass', 'age', 'sex']]
y = titanic['survived']
# 对缺失的age信息,采用平均值方法进行补全,即以age列已知数据的平均数填充。
X['age'].fillna(X['age'].mean(), inplace=True)
# 对原数据进行分割,随机采样25%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
# 对原数据进行特征向量化处理
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.transform(X_test.to_dict(orient='record'))
# 采用默认配置的随机森林分类器对测试集进行预测。
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
print('The accuracy of Random Forest Classifier on testing set:', rfc.score(X_test, y_test))
# 采用默认配置的XGBoost模型对相同的测试集进行预测
xgbc = XGBClassifier()
xgbc.fit(X_train, y_train)
print('The accuracy of eXtreme Gradient Boosting Classifier on testing set:', xgbc.score(X_test, y_test))The accuracy of Random Forest Classifier on testing set: 0.77811550152
The accuracy of eXtreme Gradient Boosting Classifier on testing set: 0.787234042553
从结果看,XGBoost分类模型的确可以发挥更好的预测能力。