通过Keras + LSTM训练天气污染程度预测模型
0 前言
在上文中进行ARIMA时序预测后,了解到强大的LSTM在处理时序预测有更为优秀的表现,因此对LSTM进行了学习。
LSTM是一种时间递归神经网络,它出现的原因是为了解决RNN的一个致命的缺陷。原生的RNN会遇到一个很大的问题,叫做The vanishing gradient problem for RNNs,也就是后面时间的节点会出现老年痴呆症,也就是忘事儿,这使得RNN在很长一段时间内都没有受到关注,网络只要一深就没法训练。而LSTM网络具有“记忆性”,其原因在于不同“时间点”之间的网络存在连接,而不是单个时间点处的网络存在前馈或者反馈;并且LSTM擅长于处理多个变量的问题,该特性使其有助于解决时间序列预测问题。
关于LSTM原理,初学者可以通过以下几篇文章简单了解一下,:
https://www.toutiao.com/a6502203093856289294/
https://zybuluo.com/hanbingtao/note/581764
本文内容取自Jason Brownlee的《Multivariate Time Series Forecasting with LSTMs in Keras》一文。在接下来的这篇博客中,你将学会如何利用深度学习库Keras搭建LSTM模型来处理多个变量的时间序列预测问题。
关于如何搭建Keras请看《windows下安装Keras(CPU版)》一文。
阅读完本文后你将会掌握:
如何将原始数据转化为适合处理时序预测问题的数据格式;
如何准备数据并搭建LSTM来处理时序预测问题;
如何利用模型预测。
1 空气污染预测
在这篇博客中,我们将采用空气质量数据集。数据来源自位于北京的美国大使馆在2010年至2014年共5年间每小时采集的天气及空气污染指数。
数据集包括日期、PM2.5浓度、露点、温度、风向、风速、累积小时雪量和累积小时雨量。原始数据中完整的特征如下:
1.No 行数
2.year 年
3.month 月
4.day 日
5.hour 小时
6.pm2.5 PM2.5浓度
7.DEWP 露点
8.TEMP 温度
9.PRES 大气压
10.cbwd 风向
11.lws 风速
12.ls 累积雪量
13.lr 累积雨量
我们可以利用此数据集搭建预测模型,利用前一个或几个小时的天气条件和污染数据预测下一个(当前)时刻的污染程度。
可以在UCI Machine Learning Repository下载数据集。 也可以点击此处下载Beijing PM2.5 Data Set。
2 数据处理
第一步,我们必须清洗数据。以下是原始数据集的前几行。
No,year,month,day,hour,pm2.5,DEWP,TEMP,PRES,cbwd,Iws,Is,Ir
1,2010,1,1,0,NA,-21,-11,1021,NW,1.79,0,0
2,2010,1,1,1,NA,-21,-12,1020,NW,4.92,0,0
3,2010,1,1,2,NA,-21,-11,1019,NW,6.71,0,0
4,2010,1,1,3,NA,-21,-14,1019,NW,9.84,0,0
5,2010,1,1,4,NA,-20,-12,1018,NW,12.97,0,0
第一步是将日期时间信息整合为一个日期时间,以便我们可以将其用作Pandas的索引。我们需要快速显示前24小时的pm2.5的NA值。因此,我们需要删除第一行数据。在数据集中还有几个分散的“NA”值;我们现在可以用0值标记它们。
以下脚本加载原始数据集,并将日期时间信息解析为Pandas Data Frame索引。“No”列被删除,然后为每列指定更清晰的名称。最后,将NA值替换为“0”值,并删除前24小时。
from pandas import read_csv
from datetime import datetime
# load data
def parse(x):
return datetime.strptime(x, '%Y %m %d %H')
dataset = read_csv('raw.csv', parse_dates = [['year', 'month', 'day', 'hour']], index_col=0, date_parser=parse)
dataset.drop('No', axis=1, inplace=True)
# manually specify column names
dataset.columns = ['pollution', 'dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain']
dataset.index.name = 'date'
# mark all NA values with 0
dataset['pollution'].fillna(0, inplace=True)
# drop the first 24 hours
dataset = dataset[24:]
# summarize first 5 rows
print(dataset.head(5))
# save to file
dataset.to_csv('pollution.csv')
运行该示例打印转换的数据集的前5行,并将数据集保存到“pollution.csv”。
pollution dew temp press wnd_dir wnd_spd snow rain
date
2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 SE 1.79 0 0
2010-01-02 01:00:00 148.0 -15 -4.0 1020.0 SE 2.68 0 0
2010-01-02 02:00:00 159.0 -11 -5.0 1021.0 SE 3.57 0 0
2010-01-02 03:00:00 181.0 -7 -5.0 1022.0 SE 5.36 1 0
2010-01-02 04:00:00 138.0 -7 -5.0 1022.0 SE 6.25 2 0
现在的数据格式已经更加适合处理,可以简单的对每列进行绘图。下面的代码加载了“pollution.csv”文件,并对除了类别型特性“风速”的每一列数据分别绘图。
from pandas import read_csv
from matplotlib import pyplot
# load dataset
dataset = read_csv('pollution.csv', header=0, index_col=0)
values = dataset.values
# specify columns to plot
groups = [0, 1, 2, 3, 5, 6, 7]
i = 1
# plot each column
pyplot.figure()
for group in groups:
pyplot.subplot(len(groups), 1, i)
pyplot.plot(values[:, group])
pyplot.title(dataset.columns[group], y=0.5, loc='right')
i += 1
pyplot.show()
运行上述代码,并对7个变量在5年的范围内绘图。
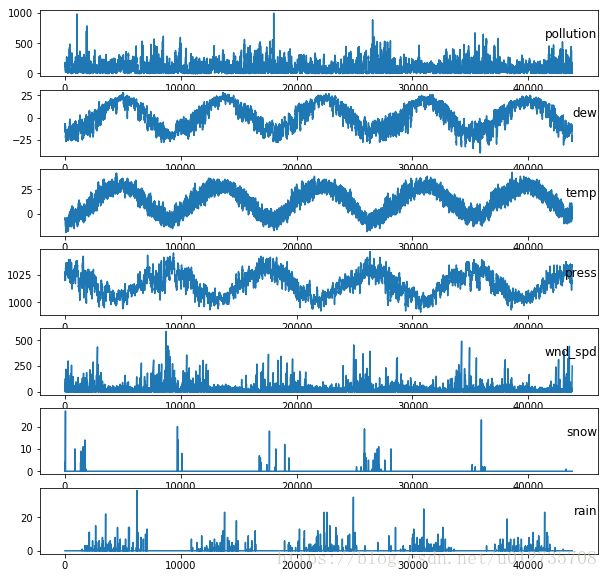
3 多变量LSTM预测模型
3.1 LSTM数据准备
第一步是为LSTM准备污染数据集。这涉及将数据集视为监督学习问题并对输入变量进行归一化处理。考虑到上一个时间段的污染测量和天气条件,我们将把监督学习问题作为预测当前时刻(t)的污染情况。根据过去24小时的天气情况和污染,预测下一个小时的污染,并给予下一个小时的“预期”天气条件。
我们可以使用在之前博客中所写的series_to_supervised()函数来转换数据集:如何将时间序列转换为Python中的监督学习问题
下面代码中首先加载“pollution.csv”文件,并利用sklearn的预处理模块对类别特征“风向”进行编码,当然也可以对该特征进行one-hot编码。 接着对所有的特征进行归一化处理,然后将数据集转化为有监督学习问题,同时将需要预测的当前时刻(t)的天气条件特征移除,完整代码如下:
# convert series to supervised learning
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
# load dataset
dataset = read_csv('pollution.csv', header=0, index_col=0)
values = dataset.values
# integer encode direction
encoder = LabelEncoder()
values[:,4] = encoder.fit_transform(values[:,4])
# ensure all data is float
values = values.astype('float32')
# normalize features
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
# frame as supervised learning
reframed = series_to_supervised(scaled, 1, 1)
# drop columns we don't want to predict
reframed.drop(reframed.columns[[9,10,11,12,13,14,15]], axis=1, inplace=True)
print(reframed.head())
运行示例打印转换后的数据集的前5行。我们可以看到8个输入变量(输入序列)和1个输出变量(当前小时的污染水平)。
var1(t-1) var2(t-1) var3(t-1) var4(t-1) var5(t-1) var6(t-1) \
1 0.129779 0.352941 0.245902 0.527273 0.666667 0.002290
2 0.148893 0.367647 0.245902 0.527273 0.666667 0.003811
3 0.159960 0.426471 0.229508 0.545454 0.666667 0.005332
4 0.182093 0.485294 0.229508 0.563637 0.666667 0.008391
5 0.138833 0.485294 0.229508 0.563637 0.666667 0.009912
var7(t-1) var8(t-1) var1(t)
1 0.000000 0.0 0.148893
2 0.000000 0.0 0.159960
3 0.000000 0.0 0.182093
4 0.037037 0.0 0.138833
5 0.074074 0.0 0.109658
3.2 构造模型
在这一节,我们将构造LSTM模型。
模型构建部分:
1)参数理解:LSTM常见的参数为:units, input_shape(samples, timesteps, input_dim)
https://blog.csdn.net/jiangpeng59/article/details/77646186
units:是指每个cell输出时的维度,本质上为每个cell中隐藏层的节点数量;
input_shape:是指数据的输入形状。
samples:样本的数量;
timesteps:每个样本的状态序列个数;
input_dim:每个状态下的特征数;
例如:假如我们输入有100个句子,每个句子都由5个单词组成,而每个单词用64维的词向量表示,那么samples=100,timesteps=5,input_dim=64。
return_sequences:True 每一个lstm单元均输出hidden layer;false:只有最后一个lstm单元输出hidden layer
return_states:true:输出状态,以供下一个lstm单元使用。,false:不输出 state
2)shift函数:上下移动函数,主要是用来进行错位相加减的操作。
temp['value_shift'] = temp['value'].shift(2)
是将values列向下移动两个单位;
# split into train and test sets
values = reframed.values
n_train_hours = 365 * 24
train = values[:n_train_hours, :]
test = values[n_train_hours:, :]
# split into input and outputs
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
运行上述代码打印训练集和测试集的输入输出格式,其中9K小时数据作训练集,35K小时数据作测试集。
(8760, 1, 8) (8760,) (35039, 1, 8) (35039,) 首先,我们需要将处理后的数据集划分为训练集和测试集。为了加速模型的训练,我们仅利用第一年数据进行训练,然后利用剩下的4年进行评估。
下面的代码将数据集进行划分,然后将训练集和测试集划分为输入和输出变量,最终将输入(X)改造为LSTM的输入格式,即[samples,timesteps,features]。
#!/usr/bin/env python
# _*_ UTF-8 _*_
import pandas as pd
from sklearn.preprocessing import LabelEncoder,MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import matplotlib.pyplot as pyplot
from numpy import concatenate
from math import sqrt
# 给定输入、输出序列的长度,它可以自动地将时间序列数据转型为适用于监督学习的数据
# https://blog.csdn.net/u012735708/article/details/82769711
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
# n_vars为列数,此处为8
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
# 它的返回值只有一个, 即转型后适用于监督学习的DataFrame
return agg
# load dataset
dataset = pd.read_csv('pollution.csv', header=0, index_col=0)
values = dataset.values
# LabelEncoder是对不连续的数字或文本编号。
encoder = LabelEncoder()
values[:, 4] = encoder.fit_transform(values[:, 4])
# ensure all data is float
values = values.astype('float32')
# 数据归一化:此时已经去掉时间值,第一列为污染指数PM2.5:
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
# 将数据规整成为可以放进神经网络的dataframe。
reframed = series_to_supervised(scaled, 1, 1)
# drop columns we don't want to predict
# reframed一共有16列,去除10——16列:经过这一变化,
# 数据集的最后一行表示下一刻空气的污染程度。第一行表示这一刻空气的污染程度
# 模型通过对前八行的数据,即这一刻的数据,预测第九行,即下一刻的污染程度。
reframed.drop(reframed.columns[[9, 10, 11, 12, 13, 14, 15]], axis=1, inplace=True)
# 整理好所需要的数据:
# split into train and test sets
values = reframed.values
n_train_hours = 365 * 24
train = values[:n_train_hours, :]
test = values[n_train_hours:, :]
# 取所有行,区分最后一列:[:, :-1]:不取最后一列;[:, -1]获取最后一列
# 经过上面的处理之后形成了新的数列,然后整理出y值
# X是前8行,Y是第9行。
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
# design network
model = Sequential()
# 50为units,是指每个cell中隐藏层结构的参数数量,即经过一个cell之后,数据的维度变为50。
# 假如我们输入有100个句子,每个句子都由5个单词组成,而每个单词用64维的词向量表示。
# 那么samples=100,timesteps=5,input_dim=64,
# 可以简单地理解timesteps就是输入序列的长度。
# input_shape:输入形状为(1,8)
# model.add(Bidirectional(LSTM(50, return_sequences=True),
# input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
# fit network
history = model.fit(train_X,train_y,epochs=50,batch_size=72,validation_data=(test_X, test_y),
verbose=2,shuffle=False)
model.save('air_analysis.model')
# plot history
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
# 显示图例:
pyplot.legend()
pyplot.show()
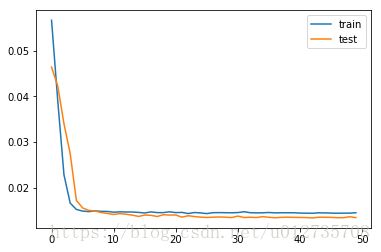
3.3、预测效果:模型构建完成之后可以通过测试来预测效果,inverse_transform的作用是实现计算值与实际值之间的转换,方便后面误差计算。
# make a prediction
# 1、测试集是处理之后的数据:新的数据在输入模型之前需要进行一系列同上的操作,
# 所以需要实现数据的预处理模型,将其整理为一个对应的方法。
# 2、将整理好的数据放入模型中处理:
yhat = model.predict(test_X)
test_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))
print(test_X)
# invert scaling for forecast concatenate:数据拼接
inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1)
print(inv_yhat)
# 3、是将标准化后的数据转换为原始数据:
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:,0]
# invert scaling for actual
inv_y = scaler.inverse_transform(test_X)
inv_y = inv_y[:,0]
# calculate RMSE:均方根误差
rmse = sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
3.4模型调用:模型构建完成后,需要在一定的场合中应用,可以新起一个文件,导入刚才保存的文件,调用开始预测
#!/usr/bin/env python
# _*_ UTF-8 _*_
from sklearn.preprocessing import LabelEncoder,MinMaxScaler
import tensorflow as tf
import pandas as pd
from numpy import concatenate
if __name__ == '__main__':
model = tf.keras.models.load_model('air_analysis.model')
dataset = pd.read_csv('forecast.csv', header=0, index_col=0)
# 数据预处理:
values = dataset.values
# LabelEncoder是对不连续的数字或文本编号。
encoder = LabelEncoder()
values[:, 4] = encoder.fit_transform(values[:, 4])
# ensure all data is float
values = values.astype('float32')
# 数据归一化:此时已经去掉时间值,第一列为污染指数PM2.5:
scaler = MinMaxScaler(feature_range=(0, 1))
values = scaler.fit_transform(values)
train_X = values.reshape((values.shape[0], 1, values.shape[1]))
# 数据预测:
yhat = model.predict(train_X)
# 数据还原:
test_X = train_X.reshape((train_X.shape[0], train_X.shape[2]))
# invert scaling for forecast concatenate:数据拼接
inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1)
# 3、是将标准化后的数据转换为原始数据:
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:, 0]
print(inv_yhat)