四. 走向世界之巅——快速排序
你可能会以为归并排序是最强的算法了,其实不然。回想一下,归并的时间效率虽然高,但空间效率仍然有可以改进的空间,人类仍然不满足,仍然孜孜不倦追求更好,更快和更强,于是便有了快速排序,这一神一样的算法以各种面目出现在各种编程语言中,最著名的就是C语言中的qsort了,Java也用它来排序基本类型。快速排序被称为20世纪最伟大的10大算法之一,它们是:
- 蒙特卡洛方法
- 单纯形法
- Krylov子空间迭代法
- 矩阵计算的分解方法
- 优化的Fortran编译器
- 计算矩阵特征值的QR算法
- 快速排序算法
- 快速傅立叶变换
- 整数关系探测算法
- 快速多极算法
所以今天,我们要来了解一下这个伟大算法的基本思想,以及数十年来无数牛人对她的研究和改进。
4.1 基本思想
快速排序的基本思想是这样的:对一个含有N个元素的序列arr,我们在序列中找到一个界标j,然后对序列进行分区,把不大于arr[j]的元素放在j的左边,把不小于arr[j]的元素放在j的右边,然后再递归地对arr[0..j-1]和arr[j+1..N-1]重复上述分区过程,如图4-1所示。这里有两个关键的点要注意把握,首先该输入序列要进行均匀的随机洗牌,从概率上保证其运行效率,因此快速排序是一种随机化算法;其次,就像归并排序的关键在于归并一样,快速排序的关键在于分区的过程,它看似简单,但实现的时候对边界的检查要小心仔细,否则容易出错。后面我们将看到,围绕这个分区人们给出了各种各样的应用和改进,它是这个算法最出彩的地方。



4.2 算法和性能分析
我们先来搞懂分区的工作原理。如下所示,我们以a[lo]为分区界标v,索引i从左往右走,索引j从右往左走,一直走到i所在位置的值不小于v,且j所在位置的值不大于v,这样的两个值是逆序的,对它们进行一次交换,当i和j相遇后循环即停止,此时j指向第一个不大于v的元素,将它与a[lo]交换,就得到了分区好的序列,最后分区方法返回新的界标索引j即可,图4-2给出了分区前、分区中和分区后的演示。排序的过程其实挺简单,排序前先对序列进行一次随机洗牌,使用(Knuth Shuffle),然后进行排序,排序的过程是先分区取得界标j,然后递归排序a[lo..j-1]和a[j+1..hi]即可。图4-3给出快速排序算法的一个完成的演示。有科学家对快速排序进行过分析,在最好情况下,快速排序效率为O(NlgN),最坏情况下为O(N^2),但是,通过随机洗牌,我们能够保证快速排序算法在绝大多数情况下对含有N个不同元素序列的运行效率为O(NlgN),而那极少数情况发生的概率比你中五百万大奖的概率还要低。
快速排序的平均效率能够达到1.39NlgN,比归并排序只高了39%,但实际应用中却更快——因为快速排序移动的元素更少,快速排序是真正的就地排序算法,它不需要额外开辟大小为N的临时空间,因此空间效率比归并排序要好,但是它却不是一种稳定的算法,有关几种算法运行效率的经验值如图4-4所示。
private static int partition(Comparable[] a, int lo, int hi) {
int i = lo;
int j = hi + 1;
Comparable v = a[lo];
while (true) {
// find item on lo to swap
while (less(a[++i], v))
if (i == hi) break;
// find item on hi to swap
while (less(v, a[--j]))
if (j == lo) break; // redundant since a[lo] acts as sentinel
// check if pointers cross
if (i >= j) break;
exch(a, i, j);
}
// put partitioning item v at a[j]
exch(a, lo, j);
// now, a[lo .. j-1] <= a[j] <= a[j+1 .. hi]
return j;
}
public static void sort(Comparable[] a) {
StdRandom.shuffle(a);
sort(a, 0, a.length - 1);
}
// quicksort the subarray from a[lo] to a[hi]
private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) return;
int j = partition(a, lo, hi);
sort(a, lo, j-1);
sort(a, j+1, hi);
assert isSorted(a, lo, hi);
}

4.3 镜鉴快速排序——求第k大的元素
在实际工作中,我们常常会碰到这样的问题,即求一个序列中最大的元素或者最小的元素,这种问题实际上是顺序统计学上求“第k大的元素”的一种特例。这种问题一眼看上去好像很简单:对序列排序然后取第k个元素即可。但这样一来解决问题的效率就变成了O(NlgN),还能不能更快些呢?当然能!这里可以借鉴partition的思想编写一个quick-select算法,该算法每次都使用partition取得分区界标j,此时j左边的元素都比它小,右边的元素都比它大,如果j == k,说明我们找到了,返回a[k];否则,如果j < k,下一次我们就在j的右边找(a[j+1..hi]),如果j > k,说明k在j的左边,下一次我们就在j的左边找(a[lo..j-1])。算法像二叉查找一样,每次都将范围减半,因此效率为N+N/2+N/4+...+1,约2N次比较,那么我们通过这样的方法就能在线性时间内确定第k大的元素是多少。
4.4 对快速排序的研究和改进
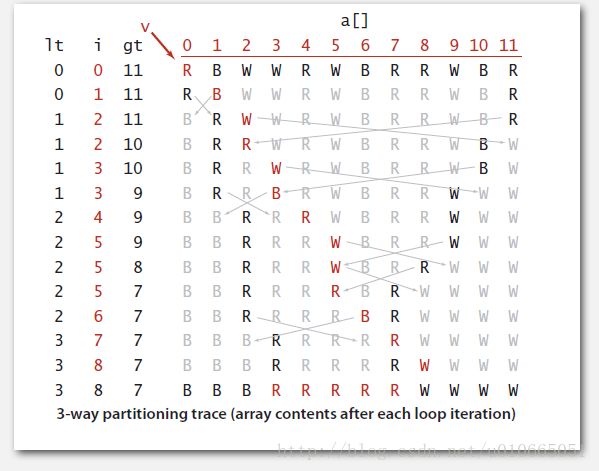
就像上面提到的,快速排序算法在诞生后由于其卓越的性能成为各大编程语言标准库中不可或缺的一员,一切看上去都是那么的完美。直到1991年的一天AT&T Bell实验室的两位科学家Allan Wilks和Rick Becker意外地发现,原本运行几秒钟就能给出结果的qsort()跑了好几分钟才返回,这让他们很无语,于是决定深入研究,他们发现了上述基本算法存在的问题——若序列中出现重复值,那么上述算法的效率将降低到O(N^2)。实际生活中排序的序列具有大量重复值是很常见的,极端情况下,如果序列中记录的值都是相同的,那么上述快速排序的分区处理就会变得非常的糟糕——因为它将所有的元素甩到了左边,然后不断重复,如图4-5所示。理想情况下,当遇到与分区界标相同的值时,我们应该停下来。更进一步说,如果能将序列分区为三个部分:“左边都是小于界标的元素,中间都是等于界标的元素,右边都是大于界标的元素”,那就更好了。于是科学家们对快速排序进行了改进,便有了3-way partitioning。图4-6给出了三路分区的一个大概的示意图。可以看到,算法执行完成后a[lo..lt-1]都是比v小的元素;a[lt..gt]都是等于v的元素;a[gt+1..hi]都是大于v的元素。


private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) return;
int lt = lo, gt = hi;
Comparable v = a[lo];
int i = lo;
while (i <= gt) {
int cmp = a[i].compareTo(v);
if (cmp < 0) exch(a, lt++, i++);
else if (cmp > 0) exch(a, i, gt--);
else i++;
}
// a[lo..lt-1] < v = a[lt..gt] < a[gt+1..hi].
sort(a, lo, lt-1);
sort(a, gt+1, hi);
assert isSorted(a, lo, hi);
}
一开始先将lt和gt分别初始化为lo和hi,分区界标v初始化为a[lo],然后i从左往右遍历,每次都与v作比较。1)若a[i] < v,说明这玩意儿应该在a[lo..lt-1]的范围内,所以交换a[lt]和a[i],然后lt和i分别自增一个单位,这相当于是把a[i]甩到序列的左边;2)若a[i] > v,说明这玩意儿应该在a[gt+1..hi]的范围内,于是交换a[i]和a[gt],然后gt自减一个单位,因为交换后a[i]就是原来的a[gt],还没做比较,所以i不能动;最后,若a[i] == v,则只增加i。若i > gt了,说明序列已经分区完毕,此时循环结束,然后再递归地对a[lo..lt-1]和a[gt+1..hi]进行排序(实质上是重复这一分区过程)即可。图4-7是这一分区过程的展示,经过复杂的数学分析发现,对大部分实际情况而言,这样的三路快速排序都能达到线性时间的运行效率,当序列中只有常量个不同的值,其他值都重复时,该算法的效率能做到O(N),这真是一个了不起的进步。
人们并没有停下追求卓越的脚步,在上面提到过的那篇著名的论文“Engineering a Sort Function”中,Bentley和McIlroy针对实际工程中使用的排序算法做了一系列的优化。算法的基本思想仍然采用快速排序,但是对于规模较小的子序列,使用了插入排序,分区的方法则采用了上面介绍的3-way partitioning,但针对不同情况做了不同处理:对较小序列取中间位置作为分区界标;对于中等序列则使用“median of 3”方法;对于较大的序列则使用更高端的“Tukey's ninther”方法。这样以来,原本理论化的,“纯粹”的快速排序算法就被改的面目全非了,但同时我们也收获了一份能够在遇到问题时马上就能用的高效算法。有的时候没有选择就是最好的选择,这就是为什么你可以在大多数编程语言中轻轻松松使用sort()或者stable()就能对序列进行排序或稳定排序,而不是在那里绞尽脑汁地纠结到底该选哪种排序算法比较好的原因。从这里可以得到一点点启发,如果我们是标准库的使用者,那么我们只关心结果(速度快不快,结果对不对),不在乎中间过程;但如果我们是标准库的设计者,就要注意避免让使用者去纠结,去选择,就应该做到高效实用,哪怕它是一个“大杂烩”一样的排序算法。
时至今日,只要你去阅读编程语言排序标准库的源代码,你几乎都能在注释中看到这篇算法的身影,比如图4-8展示的Go语言sort包中的源代码。不到万不得已或者情况特殊,完全没有必要自己造轮子,因为你造出来的轮子未必有人家的好。那这是否就代表我们无所作为了呢?其实不是的,我们应该想想怎样利用好别人的东西做好自己的事情。比如Java语言使用Comparator接口来实现对同一记录的多种排序,Go语言的sort包却没有提供这样的功能,那么我们怎样优雅地实现这一功能呢?下面这段代码是我在Go语言文档的启发下自己编写的实现。仍然是采用回调函数的方法,但是我们定义一个multiKeySorter的结构,它包含待排序的序列coll和比较函数lesser,然后我们定义Len(),Swap()和Less()函数,使得该结构满足sort包的接口,在Less()函数中我们通过回调lesser()函数来执行排序。这里一个比较巧妙的地方是将形如“func(o1, o2 interface{}) bool”的函数定义为By类型,然后在这个函数类型上定义“成员函数”Sort(),在Sort()函数中强制转换传入的任何同型构函数以及待排序序列,并使用它们就地定义一个multiKeySorter结构变量然后进行排序。
// multiKeySorter is a kind of Sortable used for sorting according to different keys
// One can write different lesser functions for a user-defined type and call
// By(*lesser*).Sort(*coll*) to sort the collection
type multiKeySorter struct {
coll interface{}
lesser func(o1, o2 interface{}) bool
}
func (mks *multiKeySorter) Len() int {
if reflect.TypeOf(mks.coll).Kind() == reflect.Slice {
slice := reflect.ValueOf(mks.coll)
return slice.Len()
}
panic("passing a non-slice type")
}
func (mks *multiKeySorter) Swap(i, j int) {
if reflect.TypeOf(mks.coll).Kind() == reflect.Slice {
slice := reflect.ValueOf(mks.coll)
temp := reflect.ValueOf(slice.Index(i).Interface())
slice.Index(i).Set(reflect.ValueOf(slice.Index(j).Interface()))
slice.Index(j).Set(temp)
return
}
panic("passing a non-slice type")
}
func (mks *multiKeySorter) Less(i, j int) bool {
if reflect.TypeOf(mks.coll).Kind() == reflect.Slice {
slice := reflect.ValueOf(mks.coll)
return mks.lesser(slice.Index(i).Interface(), slice.Index(j).Interface())
}
panic("passing a non-slice type")
}
// By is a function type for multiple-key sorting
type By func(o1, o2 interface{}) bool
// Sort sorts the slice by lesser func passing in
func (by By) Sort(coll interface{}) {
mks := &multiKeySorter{
coll: coll,
lesser: by,
}
sort.Sort(mks)
}
func TestMultiKeySorter(t *testing.T) {
fmt.Println("====== Multi Key Sorter ======")
planets := []Planet{
{"Mercury", 0.055, 0.4},
{"Venus", 0.815, 0.7},
{"Earth", 1.0, 1.0},
{"Mars", 0.107, 1.5},
}
name := func(o1, o2 interface{}) bool {
p1 := o1.(Planet)
p2 := o2.(Planet)
return strings.ToLower(p1.name) < strings.ToLower(p2.name)
}
distance := func(o1, o2 interface{}) bool {
p1 := o1.(Planet)
p2 := o2.(Planet)
return p1.dist < p2.dist
}
mass := func(o1, o2 interface{}) bool {
p1 := o1.(Planet)
p2 := o2.(Planet)
return p1.mass < p2.mass
}
sorter.By(name).Sort(planets)
fmt.Println("By name: ", planets)
sorter.By(distance).Sort(planets)
fmt.Println("By distance: ", planets)
sorter.By(mass).Sort(planets)
fmt.Println("By mass: ", planets)
}
五. 为“排序”而生——优先级队列
5.1 什么是优先级队列
在之前的算法分析学习笔记中,我们曾经介绍过两种数据结构——栈和队列。回想一下,栈执行的操作是“先入后出”,它删除的元素是总是最近插入的那个;而队列执行的操作是“先入先出”,它删除的元素总是最先放进去的那个。这里我们要介绍的优先级队列,采用了一种截然不同的方式来删除元素——根据优先级的大小。这种优先级是人为定义的,这样就增加了使用的灵活性,优先级队列也分为两种:最大优先级队列每次删除的是优先级最高的那个元素,而最小优先级队列每次删除的是优先级最低的那个元素。这样的数据结构与我们之前接触的排序算法有区别又有联系:它们之间的区别是,排序算法是将整个序列重新排列有序之后再进行处理,而优先级队列并不要求整体有序,但它每次删除的元素总是从小到大或从大到小,使得优先级队列中的元素总是按序处理;它们之间的联系是,优先级队列内部使用的一种称为“堆”的数据结构直接导致了“堆排序”算法的诞生,这个后面会有详细的讲解。
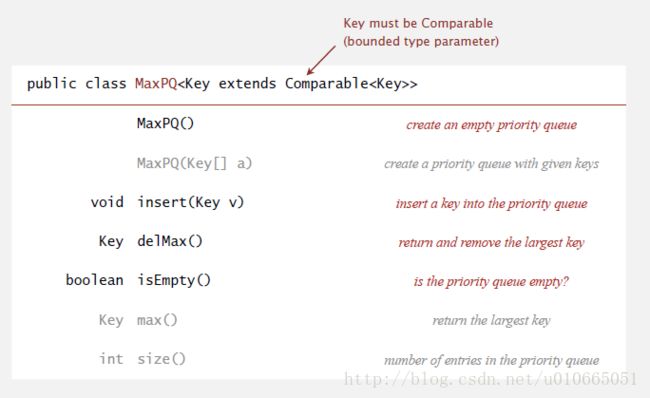
优先级队列不负众望,应用广泛。在数据压缩(哈夫曼编码)、图搜索(Dijkstra算法和Prim算法)、人工智能(A*搜索)、操作系统(负载均衡和中断处理)和垃圾邮件过滤(贝叶斯分类器)中都扮演重要角色。一个最常见的应用就是海量数据处理:从N个记录中获取最大的(或者最小的)M个记录,一般N很大M很小,没有足够的内存来存放这海量的N个记录。比如谷歌每天都会产生海量的搜索日志,要从这些数据中找出搜索频率最高的10大关键词,就是优先级队列的典型应用场景。v_July_v哥在他的“结构之法,算法之道”系列博客中有一篇博文叫《教你如何迅速秒杀掉:99%的海量数据面试题》对这一课题有精彩的研究。图5-1展示了最大优先级队列的API,其中黑色部分就是优先级队列实现的最主要接口,对称地,最小优先级队列只要将delMax()改为delMin()即可。
5.2 优先级队列的朴素实现
有两种简单的方式可以实现优先级队列——用数组。无序数组的实现在每次插入元素时只简单地将其插入到数组末端,因此效率是O(1),删除元素时则需要遍历数组求最大值,因此效率是O(N),取最大元素的效率为O(N);有序数组的实现在每次插入元素时都将元素插入到适当的位置使得数组有序,使用类似插入排序的方法,因此效率是O(N),删除时直接删除数组末端的元素,因此效率是O(1),取最大元素的效率为O(1)。同样是使用数组,我们还可以实现效率更高的优先级队列,使得上述所有的操作都能在O(logN)时间内完成,这就是鼎鼎大名的——二叉堆。
5.3 叫我“二叉堆”!
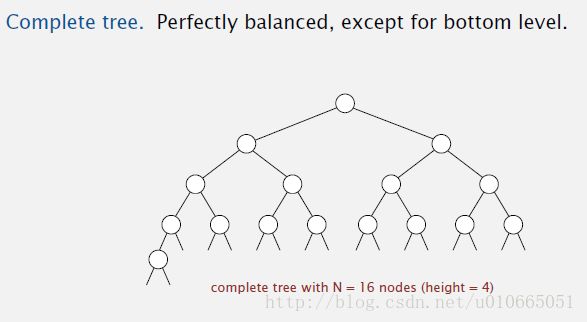
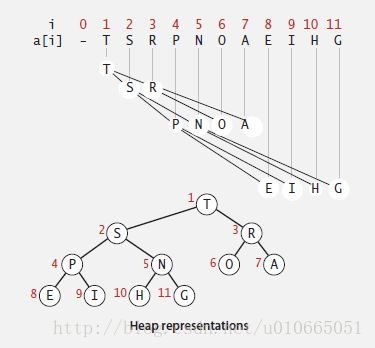
要理解二叉堆,首先要理解二叉树,二叉树是一种递归结构,它要么为空(什么都没有,空空如也),要么就是一个结点,该结点有左右两个link分别指向一棵二叉树。完全二叉树又是一种特殊的二叉树,除了最底层可以例外,其他层的结点都填满了,也就是说,如果我们一层一层,从左到右地创建二叉树,那么就能创造出一棵完全二叉树,它是近乎完美平衡的,如图5-2所示。只要是树型结构,我们都要注意有关树的高度的结论,因为在树的世界里又瘦又高并不是一种讨人喜欢的身材,又矮又胖才是人见人爱的对象,树越矮越胖,从根结点走到叶子结点的路径就越短。可以通过数学归纳法进行证明,一棵具有N个结点的完全二叉树其高度为floor(lgN),因此lgN的时间内就能从根结点走到叶子结点。而二叉堆其实就是一棵“堆有序”的完全二叉树,它分为两种——最大堆和最小堆。最大堆中每一个结点都大于等于它的两个子节点,根节点是最大的;而最小堆中每一个结点都小于等于它的两个子节点,根节点是最小的。对完全二叉树,我们可以从根节点开始从左到右,从上到下地按序标记为1,2,3……正是因为这一特殊性,所以我们可以用数组来表示二叉堆,其中下标为0的位置空出来,从下标为1的位置开始按层次存放树的节点,如图5-3所示。对完全二叉树要牢记父节点和子节点的计算公式,对于节点k,它的父节点为k/2,两个子节点分别为2k和2k+1,且对于一棵有N个节点的完全二叉树只有左半部分(k <= N/2)节点有子节点,这在图5-3中同样可以得到验证。下面我们以最大堆为例介绍一下相关的核心算法。
5.3.1 “上浮”和“下沉”算法
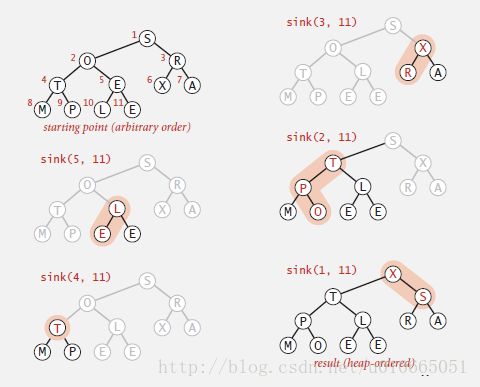
在一个最大堆中,如果一个节点k的值突然变得比它的父节点k/2大了,那么这棵二叉堆就被破坏了,恢复的办法就是让这个节点与它的父节点发生交换,此时节点k相当于“上浮”了一层,然后我们再判断,如果仍然大于父节点,那么就再“上浮”一层,这个过程一直持续到根节点,或目标节点不再比其父节点大为止;同样地,如果 一个节点k的值突然小于了它的(其中一个或两个)子节点,那么二叉堆的秩序仍然被破坏了,此时恢复的办法正好反过来——让节点k与其子节点2k和2k+1进行比较,然后与较大的那个做交换,此时节点k相当于“下沉”了一层,这个过程一直持续到叶子节点,或目标节点不再比其任何子节点小为止。下面的几行代码展示了这两个过程,特别要注意循环的条件,对于swim(),首先要判断k > 1,这是k/2有效的条件;对于sink(),只需要处理左半部分(2k <= N)即可,因为右半部分都是叶子节点,处理的过程中,我们用j来获取两个子节点中较大的那个,一旦发现节点k不再小于j即停止。
private void swim(int k) {
while (k > 1 && less(k/2, k)) {
exch(k, k/2);
k = k/2;
}
}
private void sink(int k) {
while (2*k <= N) {
int j = 2*k;
if (j < N && less(j, j+1)) j++;
if (!less(k, j)) break;
exch(k, j);
k = j;
}
}
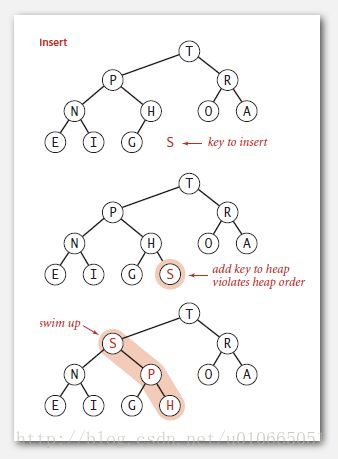
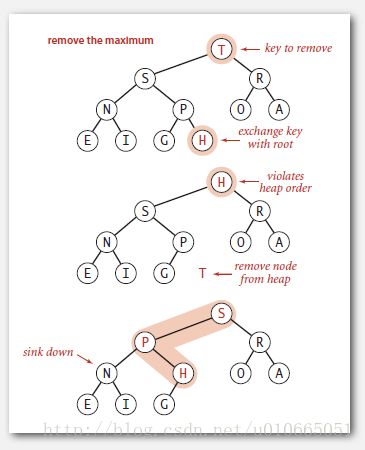
以上两个过程被用在优先级队列的插入和删除过程中,插入元素时,我们先将元素插入到数组末尾,然后调用swim()进行可能的上浮操作,将新节点调整到合适的位置;删除时,我们删除根节点(最大的元素),然后用数组最末尾的元素填补根节点的空缺,最后调用sink()进行可能的下沉操作,恢复堆有序。两种操作都是在根节点到某一叶子节点的路径上操作,所以效率都是O(lgN),图5-4和图5-5分别演示了这一过程。下面的代码展示了最大堆的插入和删除。
public void insert(Key x) {
// double size of array if necessary
if (N >= pq.length - 1) resize(2 * pq.length);
// add x, and percolate it up to maintain heap invariant
pq[++N] = x;
swim(N);
assert isMaxHeap();
}
public Key delMax() {
if (isEmpty()) throw new NoSuchElementException("Priority queue underflow");
Key max = pq[1];
exch(1, N--);
sink(1);
pq[N+1] = null; // to avoid loiterig and help with garbage collection
if ((N > 0) && (N == (pq.length - 1) / 4)) resize(pq.length / 2);
assert isMaxHeap();
return max;
}
如果要实现最小优先级队列(最小堆),那其实很简单,只要把less()函数改为greater()函数即可,这样就变成了小的元素“上浮”,大的元素“下沉”,根节点存储的是最小的元素。有感于此,我们给出了一个统一的Go语言实现,比起Java实现来说它有两个优势:首先,Go语言的“切片”类型相当于动态数组,我们不用考虑对数组重新调整大小的问题;其次,通过传入比较函数我们可以用同一套代码生成最大优先级队列和最小优先级队列;它的缺点是需要使用者自己去记住创建的是最大优先级队列还是最小优先级队列。
package cntr
import (
"fmt"
)
type PQueue struct {
keys []interface{}
length int
compare func(interface{}, interface{}) bool
}
func NewPQ(cmp func(interface{}, interface{}) bool) *PQueue {
// arr[0] not use
arr := make([]interface{}, 1)
arr[0] = 0
return &PQueue{
keys: arr,
compare: cmp,
}
}
func (pq *PQueue) Insert(v interface{}) {
pq.keys = append(pq.keys, v)
pq.length++
pq.swim(pq.length)
}
func (pq *PQueue) swim(k int) {
for k > 1 && pq.compare(pq.keys[k/2], pq.keys[k]) {
pq.keys[k/2], pq.keys[k] = pq.keys[k], pq.keys[k/2]
k = k / 2
}
}
func (pq *PQueue) pq() interface{} {
if pq.Empty() {
panic(fmt.Sprintf("queue is empty"))
}
return pq.keys[1]
}
func (pq *PQueue) PrintOut() {
fmt.Println(pq.keys[1:])
}
func (pq *PQueue) Del() interface{} {
if pq.Empty() {
panic(fmt.Sprintf("Trying to delete an empty queue"))
}
ret := pq.keys[1]
pq.keys[1] = pq.keys[pq.length]
pq.keys = pq.keys[:pq.length]
pq.length--
pq.sink(1)
return ret
}
func (pq *PQueue) sink(k int) {
for 2*k <= pq.length {
j := 2 * k
if j < pq.length && pq.compare(pq.keys[j], pq.keys[j+1]) {
j++
}
if !pq.compare(pq.keys[k], pq.keys[j]) {
break
}
pq.keys[k], pq.keys[j] = pq.keys[j], pq.keys[k]
k = j
}
}
func (pq *PQueue) IsHeapified() bool {
k := 1
for 2*k <= pq.length {
j := 2 * k
if pq.compare(pq.keys[k], pq.keys[j]) || (j < pq.length && pq.compare(pq.keys[k], pq.keys[j+1])) {
return false
}
k++
}
return true
}
func (pq *PQueue) Empty() bool {
return pq.length == 0
}
func (pq *PQueue) Size() int {
return pq.length
}
5.4 又一个神一样的存在——堆排序
通过二叉堆,我们又诞生了一个伟大的算法——堆排序。我个人认为,最经典的排序算法,非归并排序,快速排序和堆排序莫属,对她们算法性能的改进倾注了无数科学家的心血,她们解决问题的思想被大量地借鉴用于解决其他问题,她们在无数计算问题中发挥的基础作用深刻影响了科技的发展。堆排序是一种就地排序算法,不需要占用额外的数组空间,因此它的空间效率比归并排序要好,与此同时堆排序最坏情况下的时间效率是O(NlgN),这点她又比快速排序强,后者只能保证平均情况。因此堆排序也是一个最优的比较排序算法,只可惜它并不是稳定的,而且由于移动的距离比较大,它对缓存并不友好。
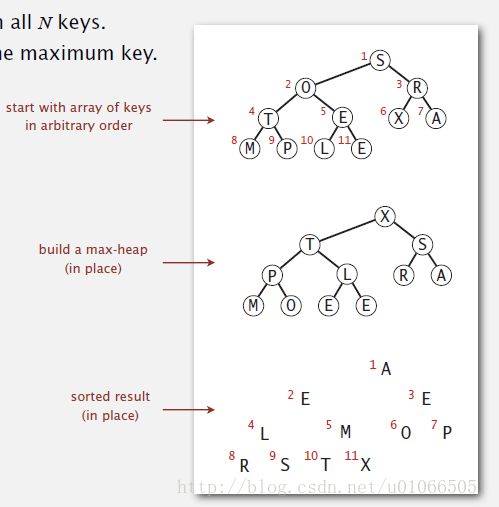
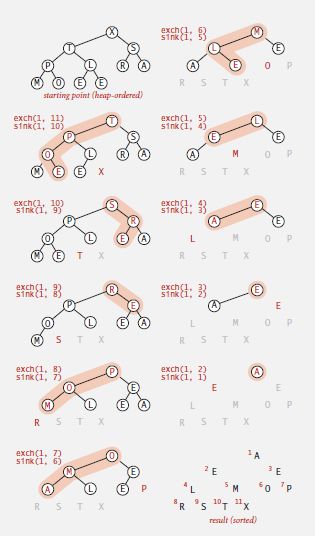
堆排序的思想很容易解释,首先该算法会在输入序列的基础上重建最大堆,然后不停地删除最大值,将其与数组末尾元素交换,直到处理完全部序列,如图5-6所示。下面的代码展示了对一个整型切片进行堆排序的Go语言实现。HeapSort()中的第一个for循环在数组上建堆,它是一个自底向上的过程。我们将数组中每一个元素看作以它为根节点的子二叉堆,首先我们认为所有大小为1的子堆(叶子节点)都是堆有序的,之前我们提到过堆的数组表示有个性质,即数组右半部分都是叶子节点,因此我们从N/2的位置开始从右往左遍历,调用下沉函数sink()建堆,当k = 1时执行最后一次建堆并结束循环,此时整个数组构建成了一个二叉堆,如图5-7所示。紧接着在第二个循环中,我们不断地将堆中第一个元素(最大值)放到最后一个元素的位置上,最后一个元素放到第一个位置上,递减N的值(此时堆的大小减一),然后调用sink()恢复堆有序,因为算法每次都将最大的元素放到最后一个位置并递减堆的大小,因此该算法执行完成后数组就是有序的,如图5-8所示。有一个处理细节要引起注意,因为我们排序的数组是从下标0开始的,而最大堆是从下标1开始的,所以在实现lesser()函数和excher()函数的时候要注意在下标上做减一处理,其他地方不变。
func HeapSort(arr []int) {
N := len(arr)
for k := N / 2; k >= 1; k-- {
sink(arr, k, N)
}
for N > 1 {
excher(arr, 1, N)
N--
sink(arr, 1, N)
}
}
func sink(arr []int, k, N int) {
for 2*k <= N {
j := 2 * k
if j < N && lesser(arr, j, j+1) {
j++
}
if !lesser(arr, k, j) {
break
}
excher(arr, k, j)
k = j
}
}
func lesser(arr []int, i, j int) bool {
return arr[i-1] < arr[j-1]
}
func excher(arr []int, i, j int) {
arr[i-1], arr[j-1] = arr[j-1], arr[i-1]
}
六. 排序算法的学以致用
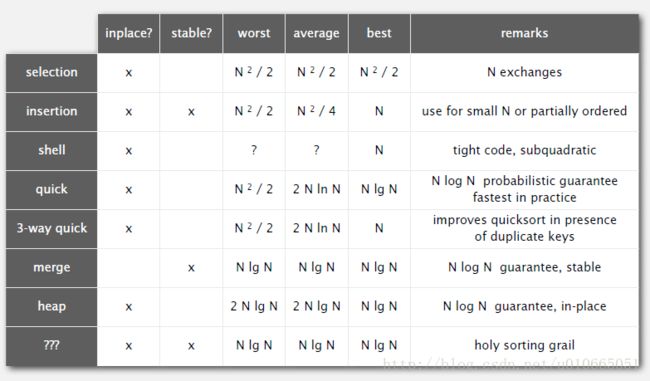


就这样,我们在不多的篇幅里介绍了多种排序算法,从最基础的选择排序,插入排序和Shell排序,到经典的归并排序,快速排序,再到为排序而生的优先级队列,以及堆排序。世界上存在有上百种千奇百怪的排序算法,这里能够介绍到的算法只是沧海之一粟,但是了解游戏规则,理解它们的思想对于学习其他算法以及解决实际问题都是很有帮助的,图6-1以表格的形式归纳了我们学习过的七种算法以及它们具有的性质。下面,我们就抛砖引玉,来看看排序算法的应用。
6.1 学以致用之一:归约思想
课本上介绍了一种叫做“归约”(Reductions)的重要思想——其实它就是我们常说的“举一反三”啦!怎么说呢?归约就是用解决一个问题的算法去解决另一个问题。如果一个问题中的对象只有在有序时才能很容易地解决,那么我们就说我们将这个问题“归约”为一个排序问题来解决。例如在第一篇学习笔记中介绍的二叉搜索算法,它能够在对数时间内查找目标元素,但前提是该序列是有序的。下面我们来看看都有哪些问题可以归约为一个排序问题。
6.1.1 重复元素
序列中有多少元素是重复的?序列中哪个元素出现的最频繁?怎样去除队列中的重复元素?这些问题当序列是无序时很难回答,而当序列有序时就简单多了,因为排序后重复的元素都会靠在一起。这类问题是算法面试题中的常客,如果没有限制,我们还可以用额外的存储空间,比如一个散列表去统计,这样无需序列有序;若题目要求不准使用额外的空间时,就需要对序列先进行排序然后再处理。
6.1.2 逆序数
就像上面提到过的那样,逆序数是指一个序列中的有序对(a, b)的个数,其中a > b。仔细想一想,我们排序的过程就是逐步消除逆序数的过程,因此稍加改造就能在排序的过程中求得序列的逆序数。一个经典的办法是改造归并排序,在归并的过程中若发现左子序列当前元素大于右子序列当前元素,就能根据右子序列元素个数得到逆序,这是一个经典面试题的经典解法。
6.1.3 中位数与顺序统计学
这个也在之前提到过了,在统计学和其他数据处理应用中应用较为广泛。它借鉴了快速排序的分区算法的思想,在不需要完全排序的情况下就能找到第k小的元素,且算法能够在线性时间内运行完毕,然而它是一种随机化的算法——处理之前需要进行一次随机排序,因此该运行效率是平均情况。
6.2 学以致用之二:人工智能问题中的优先级队列
这里要介绍的是优先级队列在人工智能问题中的应用——8 puzzle谜题,问题的完整定义和描述详见http://introcs.cs.princeton.edu/java/assignments/8puzzle.html。这一问题于1870年由Sam Loyd给出:在一个33的格子上有8个方块和1个空缺,这8个方块从1编号到8,我们的任务是利用这个空缺或水平或垂直地移动这些方块,尽量用最少的移动使得它们有序,图6-2展示了一个例子。
这个问题可以利用人工智能中著名的A Search算法进行求解,首先我们定义一个三元组,它由棋盘当前状态board,走到此位置要用的移动数moves,以及之前的状态prev组成。起始状态为(board, 0, NULL),其中board是人为输入的初始状态。我们将起始状态塞入最小优先级队列,每次都取出优先级最小的三元组,然后将它的“邻居们”(所有只移动一步就能达到的棋盘)插入优先级队列(要注意将与之前状态prev相同的情况排除掉),此过程一直持续到弹出的三元组为最终状态,此时我们将根据它以及它的prev指针重建整个步骤序列作为算法的解。有三个关键的问题要解决:1.优先级怎么定义;2.如何判别棋盘走到了最终态;3.如何判别初始状态是可解的;
这里我们有两种方法来定义优先级:Hamming优先级函数和Manhattan优先级函数:前者定义为当前棋盘状态中放错位置的方块数加上从初始状态走到这一状态要用的移动数,直观地看,放错位置的方块数越少该状态就越接近最终状态;后者定义为方块与其最终位置的距离和(包括横向和纵向),加上从初始状态走到这一状态要用的移动数,图6-3展示了这两种优先级函数的计算。因此优先级队列里的三元组都是以这两个函数任意一个的计算值为优先级排列的。不管使用哪一个优先级函数,要从某一初始位置走到最终位置,移动的步数至少是优先级函数的输出值(对Hamming,放错位置的方块至少要移动一步;对Manhattan,放错位置的方块至少要移动曼哈顿距离才能走到最终位置),因此当我们从优先级队列中取出一个三元组时,我们就找到了从初始状态走到这一状态的一系列最小步骤,当Hamming距离或Manhattan距离为0时,此三元组即为最终态。
剩下的最后一个问题就是要搞清楚初始状态是不是可解的,棋盘状态分为两种:一种能够通过移动走到最终态(可解);另一种不能(不可解)但随机交换相邻方块则可解,那么我们就能够在两个棋盘状态上同时运行A* Search算法,一个是初始棋盘,一个是交换了任意相邻方块的棋盘,若后者得解则立即返回前者不可解,若前者得解则构造解的序列(使用堆栈),下面给出的是核心代码,完整实现请参考Solver.java和Board.java
public Solver(Board initial) {
solvable = false;
solutions = null;
M = -1;
MinPQ nq = new MinPQ();
MinPQ tq = new MinPQ();
nq.insert(new SNode(initial));
tq.insert(new SNode(initial.twin()));
while (!nq.isEmpty() && !tq.isEmpty()) {
SNode n = nq.delMin();
SNode t = tq.delMin();
// test if we have reached the goal
if (t.board.manhattan() == 0) break;
if (n.board.manhattan() == 0) {
// rebuild the solutions
solutions = new Stack();
solutions.push(n.board);
solvable = true;
M = n.moves;
SNode prev = n.previous;
while (prev != null) {
solutions.push(prev.board);
M += prev.moves;
prev = prev.previous;
}
break;
}
// putting neighbors into queues
for (Board nbr : n.board.neighbors())
if (n.previous == null || !n.previous.board.equals(nbr))
nq.insert(new SNode(nbr, n.moves + 1, n));
for (Board tbr : t.board.neighbors())
if (t.previous == null || !t.previous.board.equals(tbr))
tq.insert(new SNode(tbr, t.moves + 1, t));
}
}