group by 函数主要用来对数据进行分组,over()函数则是一个“开窗函数”,它更多的是与聚合函数如:sum()、max()、min()、avg()、count()等函数以及排名函数如:row_number()、rank()、dense_rank()、ntile()函数结合使用。
1.group by 函数
原始数据如下,数据表名为hr.employeee
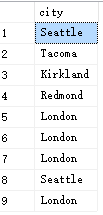
对以上数据按照city字段进行分组,并计算了每组中存在的行数:
select city,count(city)as n from hr.employeee group by city;
分组结果:

根据以上结果,London这个值在原始数据中出现了4次,该组的行数为4。
2.over()函数
一般来说,当使用了group by 进行分组查询,select查询阶段出现的columnlists如果没有出现在group by 后作为分组依据,就必须被包含在聚合函数中。但是往往在书写的时候就会忘记这个限制。over()函数则很好的解决了这个问题,该函数能够实现分组的效果。
原始数据如下(总共有830行):
进行以下查询:
select distinct val,row_number()over(order by val)as rownum from sales.ordervalues

运行结果仍然是830行,但实际该数据是存在5行的重复数据,所以说,明明在select阶段使用distinct取不同值,为何会没作用呢???
T-SQL语言基础这本书是这样解释的:row_number函数是在distinct子句之前处理的,当其为数据分配了唯一的行号后,再处理distinct子句,所以这时不会有任何重复的行。 (还未理解透,distinct是对val做处理,只要val存在重复值就剔除呀,难道不是这样的吗?--因为distinct是对其后的两列数据进行去重的!)
这也说明,在同一select子句中不能同时使用distinct和row_number()函数,因为distinct会失效!!!
要想得到不含重复值的数据,可以进行以下查询:
select val,row_number()over(order by val)as rownum from sales.ordervalues group by val;

这个时候就筛除了5行重复数据。
以下情形值得注意:
--代码1 --分组之后计算每组的行数 select val,count(val)as n from sales.ordervalues group by val;--注意查看分组后val值,这时已经达到去重的效果了 --代码2 --利用over函数达到分组效果,partition by对某列字段分区 select val,count(val)over(partition by val )as num from sales.ordervalues --代码3 --代码2和3进行对比,注意区别 select val,count(val)over(partition by val )as num from sales.ordervalues group by val;
代码1:利用group by 子句进行分组查询,并计算了每组的行数,观察结果发现,group by起到了去重的功效。

代码2:利用over函数达到分组效果,partition by对某列字段分区,并计算分区后每组的行数,这种情况下并没有去重的效果。
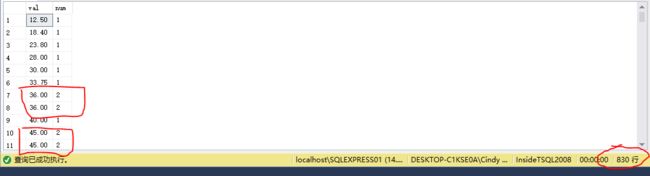
代码3:由于group by 处理顺序优于select,前面说到group by具有去重功效,每组数据只有唯一值!因此再进行over函数计算每组行数只有一个结果。

再来一组查询对比,当在over函数中同时指定partition by 和order by 的字段为同一个时,排序失效:
--按照val降序排列失效!!! select val,count(val)over(partition by val order by val desc )as num from sales.ordervalues; select val,count(val)over(partition by val )as num from sales.ordervalues order by val desc ;

以上按照val降序排列失效的原因在于,partition by 分区后的数据即按照了一定的顺序(升序)排列了,再使用order by 排序就会失效(个人理解):
select val from sales.ordervalues select val from sales.ordervalues group by val;


以上对比查询看到,group by不仅具有去重功效,还有按照升序排列数据的功能(单列数据查询)。