【大数据】开发环境搭建(三):hadoop伪分布式集群环境搭建(下)
(一)hadoop相关文件基本配置
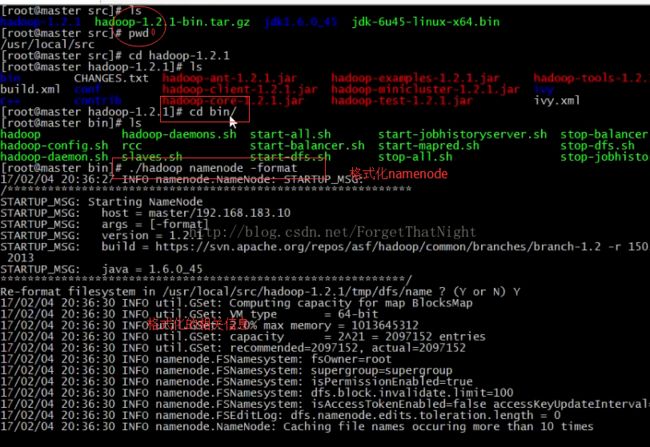
首先进入master的/usr/local/src/,
pwd
ls查看当前目录下的文件,找到hadoop-1.2.1-bin.tar,该文件和java.bin一起放在共享文件夹中的,如果找不到,重新共享文件夹。
首先进行解压该压缩包tar xvzf hadoop-1.2.1-bin.tar,解压过程如图所示
解压完成以后,会在当前目录下产生一个hadoop-1.2.1的文件目录,进入该目录里面,
cd hadoop-1.2.1
ls
然后在当前目录中新增一个tmp目录,用于存放之后的一些临时文件,比如hadoop运行中产生的临时文件,
pwd检查是否还在hadoop目录下
进入配置文件夹cd conf/
ls
找到master进行修改 vim masters,输入master,没有其他内容,以后保存退出
找到slaves进行修改,因为当前从节点只有两个,第一行为slave1,第二行为slave2,没有其他内容
找到core-site.xml进行修改,进行相应的配置,如图,指定临时目录的路径地址,建议把这个模版复制下来

保存退出,cd tmp/,检查tmp是否已经准确创建好了,pwd,并拷贝该目录
然后进入 cd ../conf/
编辑 vim core-site.xml
保存临时文件的路径,并且设置好hdfs的URI
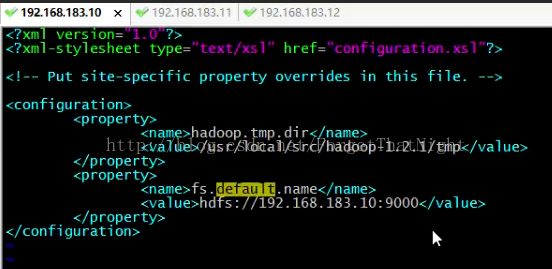
接下来修改 vim mapred-site.xml,主要是修改maprediuce,并且分配9001端口来job.tracker的工作
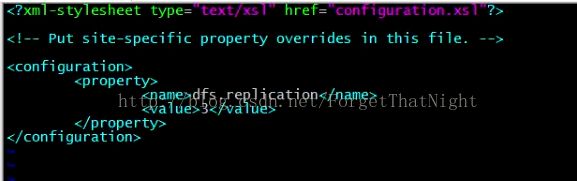
然后修改 vim hdfs-site.xml
首先找到javajdk的安装路径 cd /usr/local/src/jdk1.6.0/
pwd复制该路径
然后再回到conf中继续配置 cd - /usr/local/src/hadoop1.2.1/conf
ls 找到即将要配置的hadoop-env.sh
修改hadoop vim hadoop-env.sh, 到最后一行配置环境变量

查看到现在位置修改类哪些文件 ls -rlt
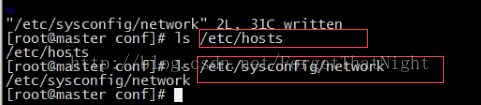
接着进行本地网络配置 vim /etc/hosts/
输入时要确保IP地址和虚拟机名称对应

本地网络配置完成以后,我们要让它生效 使用命令 hostname master可以让master临时生效,但是我们需要的是让它永久性生效
vim /etc/sysconfig/network/
修改hostname字段的value为我们的master
![]()
此时已经完成了两个本地网络配置的修改,通过这两个文件,我们指定了当前机子的hostname以及IP地址和hostname的映射关系
现在已经完成了master的配置,接下来我们需要到/usr/local/src/路径下把其中解压好的hadoop1.2.1远程拷贝到slave1和slave2中。

远程拷贝完成slave1后再以同样的方式拷贝到slave2中,拷贝完成以后,分别进入slave1和slave2中 cd /usr/local/src/ 查看hadoop1.2.1是否已经成功拷贝过来。然后进入到这个目录中来检查一下,
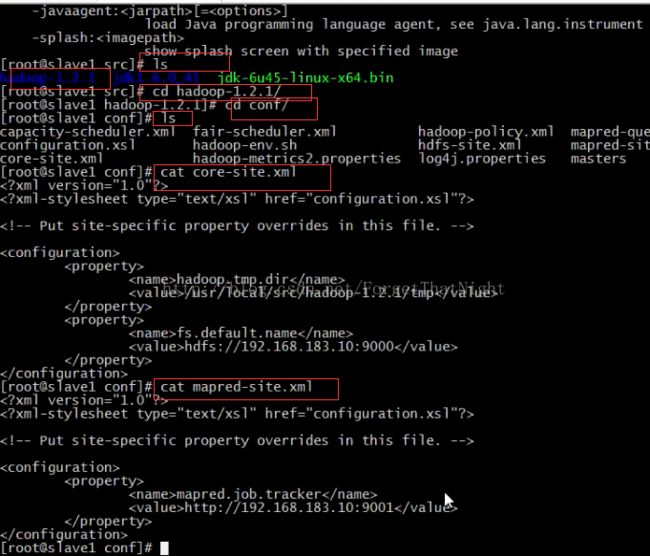
刚刚我们在master中还额外修改了/etc/hosts 和 /etc/sysconfig/network/文件,同样需要配置到slave1和slave2中,这里我们只需要把master中该两个文件的内容复制到即可,注意如图所示中master粘贴以后要改为对应的slave1和slave2

同时,通过本地配置文件已经可以让我们的slave1和slave2的hostname永久性生效,此时我们还需要分别对slave1和slave2进行临时生效,分别输入
hostname slave1 和 hostname2
通过命令hostname 进行检查。
为了防止后来的开发中网络出现问题,可以把master 、slave1和slave2的网络防火墙暂时关闭一下,因为很多原因都可能导致网络传输出现问题,关闭以后可以减少排查选项
/etc/init.d/iptables stop
检查防火墙 iptables -L

如图所示,则表明网络防火墙已经成功关闭。
3台虚拟机分别关闭setenforce 0
![]()
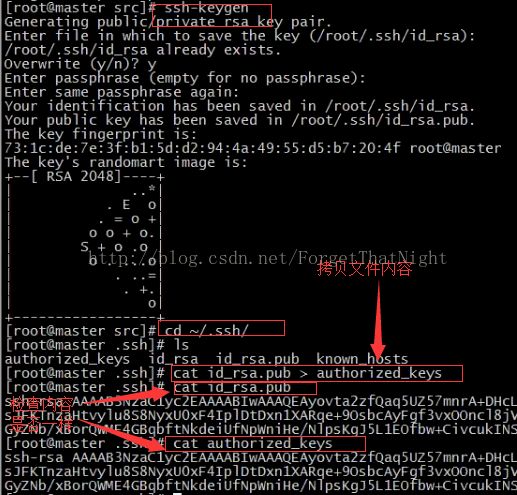
(二)建立每台虚拟机之间的互信关系


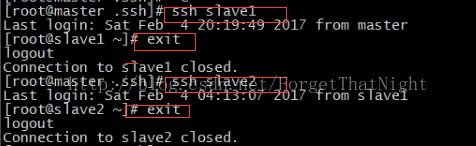
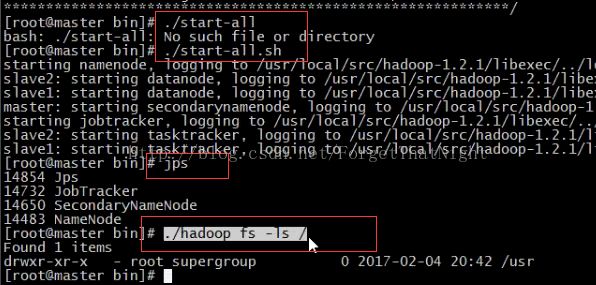
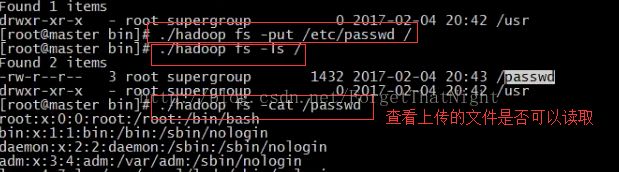
(三)查看hadoop集群是否可以正确启动起来