TensorFlow2.0笔记18:过拟合介绍以及解决方法+补充: 实现GPU按需分配!
| 过拟合介绍以及解决方法+补充: 实现GPU按需分配! |
文章目录
- 一、过拟合与欠拟合
- 1.1、欠拟合Underfitting
- 1.2、过拟合Overfitting
- 1.3、总结
- 二、交叉验证
- 2.1、如何检测过拟合
- 2.2、K-fold cross validation交叉验证
- 三、Regularization
- 3.1、第一种添加正则化的方式
- 3.2、第二种添加正则化的方式,更加灵活一点!
- 四、动量与学习率
- 4.1、动量优化侧略
- 4.2、学习率衰减策略
- 五、Early Stopping和Dropout
- 5.1、Early Stopping策略
- 5.2、Dropout策略
- 六、补充知识:实现GPU按需分配!
- 六、需要全套课程视频+PPT+代码资源可以私聊我!
- 文章推荐
一、过拟合与欠拟合
1.1、欠拟合Underfitting
训练的时候accuracy和训练的loss都不是很好的。就是accuracy一直上升不去,并且loss也一直下降不了。测试的时候效果也是不好。
1.2、过拟合Overfitting
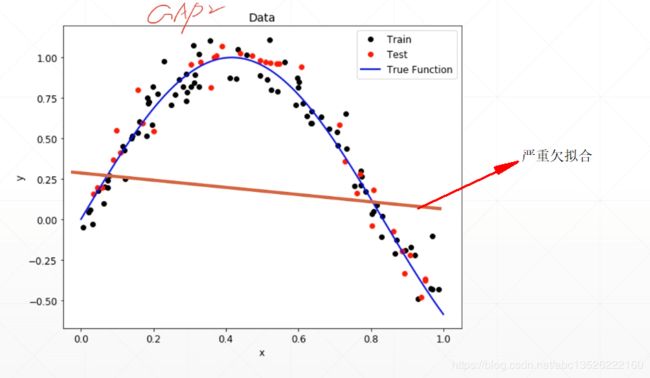
训练的时候特别好,它会尝试接近每个样本点。测试的时候效果不好。这里我们可以换成另外一个词汇generalization performance,当我们的overfitting严重的时候,generalization performance(泛化能力)特别的差。这种情况就是我们特别不想看到的。
例如下面的图片显示,蓝色的线条比较圆滑能表示出整个真实的分布情况。但是另外一个颜色的线条它除了比蓝色的线条更光滑以外,它还慢慢的接近每个点,尽力穿过每一个点,这种情况就是过分的把噪声都包含进来了,看最后边缘的情况,它甚至到下面来了。这样的话,我们训练着训练着它为了让你的loss值更低,它就尝试把每一点的loss值降低,它会逼近每一个样本点,会使得你的训练情况特别特别的好,但是测试的时候会特别的不好。

1.3、总结
左边简单的模型就是欠拟合,中间为真实的分布情况,右边复杂的模型就是是过拟合情况!

现实生活中更多的是过拟合的情况,因为我们现在计算机的计算能力变得更强了,我们能优化的网络会变得非常非常的深,非常非常的宽,这样很容易网络的表达能力超过现在模型的能力(一般指的是:在给定有限数量数据集的模型能力),如果数据集足够多的的话,可能就不会overfitting了。如果数据集有限的话,因为包含了噪声在里面,这样的话很容易过拟合。
- 我们需要解决2个问题:①如何检测过拟合;②如何减少过拟合。
二、交叉验证
下面介绍通过Train, Validation, Test, Splitting可以检测出是不是过拟合的情况!
2.1、如何检测过拟合
- 我们把
Dataset划分为Training Set和Test Set;通过划分以后,我们首先在Training Set做一个Training,它就会学习这个Trainingdataset,因为Trainingdataset和Testdataset都来自同一个数据集,所以它们的真实分布是一样的,当我们在Traingdataset学到一个分布以后,我们要检测它是不是过拟合,我们在Test的时候也做一个accuracy和loss的检测,我们发现它在Trainingdataset表现非常好,但是在Testdataset表现非常不好,这种情况说明是过拟合了。

Dataset划分为Training Set和Test Set;
import tensorflow as tf
from tensorflow.python.keras import datasets
# 数据预处理,仅仅是类型的转换。 [-1~1]
def preprocess(x, y):
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x, y
(x, y), (x_val, y_val) = datasets.mnist.load_data()
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(60000).batch(100)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db = db.map(preprocess).batch(100)
- 严格来说:我们把
Dataset划分为Training Set,Validation Set和Test Set;Validation部分用来做模型参数的挑选。Test做最后的性能的检测!

Dataset划分为Training Set,Validation Set和Test Set;具体如何实现呢?- 我们通过数据集拿到的是2个的划分,默认做的是2个部分的划分,或者我们做自己的数据集的话,我们拿到的是所有的一个图片(一个划分),这里介绍一下2个划分如何变为3个呢?就是我们把原来大的一个
Training dataset做一个切割,通过tf.split()实现!
import tensorflow as tf
from tensorflow.python.keras.api._v2.keras import datasets
# 数据预处理,仅仅是类型的转换。 [-1~1]
def preprocess(x, y):
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x, y
# 默认是对dataset做2个划分!
(x, y), (x_test, y_test) = datasets.mnist.load_data()
# 我们把原来的Training dataset做一个切割,
x_train, x_val = tf.split(x, num_or_size_splits=[50000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[50000, 10000])
# Training部分
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(preprocess).shuffle(50000).batch(100)
# validation部分
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db.map(preprocess).shuffle(10000).batch(100)
# Test部分
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_val = db.map(preprocess).batch(100)
2.2、K-fold cross validation交叉验证

- 实现:对也每个epoch都需要做一个从新的划分!


三、Regularization
上一节介绍了如何检测过拟合,这节课介绍如何(防止)减少过拟合。如何防止过拟合,一般有下面一些主流的做法!

- 我们先简单回顾一下,对于一个二分类问题,它的
cross-entory loss

- 从一个直观的角度来解释一下


3.1、第一种添加正则化的方式

3.2、第二种添加正则化的方式,更加灵活一点!

for step, (x, y) in enumerate(db):
with tf.GradientTape() as tape:
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits = True))
#################################### 正则化项 ################################################
loss_regularization = []
for p in network.trainable_variables:
loss_regularization.append(tf.nn.l2_loss(p))
loss_regularization = tf.reduce_sum(tf.stack(loss_regularization))
#############################################################################################
loss = loss + 0.0001 * loss_regularization
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
四、动量与学习率
4.1、动量优化侧略
上一节介绍了regularization正则化,它是防止过拟合非常有效的手段,应用的非常广泛。下面补充一些小技巧动量和学习率衰减,这2个大家不自觉的使用!
momentum(动量):它是来自物理学上的一个概念,它叫做惯性,例如:你要滑雪的时候,往前冲的时候,你冲进一个小坑里,想停下来,你发现自己停不下来,你发现你能跳进一个大坑里面去。learning rate decay(学习率衰减)。

- 直观的感受,没有动量!

- 直观的感受,有动量!


4.2、学习率衰减策略


五、Early Stopping和Dropout
5.1、Early Stopping策略

- 怎样去
Early Stopping?

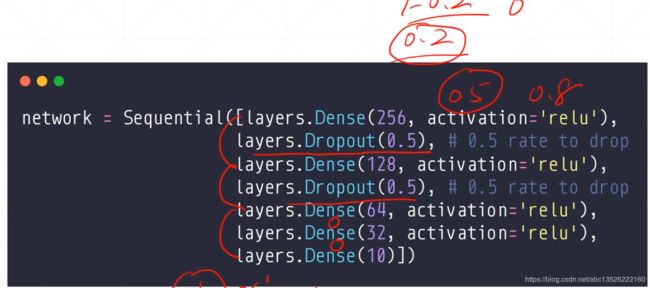
5.2、Dropout策略
Dropout其实就是:它的假设就是learning less to learn better!我们学习的时候Regularization迫使你的W参数逼近于0,迫使W的复杂度降低!Dropout也是,它迫使你学习的时候不需要全部使用W的参数,它是要求你W有效的数量接近于越小越好!
它和Regularization不一样,Regularization迫使你的范数接近于0,Dropout是迫使你Traning的时候使用的Connection数量非常的少,合适一点。怎么实现呢?
- 我们对每个
Connection或者说对于每个W有这样一个额外的属性叫做probability,也就是在前向传播的过程中你有一定的probability,每个权值W有一定的probability暂时输出为0的状态,它并不是把weight的值赋为0;而是你得到这样一个新的值p= wx=0暂时赋值为0(链接断掉)!

- 我们看看加不加
Dropout的对比,最明显的区别,加上Dropout是减少过拟合的一种有效手段,它本身是把有效的参数量给减少了,红色是没有加上Dropout策略,很容易出现overfitting,很容易学习到一些噪声,加上Dropout之后会使得你的网络更强,学习的曲线会更加的平滑,不容易出现overfitting;
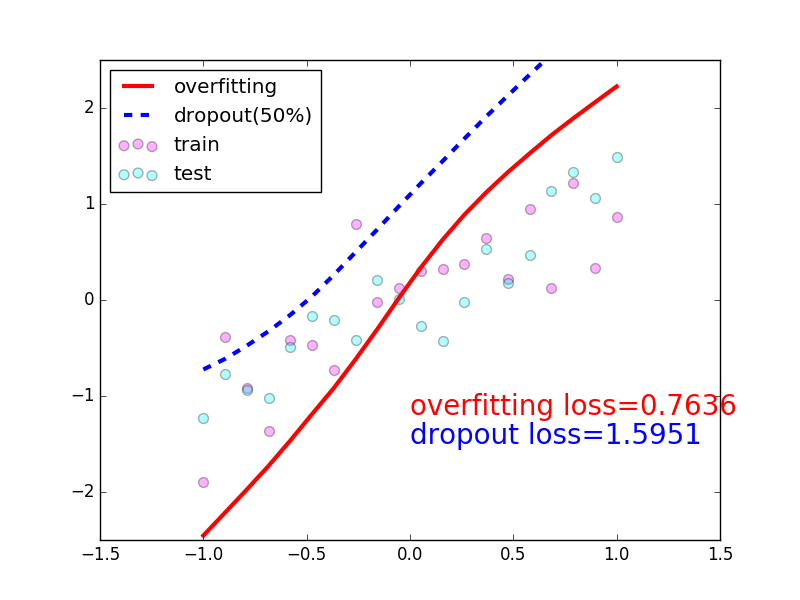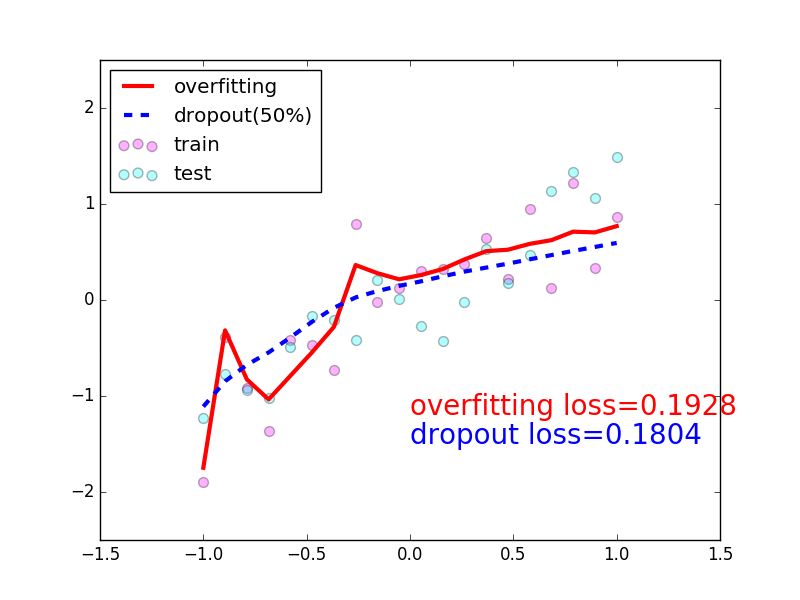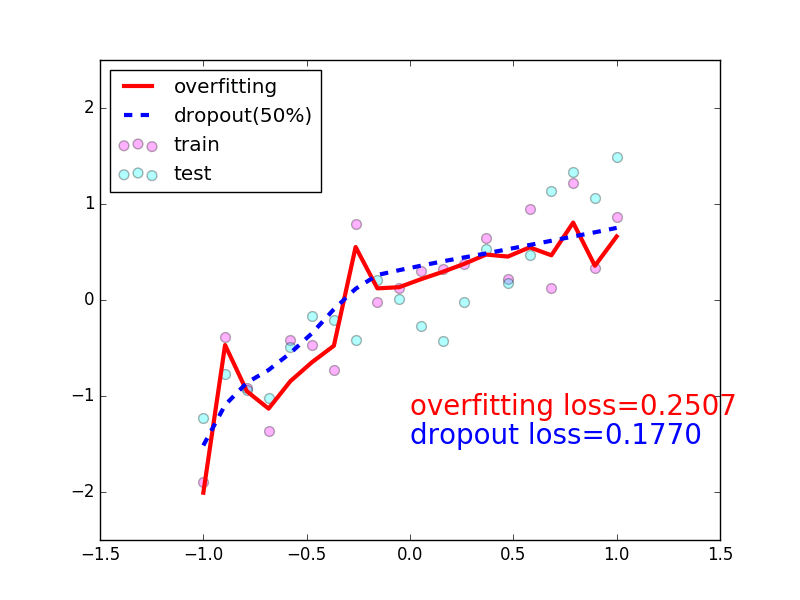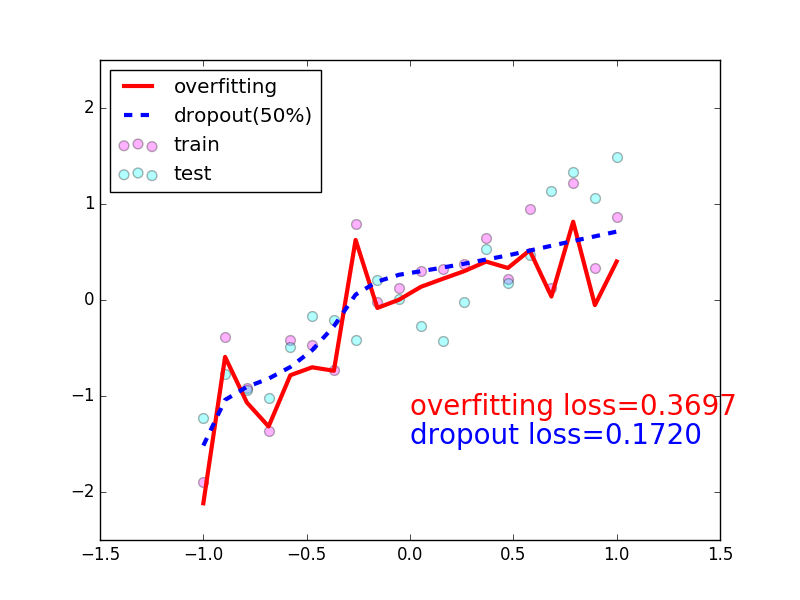
- 动图参考网址
Dropout:https://github.com/MorvanZhou/Pytorch-Tutorial

六、补充知识:实现GPU按需分配!
- 只需要在程序前面设置一下:
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 设置使用哪一块GPU(默认是从0开始)
# 下面就是实现按需分配的代码!
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
六、需要全套课程视频+PPT+代码资源可以私聊我!
- 方式1:CSDN私信我!
- 方式2:QQ邮箱:[email protected]或者直接加我QQ!
文章推荐
- 机器学习:各种优化器Optimizer的总结与比较