Canal增量同步MySQL数到Elasticsearch
Canal增量同步MySQL数到Elasticsearch
调研背景
由于业务发展迅速,店铺商品分库越来越多(目前已有8个MySQL分库)且分库中表数据行数越来越大,大的表已经达到了5KW+,业务需要对商品模糊查询或根据其他字段查询,这些查询的字段很多在数据库中都没有索引,查询命中数据很慢(有些数据根本就查询不出来)且会给数据库库带来很大的压力.所以目前希望将MySQL中的商品数据实时同步到Elasticsearch,利用ES的强大搜索性能来满足我们当前的业务需求.
功能需求
- 首先需要一个稳定的能存储数据达到TB级别的ES集群;
- 其次需要将所有店铺商品分库中已有的所有数据初始化到ES集群;
- 最后后需要实时同步所有店铺商品分库中发生变更的记录到ES集群保证后续数据一致性;
技术需求
- 需要一个能迁移大数据量的方案用于第一次初始化;(后续调研)
- 需要一个能实时同步变更数据的方案保证数据一致性;(即本次调研的中间件Canal)
Canal简介
Canal是阿里巴巴开源的 基于数据库增量日志解析,提供增量数据订阅&消费的数据同步中间件,在阿里内部也有长时间的使用.
GitHub地址: https://github.com/alibaba/canal
Canal简介地址: https://github.com/alibaba/canal/wiki/Introduction
工作原理
mysql主备复制实现

1.master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);从上层来看,复制分成三步:
2.slave将master的binary log events拷贝到它的中继日志(relay log);
3.slave重做中继日志中的事件,将改变反映它自己的数据。
canal的工作原理
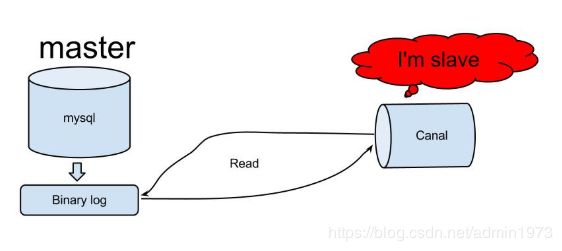
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议原理相对比较简单:
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
架构

server代表一个canal运行实例,对应于一个jvm;说明:
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
MySQL Binlog
- mysql的binlog是多文件存储,定位一个LogEvent需要通过binlog filename + binlog position,进行定位;
- mysql的binlog数据格式,按照生成的方式,主要分为:statement-based、row-based、mixed。
- 目前canal支持所有模式的增量订阅(但配合同步时,因为statement只有sql,没有数据,无法获取原始的变更日志,所以一般建议为ROW模式)
EventParser设计
整个parser过程大致可分为几步:
Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
Connection建立链接,发送BINLOG_DUMP指令
// 0. write command number
// 1. write 4 bytes bin-log position to start at
// 2. write 2 bytes bin-log flags
// 3. write 4 bytes server id of the slave
// 4. write bin-log file name
Mysql开始推送Binaly Log
// 补充字段名字,字段类型,主键信息,unsigned类型处理接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
存储成功后,定时记录Binaly Log位置.

EventSink设计
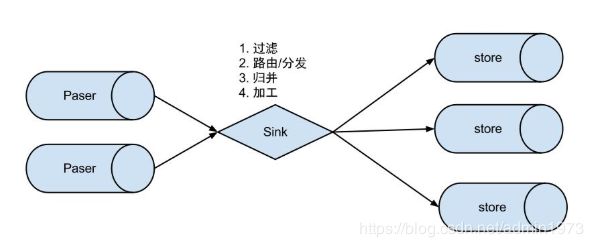
说明:
1.数据过滤:支持通配符的过滤模式,表名,字段内容等
2.数据路由/分发:解决1:n (1个parser对应多个store的模式)
3.数据归并:解决n:1 (多个parser对应1个store)
4.数据加工:在进入store之前进行额外的处理,比如join
数据1:n业务:
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注
数据n:1业务:
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.
EventStore设计
1. 目前实现了Memory内存模式,本地file存储,mixed混合模式;
2. 借鉴了Disruptor的RingBuffer的实现思路;
RingBuffer设计:
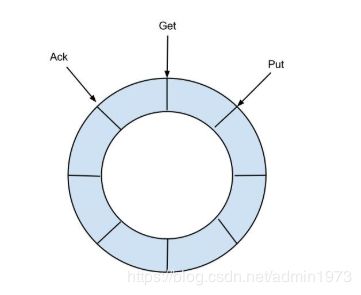
Put : Sink模块进行数据存储的最后一次写入位置定义了3个cursor
Get : 数据订阅获取的最后一次提取位置
Ack : 数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
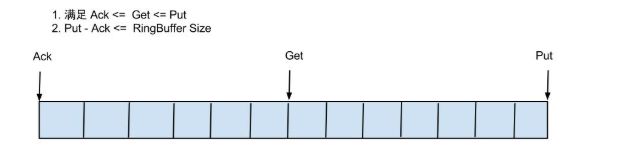
Put/Get/Ack cursor用于递增,采用long型存储实现说明:
buffer的get操作,通过取余或者与操作。(与操作:cusor & (size - 1) , size需要为2的指数,效率比较高)
Instance设计
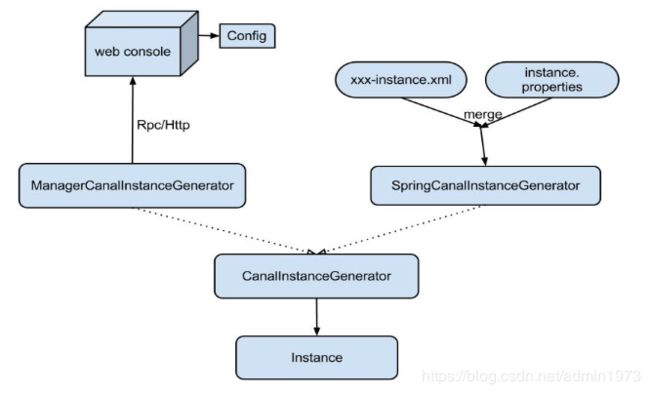
抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:instance代表了一个实际运行的数据队列,包括了EventPaser,EventSink,EventStore等组件。
manager方式: 和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用)
spring方式:基于spring xml + properties进行定义,构建spring配置.
Server设计
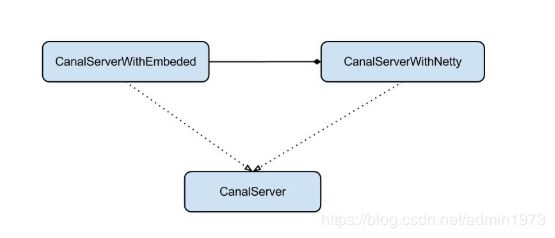
Embeded : 对latency和可用性都有比较高的要求,自己又能hold住分布式的相关技术(比如failover)server代表了一个canal的运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式) / Netty(网络访问)的两种实现
Netty : 基于netty封装了一层网络协议,由canal server保证其可用性,采用的pull模型,当然latency会稍微打点折扣,不过这个也视情况而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠拢,push在数据量大的时候会有一些问题)
增量订阅/消费设计
get/ack/rollback协议介绍:
Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto
void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)

2.每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取1.每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
3.进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cusor
4.一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha实现:
1.canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
2.canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
Canal Server:整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),可以看下我之前zookeeper的相关文章
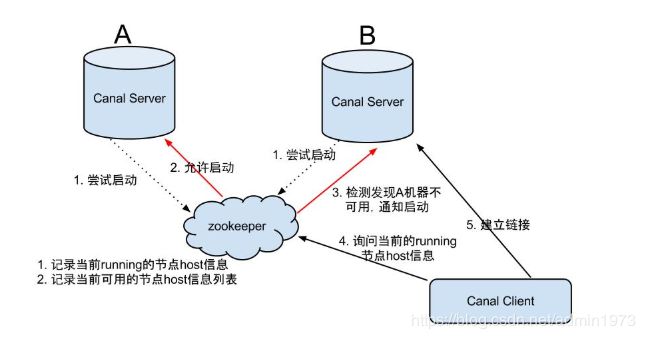
大致步骤:
1.canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
2.创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
3.一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
4.canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
相关模块源码解析可以参考以下博客
canal源码分析简介: http://www.tianshouzhi.com/api/tutorials/canal/380
deployer模块: http://www.tianshouzhi.com/api/tutorials/canal/381
server模块: http://www.tianshouzhi.com/api/tutorials/canal/382
instance模块: http://www.tianshouzhi.com/api/tutorials/canal/391
store模块: http://www.tianshouzhi.com/api/tutorials/canal/401
filter模块: http://www.tianshouzhi.com/api/tutorials/canal/402
driver模块: http://www.tianshouzhi.com/api/tutorials/canal/403
调研实验
环境:
本地安装了3个MySQL5.7服务;
本地起两个canal server 注册到开发环境zk;
本地起两个canal client 注册到开发环境zk;
开发环境ES.
配置&开发:
MySQL开启binlog(ROW);
canal server 创建3个instance 伪装成一个destination,且将读取binlog文件的位置信息保存到zk中;
canal client监听destination,client是在canal提供的client的基础上扩展开发的,将从server接收到的message解析出字段名称和对应的值存入ES;(此处使用自定义开发而不是使用官方的canal-adapter.elasticsearch是因为我们需要自己解压二进制数据然后在存入ES)
验证:
- 在三个MySQL服务中分别创建表shop_item_text(与网店中表结构一致),切随机添加几条数据,在ES中都能查询到,且与在MySQL中添加的数据一致;
- 随机在三个MySQL中修改数据,然后观察ES中的数据也是一致的;
- 删除MySQL中的数据,ES中的数据也被删除;
- 人为结束当前在线的canal server,再随机修改数据,几秒会后ES中也可以看到被修改的结果;
- 随后又把杀掉了的那个canal server再启起来,然后再杀掉当前在线的server,再随机修改数据,几秒会后ES中也会看到被修改的结果;
- 人为杀掉其中当前在线client,再随机修改数据,几秒会后ES中也可以看到被修改的结果;
- 随后又把杀掉了的那个client再启起来,然后再杀掉当前在线的client,再随机修改数据,几秒会后ES中也会看到被修改的结果;
此处没有性能上的测试,canal性能可以参考官方测试结果https://github.com/alibaba/canal/wiki/Performance
调研结论
- Canal server/client支持HA,可以用于增量同步MySQL binlog到ES;
- 由于我们商品描述/基本信息是压缩之后存的BLOB类型,需要在client接收到时解压, 所以我们需要在官方提供的client基础上自行开发.
- 店铺商品同步方式:MySQL一个表在ES中建一个索引,所有分库中相同表名的数据存在同一个索引上,
MySQL数据库中一条记录在ES中创建一个文档;
- 因我们所有表的主键ID是采用雪花算法生成,故在全局所有分库所有表都是唯一的,所以采用主键ID作为ES中文档的_id用于ES做删除(即当在MySQL中执行delete语句时).
雪花算法参考: https://tech.meituan.com/2017/04/21/mt-leaf.html
- 当前只调研了canal 可以用于增量同步MySQL数据到ES,但是ES存储架构设计还需要调研,怎样的前期架构设计可以满足现在以及以后数据量剧增的需求.
关于数据全量同步到ES可以参考此博客:
https://blog.csdn.net/admin1973/article/details/96100877
自己扩展的canal-client(仅供参考):
https://github.com/canglang1973/canal_elasticsearch_client